

基于统一语义匹配的通用信息抽取框架USM
描述
介绍
信息提取(Information Extraction,IE)需要提取句子中的实体、关系、事件等,其不同的任务具有多样的抽取目标和异质的机构,因此,传统的方法需要针对特定的任务进行模型设计和数据标注,使得难以推广到新的模式中,极大限制了IE系统的使用。
2022年《Unified Structure Generation for Universal Information Extraction》一文,提出了通用信息提取(UIE)的概念,旨在使用一个通用模型来解决多个信息提取任务,提出了一种Seq2Seq的生成模型,以结构化模式提示器+文本内容作为输出,直接生成结构化抽取语言,最终获取信息提取内容。
然而,由于Seq2Seq的生成模型的黑盒特性,导致无法判断跨任务或跨模式的迁移在什么情况下会成功or失败。因此,本论文提出了统一语义匹配框架(Universal Information Extraction,USM)对各种信息提取任务进行统一建模,明确模型在迁移过程的有效性、健壮性和可解释性。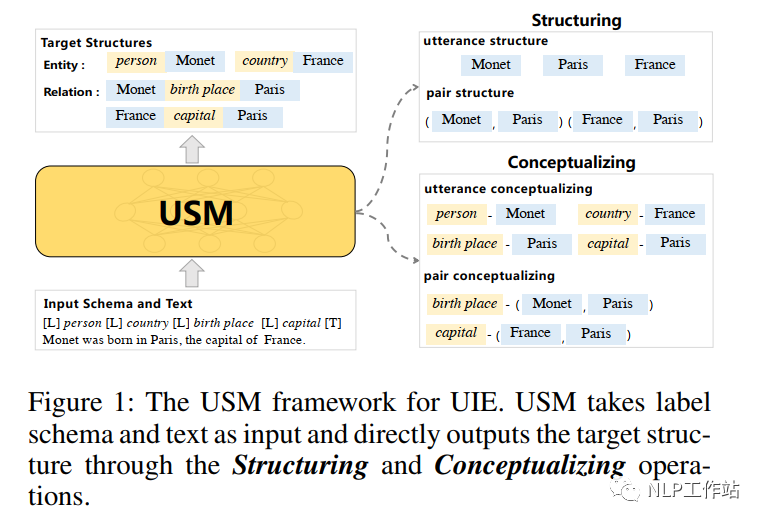
如图1所示,IE任务中多样化的任务和抽取目标,可以解耦为以下两个操作:
(1)Structuring,即结构化,从文本中抽取目标结构中标签未知的基本子结构。例如:抽取“Monet”、“Paris”、“France”等文本或者“ Monet-Paris”、“France-Paris”等文本pair对。
(2) Conceptualizing,即概念化,它将抽取文本和文本pair对与目标语义标签进行对应。例如:“Monet”与“person”标签进行对应,“Monet”-"Paris"与“birth place”标签进行对应。
并且在给定目标抽取模式时,可以通过结构化操作,重新建立抽取目标结构与文本的语义信息;通过概念化操作,将抽取文本或文本pair与目标语义标签进行匹配,完成信息抽取任务。
USM框架基于上述发现的规则,将结构化和概念化转化为一系列有向Token-Linking操作,联合建模文本与模式,统一抽取文本或文本pair,并根据需要可控生成目标结构,实现在不同的目标结构和语义模式之间进行共享抽取的功能。
