

Meta是如何构建新人工智能CICERO的?
电子说
描述
前段时间,Meta 正式发布人工智能 CICEROO——这是第一个在时下流行的战略游戏 Diplomacy 中表现达到人类水平的人工智能。在 CICEROO 的背后,有哪些技术实践?
本文最初发布于 Meta AI 官方博客。
长期以来,游戏一直是人工智能最新进展的试验场——从深蓝战胜国际象棋大师 Garry Kasparov,到 AlphaGo 熟练掌握围棋,再到 Pluribus 在扑克游戏中战胜了人类高手。但真正有用的多功能代理不能局限于在棋盘上移动棋子。我们能否建立更有效、更灵活的代理,使用语言进行谈判、说服,并与人合作,像人那样实现战略目标?
日前,我们宣布了一项突破性进展,向着构建掌握这些技能的人工智能迈进了重要的一步。我们已经构建了一个代理 CICERO——这是第一个在时下流行的战略游戏 Diplomacy 中表现达到人类水平的人工智能。CICERO 在 webDiplomacy.net(该游戏的在线版本)上证明了这一点,它的成绩是人类玩家平均分的两倍多,并且在玩过多个游戏的玩家中排名前 10%。
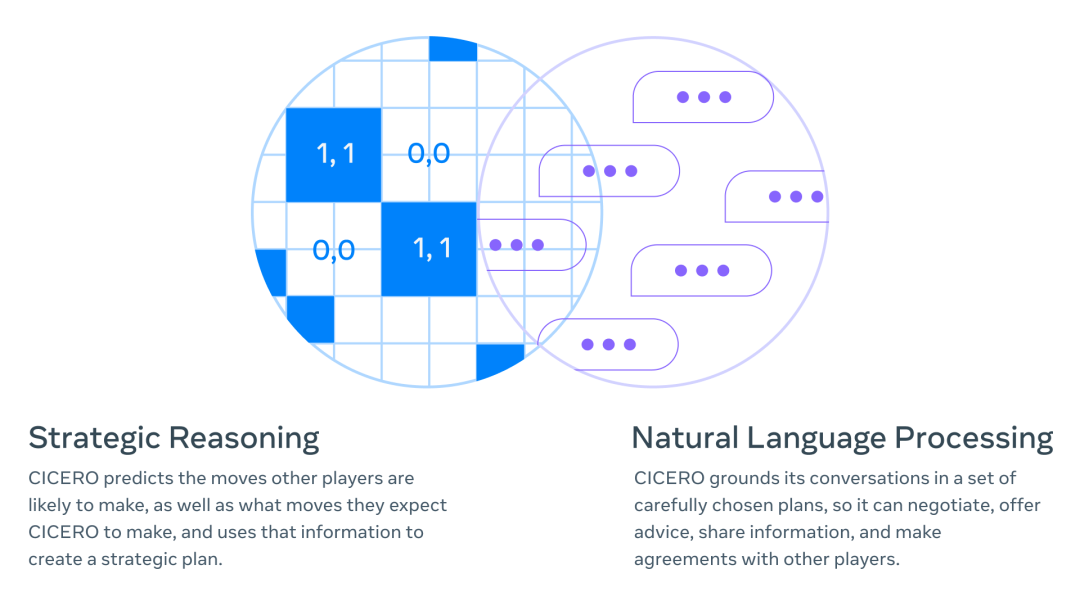
几十年来,Diplomacy 一直被视为人工智能领域近乎不可能的重大挑战,因为它要求玩家掌握了解他人动机和观点的艺术;制定复杂的计划并调整策略;然后用自然语言与他人达成协议,说服他们建立伙伴关系和联盟,等等。CICERO 在使用自然语言与人进行外交谈判方面表现非得常出色,以至于玩家常常倾向于与 CICERO 而不是其他人类玩家合作。
与国际象棋和围棋等游戏不同,Diplomacy 是一个关于人而不是棋子的游戏。如果代理无法辨别出某人可能在虚张声势,或者另一个玩家会认为某一举动具有攻击性,那么它很快就会输掉游戏。同样,如果它不能像真人那样说话——表现出同情心,建立关系,并对游戏有一定的了解——它就无法找到其他愿意与它合作的玩家。

我们的主要成就是打通了两个完全不同的人工智能研究领域并开发了新技术:战略推理(如 AlphaGo 和 Pluribus 等代理中使用的技术)和自然语言处理(如 GPT-3、BlenderBot 3、LaMDA 和 OPT-175B 等模型中使用的技术)。举个例子,CICERO 可以推断出,在游戏后期,它会需要特定玩家的支持,然后精心设计一个策略来赢得这个人的青睐——甚至可以识别出这个玩家从自己特定的视角所看到的风险和机会。
我们已经将代码开源,并发表了一篇论文,希望可以为更广泛的人工智能社区带来帮助,让他们使用 CICERO 来推动人类与人工智能的合作进一步进展。如果你想了解更多关于这个项目的信息,或者试用这个代码,请移步 CICERO 的官网。感兴趣的研究人员可以向 CICERO RFP 提交建议,获取数据使用权。
我们是如何构建 CICERO 的?
