

对朴素贝叶斯算法原理做展开介绍
描述
在众多机器学习分类算法中,本篇我们提到的朴素贝叶斯模型,和其他绝大多数分类算法都不同,也是很重要的模型之一。

朴素贝叶斯是一个非常直观的模型,在很多领域有广泛的应用,比如早期的文本分类,很多时候会用它作为 baseline 模型,本篇内容我们对朴素贝叶斯算法原理做展开介绍。
1.朴素贝叶斯算法核心思想
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯(Naive Bayes)分类是贝叶斯分类中最简单,也是常见的一种分类方法。
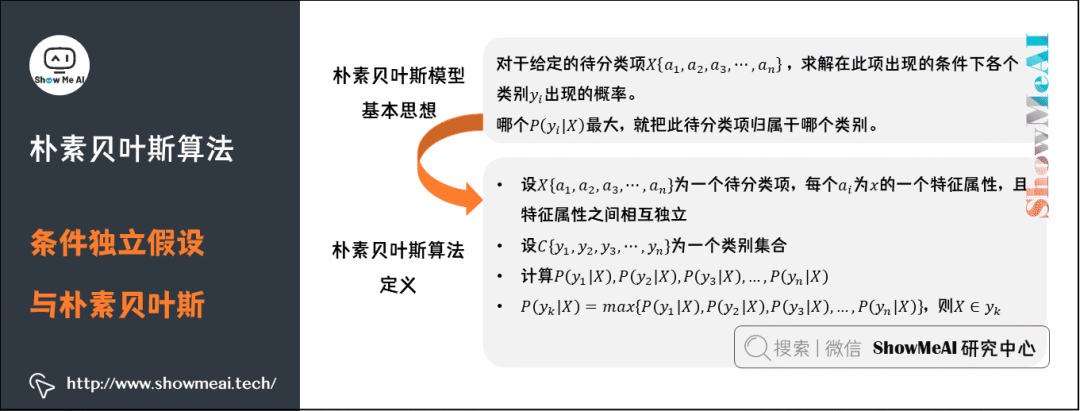
朴素贝叶斯算法的核心思想是通过考虑特征概率来预测分类,即对于给出的待分类样本,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。
举个例子:眼前有100个西瓜,好瓜和坏瓜个数差不多,现在要用这些西瓜来训练一个『坏瓜识别器』,我们要怎么办呢?
一般挑西瓜时通常要『敲一敲』,听听声音,是清脆声、浊响声、还是沉闷声。所以,我们先简单点考虑这个问题,只用敲击的声音来辨别西瓜的好坏。根据经验,敲击声『清脆』说明西瓜还不够熟,敲击声『沉闷』说明西瓜成熟度好,更甜更好吃。

所以,坏西瓜的敲击声是『清脆』的概率更大,好西瓜的敲击声是『沉闷』的概率更大。当然这并不绝对——我们千挑万选地『沉闷』瓜也可能并没熟,这就是噪声了。当然,在实际生活中,除了敲击声,我们还有其他可能特征来帮助判断,例如色泽、跟蒂、品类等。
朴素贝叶斯把类似『敲击声』这样的特征概率化,构成一个『西瓜的品质向量』以及对应的『好瓜/坏瓜标签』,训练出一个标准的『基于统计概率的好坏瓜模型』,这些模型都是各个特征概率构成的。

这样,在面对未知品质的西瓜时,我们迅速获取了特征,分别输入『好瓜模型』和『坏瓜模型』,得到两个概率值。如果『坏瓜模型』输出的概率值大一些,那这个瓜很有可能就是个坏瓜。
2.贝叶斯公式与条件独立假设
贝叶斯定理中很重要的概念是先验概率、后验概率和条件概率。(关于这部分依赖的数学知识,大家可以查看ShowMeAI的文章 图解AI数学基础 | 概率与统计,也可以下载我们的速查手册 AI知识技能速查 | 数学基础-概率统计知识)(链接见文末)。
1)先验概率与后验概率