基于有向Token-Linking的统一语义匹配
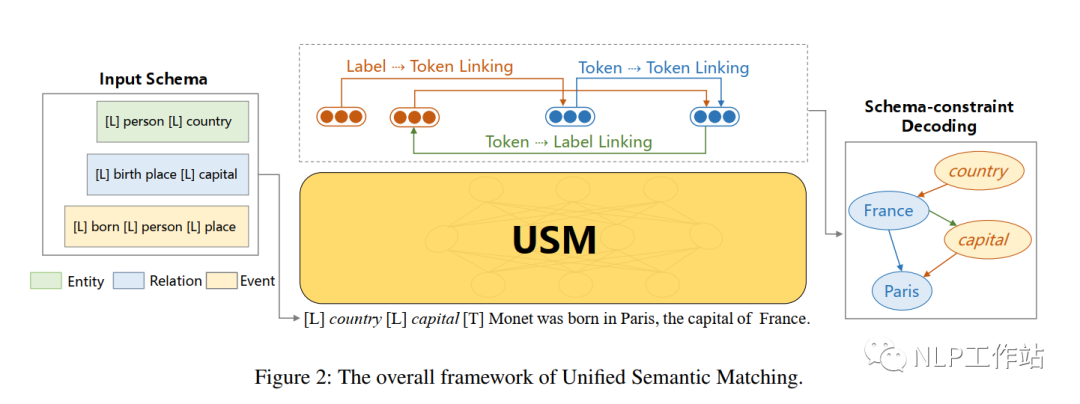
如图2所示,USM框架以任意抽取标签模式和原始文本作为输入,根据给定的模式直接输出结构。
Schema-Text Joint Embedding

Token-Token Linking for Structuring
在得到标签-文本联合上下文嵌入后,USM框架使用Token-Token链接(TTL)操作抽取所有有效的文本片段。
Utterance:输入文本中的一段连续Token序列,例如:实体文本“Monet”、事件触发词“born in”等。如图3所示,通过片段的头尾连接(H2T),抽取一个文本片段。例如,“Monet”是自身到自身,“born in”是“born”到“in”。
Association pair:输入文本中的相关文本pair对,例如,具有主客体关系的“Monet”-“Paris”文本对,具有触发词-要素关系的“born in”-“Paris”文本对。如图3所示,通过头头连接(H2H)和尾尾连接(T2T),抽取文本对。
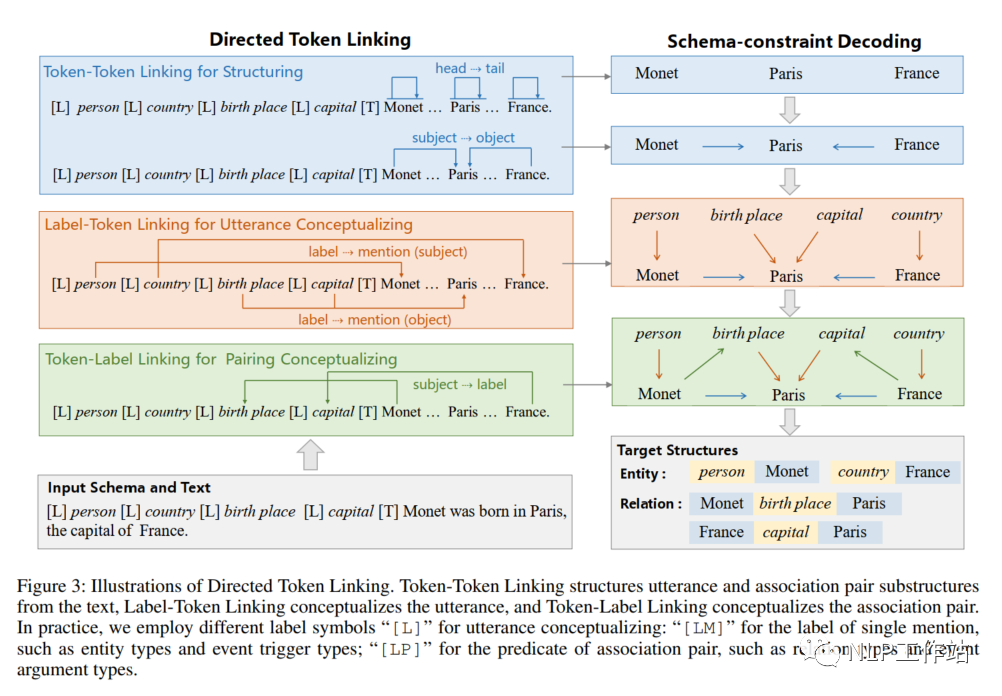

LTL操作的输出是标签名词和文本内容的pair对,例如:"person"- “Monet”、"country"-“Paris”等。有两种类型的概念化:
实体的类型,即为每一个文本分配标签类型,例如,实体“Monet”的类型为person。
客体的谓词,即将谓词类型赋给每个候选客体,例如,客体“Paris”的谓语词为birth place。其中,实体的类型和客体的谓词在概念化时采用相同的LT操作,使得两种标签语义之间相互加强。并按照头尾片段抽取风格,使用label到head(L2H)和label到tail(L2T)来定义L2T链路操作,例如,客体的谓词“Paris”-“birth place”,将标签“birth place”的头“birth”与客体“Paris”链接,将标签“birth place”尾头“ place”与客体“Paris”链接。计算LTL的得分,如下:
Token-Label Linking for Pairing Conceptualizing
为了概念化文本pair对,USM框架使用 Token-Label链接(TLL)将文本pair对的主体链接到标签上。也就是,TLL操作用head到label(H2L)和tail到label(T2L)操作连接了三元组中主体和谓语词。例如,主体“Monet”的head“Monet”链接标签“birth place”的head“birth”,主体“Monet”的tail“Monet”链接标签“birth place”的tail“place”。计算TLL的得分,如下:
Schema-constraint Decoding for Structure Composing
USM框架采用模式约束解码算法来解码最终结构,通过统一的token-linking操作提取给定的文本结构。如图3所示,USM框架,首先解码由TTL操作提取的实体文本和主客体文本,例如:“Monet”,“Paris”,“France”,“Monet”-“Pairs”,“France”-“Pairs”;然后通过LTL操作对标签名词和文本内容的pair对进行解码,例如:“person”-“Monet”,“country”-“France”,“birth place”-“Paris”,“capital”-“Paris”;最后利用TLL操作对标签及文本对进行解码,例如:“Monet”-“birth place”,“France”-“capital”。
由于以上三种链接操作互不影响,因此,在进行模型推理过程中,三种操作是高度并行的。
最后,可以根据从输入类型的模式定义,将实体类型country和person与关系类型 birth place和capital分离出来。根据TLL操作的结果“Monet”-“birth place”,“France”-“capital”,可以得到完整的三元组结构“Monet”-“birth place”-Paris和“France”-“capital”-“Paris”。