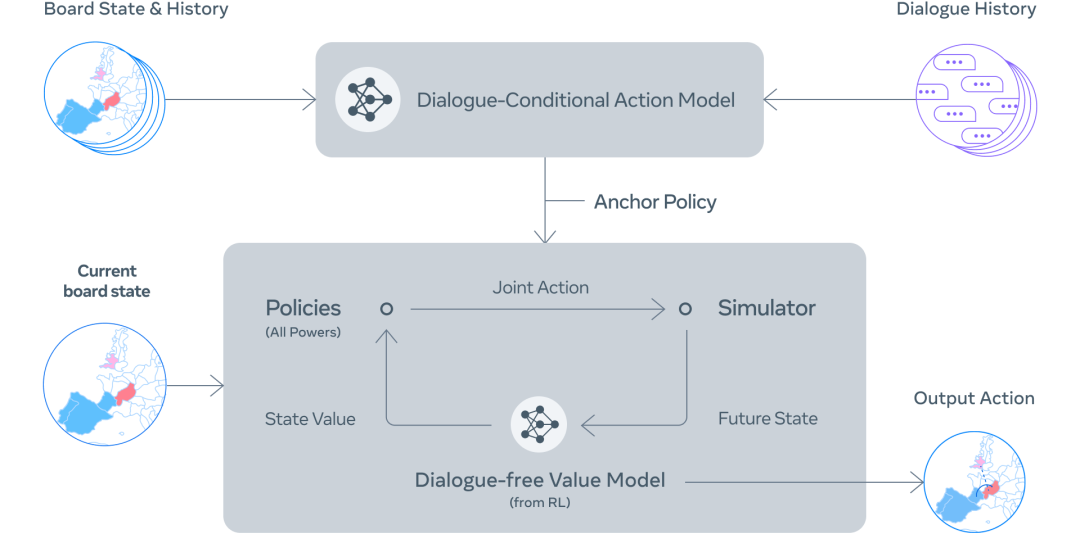
CICERO 的核心是一个可控的 Diplomacy 对话模型,外加一个策略推理引擎。在游戏中的每个时刻,CICERO 都会查看棋盘及其对话历史,并对其他玩家可能采取的行动建模。然后,它会用这个方案来控制一个可以生成自由对话的语言模型,告知其他玩家它的计划,为其他玩家提出合理的行动建议,与他们做好协调。
可控的对话
为了构建一个可控的对话模型,我们从一个有 27 亿参数的类似 BART 的语言模型开始,使用从互联网上收集的文本对它进行了预训练,然后使用 webDiplomacy.net 上超过 4 万个人类游戏对它进行了优化。我们开发了一些技术,将训练数据中的信息与游戏中相应的计划动作进行自动标注,这样,在推理时我们就可以控制对话的生成,讨论代理和其对话伙伴所期望的具体行动。
例如,如果我们的代理在扮演法国,在涉及英格兰支持法国进入勃艮第的计划时,对话模型可能会生成这样一条信息发送给英格兰,“嗨,英格兰!你愿意支持我进入勃艮第吗?”以这种方式控制对话生成,可以使 CICERO 将对话建立在一套计划之上,并随着时间的推移完善和改进,以更好地进行谈判。这有助于代理更有效地协调和说服其他玩家。
第 1 步:使用棋盘状态和当前对话,CICERO 对每个人下一步会做什么做了一个初步预测。

