

TransGeo:第一种用于交叉视图图像地理定位的纯Transformer方法
描述
主要内容:
提出了第一种用于交叉视图图像地理定位的纯Transformer方法,在对齐和未对齐的数据集上都实现了最先进的结果,与基于CNN的方法相比,计算成本更低,所提出的方法不依赖于极坐标变换和数据增强,具有通用性和灵活性。
论文出发点:
基于CNN的交叉视图图像地理定位主要依赖于极坐标变换,无法对全局相关性进行建模,为了解决这些限制,论文提出的算法利用Transformer在全局信息建模和显式位置信息编码方面的优势,还进一步利用Transformer输入的灵活性,提出了一种注意力引导的非均匀裁剪方法去除无信息的图像块,性能下降可以忽略不计,从而降低了计算成本,节省下来的计算可以重新分配来提高信息patch的分辨率,从而在不增加额外计算成本的情况下提高性能。
这种“关注并放大”策略与观察图像时的人类行为高度相似。
图像地理定位(名词解释):
基于图像的地理定位旨在通过检索GPS标记的参考数据库中最相似的图像来确定查询图像的位置,其应用在大城市环境中改善具有大的噪声GPS和导航,在Transformer出现之前,通常使用度量学习损失来训练双通道CNN框架,但是这样交叉视图检索系统在街道视图和鸟瞰视图之间存在很大的领域差距,因为CNN不能明确编码每个视图的位置信息,之后为了改善域间隙,算法在鸟瞰图像上应用预定义的极坐标变换,变换后的航空图像具有与街景查询图像相似的几何布局,然而极坐标变换依赖于与两个视图相对应的几何体的先验知识,并且当街道查询在空间上未在航空图像的中心对齐时,极坐标转换可能会失败。
Contribution:
提出了第一种基于Transformer的方法用于交叉视图图像地理定位,无需依赖极坐标变换或数据增强。
提出了一种注意力引导的非均匀裁剪策略,去除参考航空图像中的大量非信息补丁以减少计算量,性能下降可忽略不计,通过将省下来的计算资源重新分配到信息patch的更高图像分辨率进一步提高了性能。
与基于CNN的方法相比,在数据集上的最先进性能具有更低的计算成本、GPU内存消耗和推理时间。
网络架构:
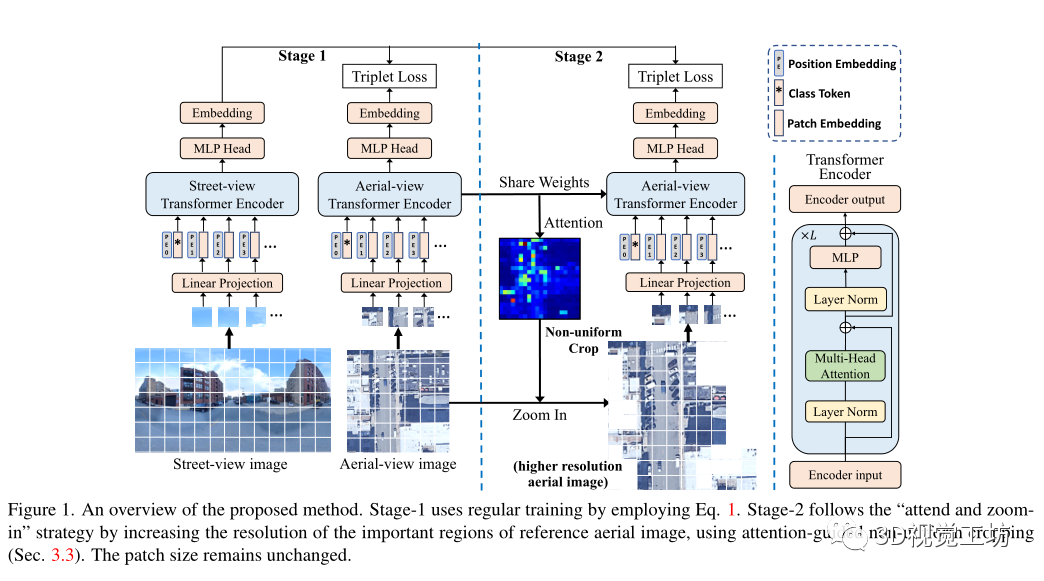

Patch Embedding:

Class Token:
最后一层输出的类token被送到一个MLP头以生成最终的分类向量,使用最终输出向量作为嵌入特征,并使用上面说的损失对其进行训练。
可学习的位置嵌入:
位置嵌入被添加到每个token以保持位置信息,采用了可学习的位置嵌入,这是包括class token在内的所有(N+1)token的可学习矩阵,可学习的位置嵌入使双通道Transformer能够学习每个视图的最佳位置编码,而无需任何关于几何对应的先验知识,因此比基于CNN的方法更通用和灵活。
多头注意力:
Transformer编码器内部架构是L个级联的基本Transformer,关键组成部分是多头注意力块,它首先使用三个可学习的线性投影将输入转换为查询、键和值,表示为Q、K、V,维度为D,然后将注意力输出计算为
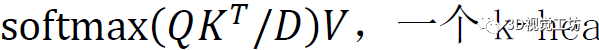
,一个k-head注意力块用k个不同的head对Q、k、V进行线性投影,然后对所有k个head并行执行attention,输出被连接并投影回模型维度D,多头注意力可以模拟从第一层开始的任意两个标记之间的强全局相关性,这在CNN中是不可能学习的,因为卷积的接受域有限。
Attention引导的非均匀裁剪:
当寻找图像匹配的线索时,人类通常会第一眼找到最重要的区域,然后只关注重要的区域并放大以找到高分辨率的更多细节,把“关注并放大”的思想用在交叉图像地理定位中可能更有益,因为两个视图只共享少量可见区域,一个视图中的大量区域,例如鸟瞰图中的高楼屋顶,在另一个视图可能看不见,这些区域对最终相似性的贡献微不足道,可以去除这些区域以减少计算和存储成本,然而重要的区域通常分散在图像上,因此CNN中的均匀裁剪不能去除分散的区域,因此提出了注意力引导的非均匀裁剪