Learning from Heterogeneous Supervision
本文利用异构监督资源来学习统一令牌链接的通用结构和概念化能力,通过语言化的标签表示和统一的token链接,将异构的监督数据统一为
Pre-training
USM框架对共享语义表示中的标签模式和文本进行统一编码,并使用统一的token-linking对文本中的信息进行结构化和概念化。帮助为了学习常见的结构和概念化能力,本文收集了三种不同的监督数据用于USM的预训练。
任务数据:来自信息抽取任务的标注数据,即数据样本都有一个金标准。
远程监督数据:数据样本来自文本和知识库对齐。
间接监督数据:数据样本来自其他相关的NLP任务,主要使用机器阅读理解的数据,将(问题-文档-答案)实例中问题作为标签模式,文档作为输入文本,答案作为提及。
Learning function
在训练过程中,由于token-linking占比仅为所有token链接候选集合的1%,因此在模型优化过程中,标签的极端稀疏性是要重点解决的问题。
主要采用类别不平衡损失函数,

实验
监督实验
在4个任务的13个数据集上与其他sota模型进行了对比实验,其中AVE-unify表示非重叠数据集的平均指标,AVE-total表示所有数据集的平均指标,如表1所示,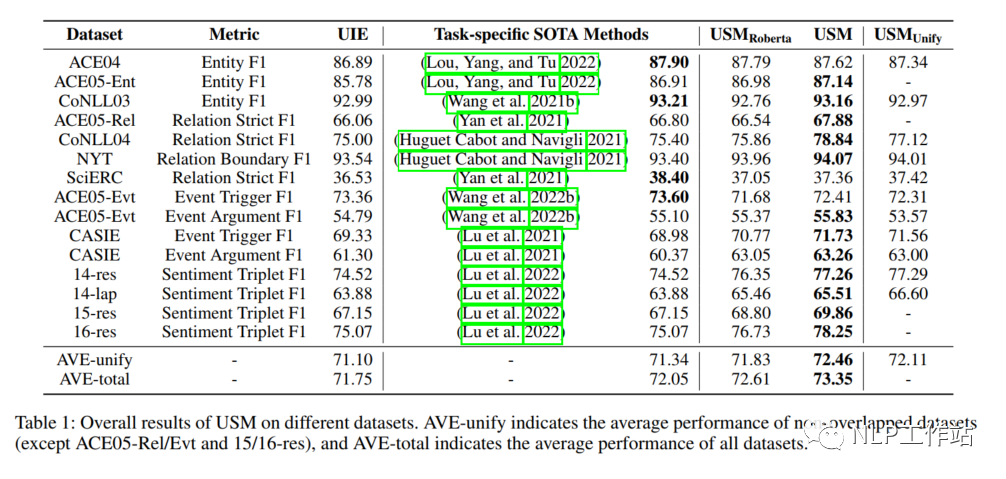
USM框架达到了sota的效果,并在AVE-total上优于各任务sota方法1.3,及时在不使用预训练模型的情况下,用Roberta初始化的USM框架也表现出了较好的效果,说明统一token-linking具有较强的可迁移性和泛化能力。
采用异构数据的预训练的USM框架相比于Roberta初始化的USM框架在所有数据集上平均提高了0.74,说明异构预训练为信息抽取的结构化和概念化提供了更好的基础。
在所有任务上进行微调的USM-Unify模型也表现出,说明USM框架可以通过单一的多任务模型解决大量信息抽取任务。
Zero-shot实验
在不同领域的9个数据集上进行了Zero-shot实验,如表2所示,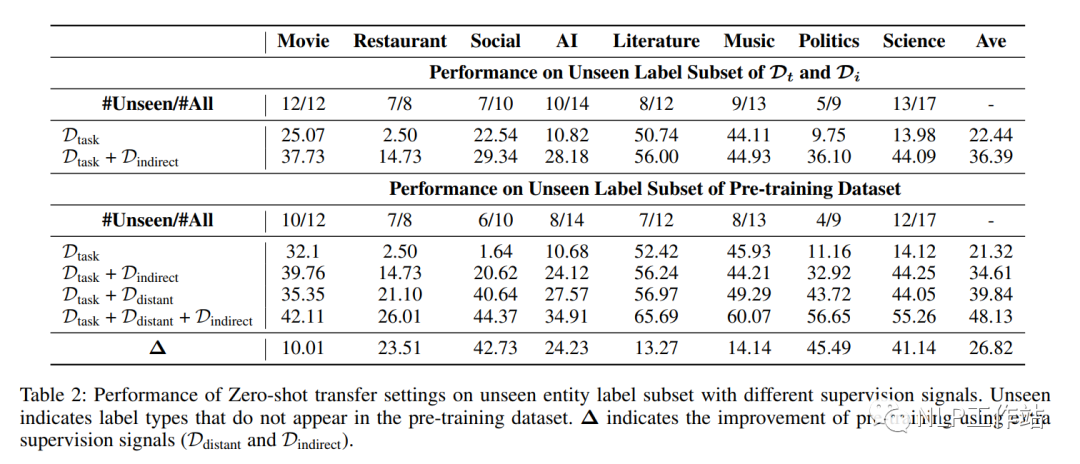