2)贝叶斯公式
简单来说,贝叶斯定理(Bayes Theorem,也称贝叶斯公式)是基于假设的先验概率、给定假设下观察到不同数据的概率,提供了一种计算后验概率的方法。在人工智能领域,有一些概率型模型会依托于贝叶斯定理,比如我们今天的主角『朴素贝叶斯模型』。
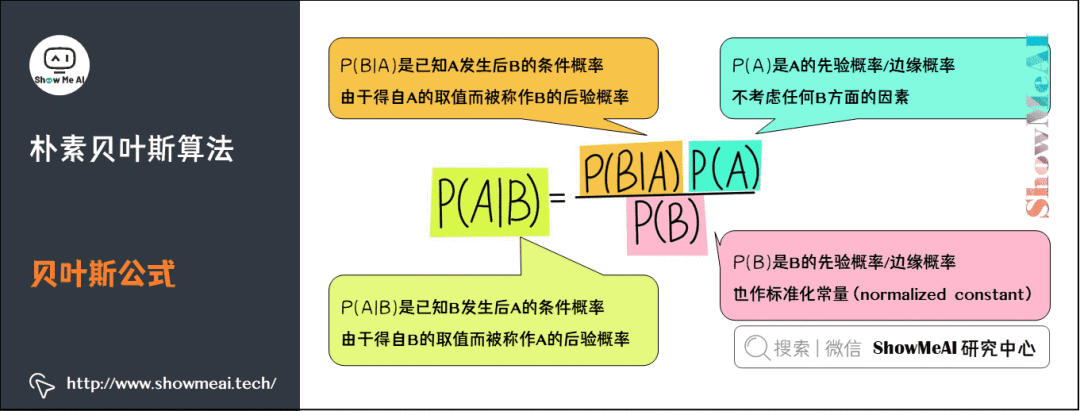

3)条件独立假设与朴素贝叶斯
基于贝叶斯定理的贝叶斯模型是一类简单常用的分类算法。在『假设待分类项的各个属性相互独立』的情况下,构造出来的分类算法就称为朴素的,即朴素贝叶斯算法。
所谓『朴素』,是假定所有输入事件之间是相互独立。进行这个假设是因为独立事件间的概率计算更简单。

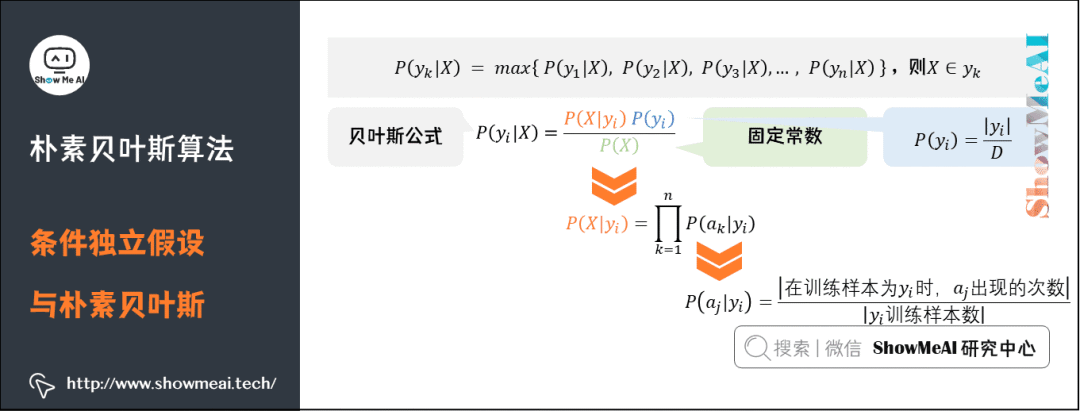
要求出第四项中的后验概率,就需要分别求出在第三项中的各个条件概率,其步骤是:




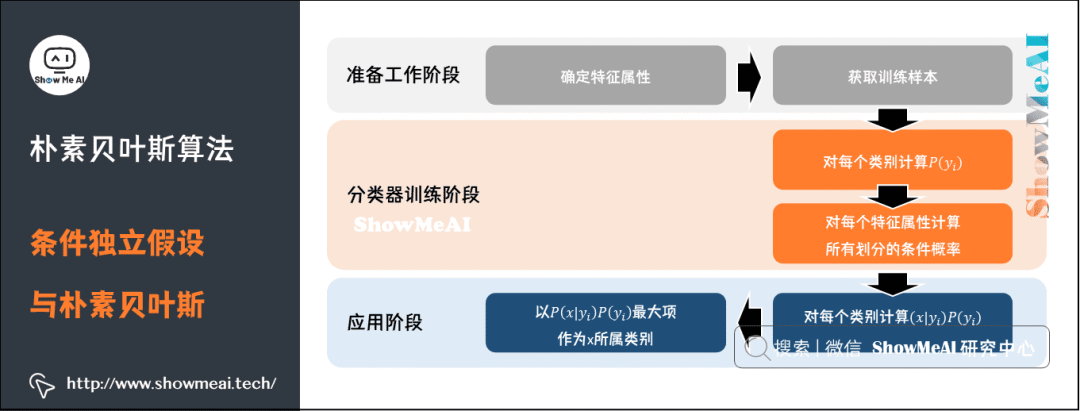
总结一下,朴素贝叶斯模型的分类过程如下流程图所示:
3.伯努利与多项式朴素贝叶斯
1)多项式vs伯努利朴素贝叶斯
大家在一些资料中,会看到『多项式朴素贝叶斯』和『伯努利朴素贝叶斯』这样的细分名称,我们在这里基于文本分类来给大家解释一下:
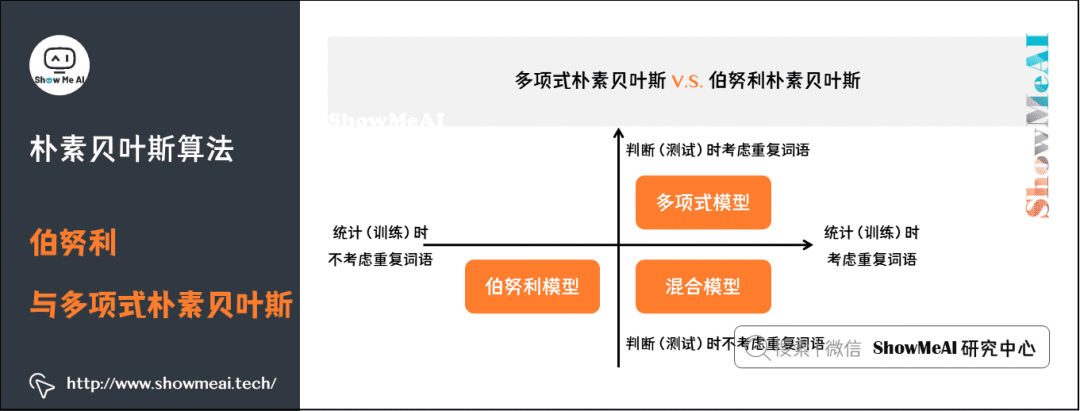

如果直接以单词的频次参与统计计算,那就是多项式朴素贝叶斯的形态。
如果以是否出现(0和1)参与统计计算,就是伯努利朴素贝叶斯的形态。

(1)多项式朴素贝叶斯

(2)伯努利朴素贝叶斯
对应的,在伯努利朴素贝叶斯里,我们假设各个特征在各个类别下是服从n重伯努利分布(二项分布)的,因为伯努利试验仅有两个结果,因此,算法会首先对特征值进行二值化处理(假设二值化的结果为1与0)。

2)朴素贝叶斯与连续值特征
我们发现在之前的概率统计方式,都是基于离散值的。如果遇到连续型变量特征,怎么办呢?
以人的身高,物体的长度为例。一种处理方式是:把它转换成离散型的值。比如:


回到上述例子,如果身高是我们判定人性别(男/女)的特征之一,我们可以假设男性和女性的身高服从正态分布,通过样本计算出身高均值和方差,对应上图中公式就得到正态分布的密度函数。有了密度函数,遇到新的身高值就可以直接代入,算出密度函数的值。
4.平滑处理
1)为什么需要平滑处理
使用朴素贝叶斯,有时候会面临零概率问题。零概率问题,指的是在计算实例的概率时,如果某个量,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。
在文本分类的问题中,当『一个词语没有在训练样本中出现』时,这个词基于公式统计计算得到的条件概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
2)拉普拉斯平滑及依据



审核编辑:刘清
-
机器学习的朴素贝叶斯讲解2019-05-15 1824
-
朴素贝叶斯法的优缺点2019-08-05 2696
-
朴素贝叶斯法的恶意留言过滤2019-08-26 2115
-
常用的分类方法:朴素贝叶斯法2019-11-05 1669
-
朴素贝叶斯过滤邮箱里的垃圾邮件2020-03-18 1308
-
对朴素贝叶斯算法的理解2020-05-15 2414
-
机器学习之朴素贝叶斯应用教程2017-11-25 1629
-
基于概率的常见的分类方法--朴素贝叶斯2018-02-03 6047
-
朴素贝叶斯NB经典案例2018-02-28 1061
-
机器学习之朴素贝叶斯2018-05-29 1240
-
朴素贝叶斯算法详细总结2018-07-01 35890
-
带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树2019-05-06 11835
-
一种改进互信息的加权朴素贝叶斯算法2021-03-16 1345
-
朴素贝叶斯分类 朴素贝叶斯算法的优点2021-10-02 10376
-
PyTorch教程22.9之朴素贝叶斯2023-06-06 860
全部0条评论

快来发表一下你的评论吧 !