在鸟瞰分支的最后一个transformer编码器中使用注意力图,它代表了每个token对最终输出的贡献,由于只有class token对应的输出与MLP head连接,因此选择class token与所有其他patch token之间的相关性作为注意力图,并将其重塑为原始图像形状。
模型优化:
为了在没有数据增强的情况下训练Transformer模型,采用了正则化/泛化技术ASAM。在优化损失时使用ASAM来最小化损失landscape的自适应锐度使得该模型以平滑的损失曲率收敛以实现强大的泛化能力。
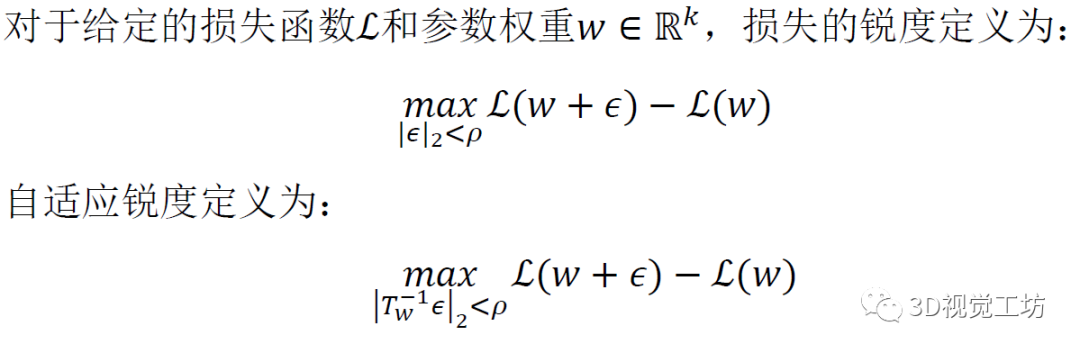
通过同时最小化的损失和自适应锐度,能够在不使用任何数据增强的情况下克服过拟合问题
实验:
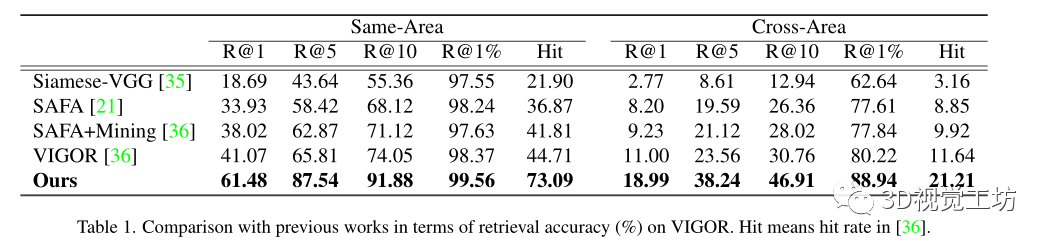
在两个城市规模的数据集上进行了实验,即CVUSA和VIGOR,分别代表了空间对齐和非对齐设置
评估度量:在top-k召回准确率,表示为“R@k”,基于每个查询的余弦相似度检索嵌入空间中的k个最近参考邻居,如果地面真实参考图像出现在前k个检索图像中,则认为其正确。
预测GPS位置和地面真实GPS位置之间的真实世界距离作为VIGOR数据集上的米级别的评估。
命中率,即覆盖查询图像(包括地面真相)的前1个检索参考图像的百分比
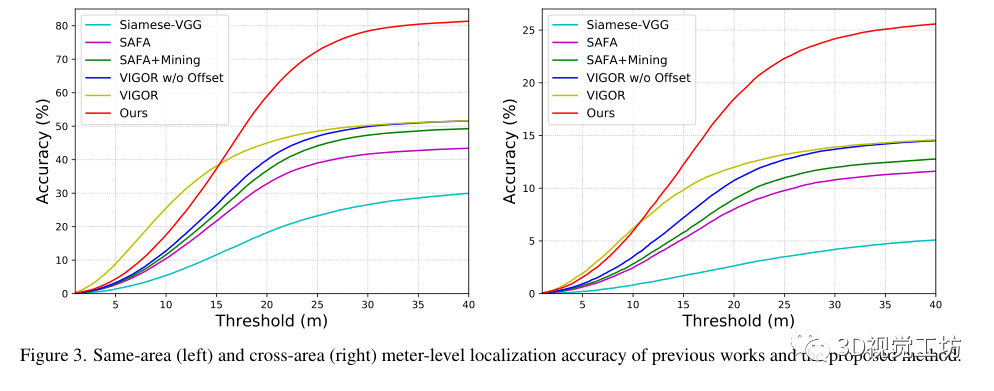
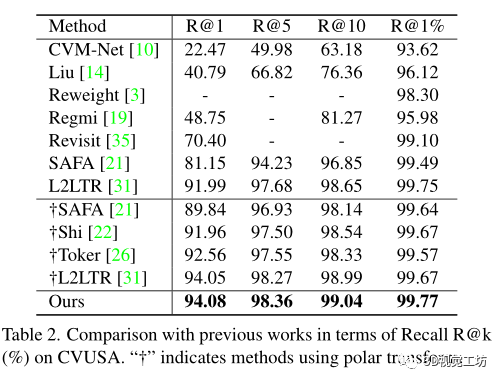
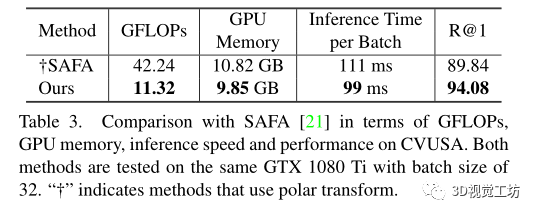
和之前SOTA方法SAFA在计算代价上的比较
总结:
提出了第一种用于交叉视图图像地理定位的纯Transformer方法,在对齐和未对齐的数据集上都实现了最先进的结果,与基于CNN的方法相比,计算成本更低。
缺点是使用两个管道,且patch选择简单地使用不可通过参数学习的注意力图。
审核编辑 :李倩
-
TomTom和意法半导体合作推出创新级地理定位工具和服务2018-09-07 2981
-
三极管各位大神,你们见过第一种画法吗?2019-05-19 2994
-
一种新的图像定位和分类系统实现方案2009-07-30 861
-
一种多尺度多视点特性视图生成方法的研究和应用_谢冰2017-03-15 858
-
Semtech简化LoRa®应用的地理定位开发2018-11-26 2105
-
Semtech宣布推出LoRa Cloud™地理定位服务2019-03-14 1715
-
Semtech推出LoRa Cloud地理定位服务2019-03-19 1166
-
OpenAl提出了一种适用于文本、图像和语音的稀疏Transformer2019-04-28 4301
-
为什么现在的物联网设备都需要地理定位功能2020-07-17 1630
-
VIAVI为爱立信智能自动化平台提供地理定位功能支持2021-12-17 1946
-
SMTC地理定位服务正式集成至腾讯云物联网开发平台2022-01-13 937
-
LoRa Edge™地理定位平台满足物联网应用等创新需求2022-06-12 2223
-
地理定位的 4 项技术改进助长了新的垂直领域2022-07-26 1798
-
如何实现这些类型的图像处理方法2022-08-30 1718
-
AI驱动的板载地理定位-由瑞苏盈科FPGA SoM加速!2025-04-11 965
全部0条评论

快来发表一下你的评论吧 !