远程监督数据和间接监督数据在预训练过程中起到很重要的作用。通过表3,可以看出,在330M参数下,就可以比137B参数量的GPT3模型效果更优。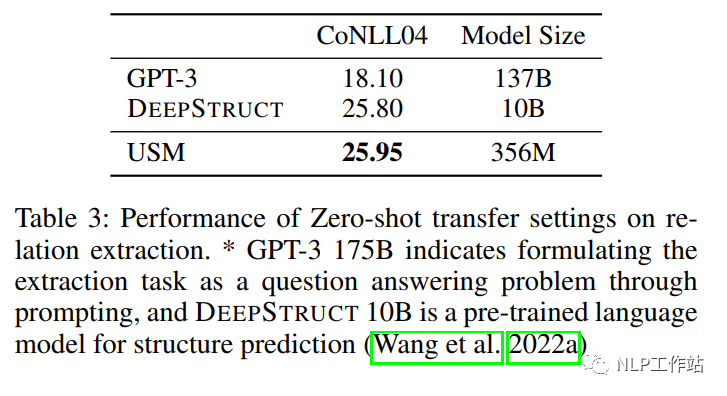
Few-shot实验
在四个信息任务上进行了Few-shot实验,如表4所示,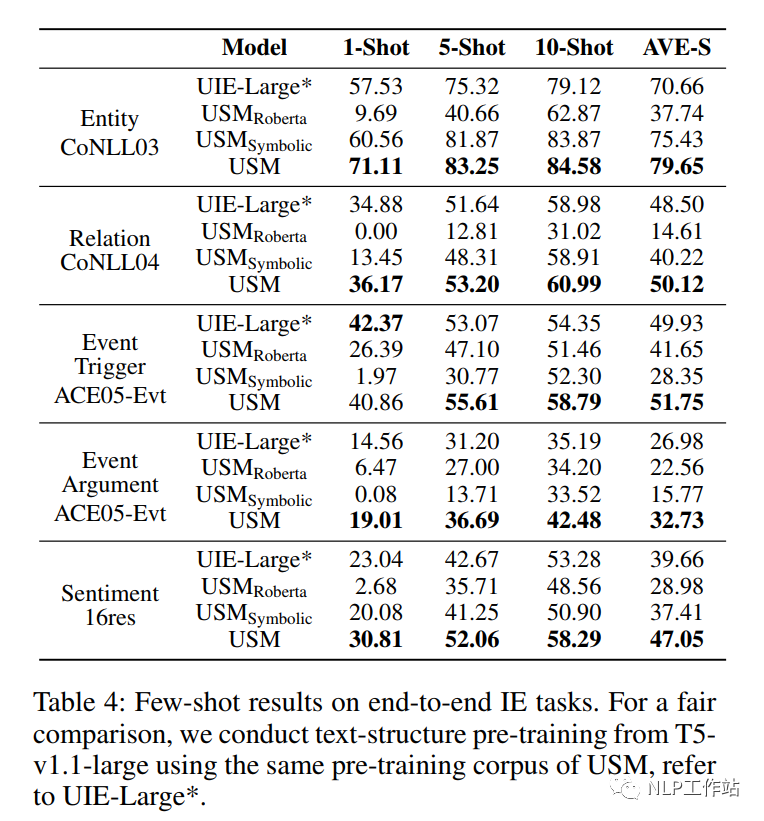
USM框架在少量数据下要比UIE效果更优,并且要好于使用Roberta进行初始化的模型。当将标签文本转化成固定符号表示时,效果变差,说明语言表达标签模式并不是无意义的,在语义表征过程中,它起到了决定性的作用。
总结
该论文通过三种统一的Token-Linking操作,实现信息抽取任务的统一模型,让我眼前一亮,相较于Seq2Seq模型来说,该方法的可解释性更强。
审核编辑:刘清
-
基于多模态语义SLAM框架2022-08-31 2897
-
文本信息抽取的分阶段详细介绍2019-09-16 2337
-
一种从零搭建汽车知识的语义网络及图谱思路2022-11-22 1462
-
一种支持QoS约束的语义Web服务发现框架2009-03-31 428
-
统一通用入侵检测框架的研究与设计2009-08-13 954
-
基于XML的WEB信息抽取模型设计2009-12-22 597
-
节点属性的海量Web信息抽取方法2018-02-06 1027
-
Web实体语义信息搜索平台2018-02-09 996
-
基于句法语义依存分析的金融事件抽取2021-03-24 1192
-
结合百科知识和句子语义特征的CNN抽取模型2021-06-15 989
-
深度学习—基于军事知识图谱的作战预案语义匹配方法研究2021-11-11 2673
-
如何统一各种信息抽取任务的输入和输出2022-09-20 2293
-
介绍一种信息抽取的大一统方法USM2023-02-15 1763
-
基于统一语义匹配的通用信息抽取框架-USM2023-02-22 1702
-
Instruct-UIE:信息抽取统一大模型2023-04-25 2946
全部0条评论

快来发表一下你的评论吧 !