第 2 步:CICERO 利用规划反复完善该预测,然后利用这些预测为自己和合作伙伴形成一个意图。
第 3 步:根据棋盘状态、对话和意图,生成几条候选信息。
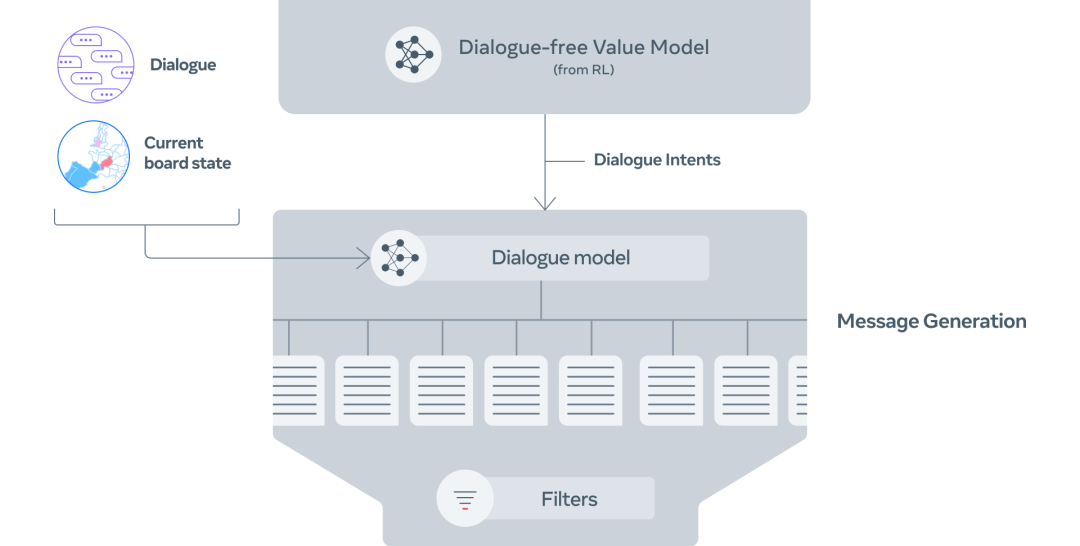
第 4 步:对候选信息进行过滤,减少废话,使价值最大化,并确保其符合意图。
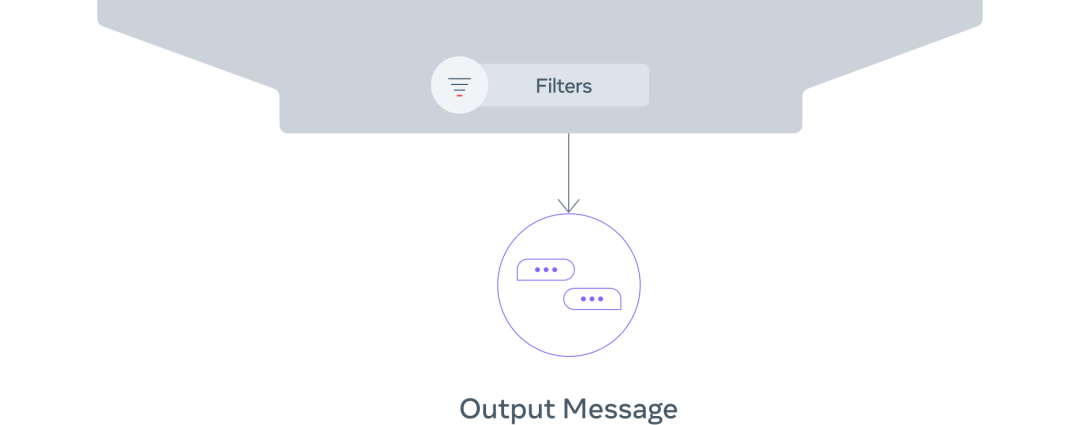
我们利用一些过滤机制——例如经过训练的分类器来区分人类和模型生成的文本——来进一步提高对话质量,确保生成的对话是切合实际的,与当前游戏状态和之前的信息相一致,并且战略上也合理。
对话感知策略 & 规划
以前,在象棋、围棋和扑克等对抗性游戏中的超人代理是通过自我强化学习(RL)创建的——让代理与自身的其他副本进行数百万次对局来学习最佳策略。然而,涉及合作的游戏需要对人类在现实生活中的实际行为进行建模,而不是对完美的机器人副本应该做什么进行建模。特别是,我们希望 CICERO 制定的计划与它和其他玩家的对话一致。
人类建模的经典方法是监督学习,即用带标签的数据(如过去游戏中人类玩家的行动数据库)来训练代理。然而,纯粹依靠监督学习根据过去的对话结果来选择行动,会导致代理的能力相对较弱,而且很容易被利用。例如,一个玩家可以告诉代理,“很高兴我们能达成一致,你将把你的部队从巴黎撤出!”由于类似的信息只有在达成协议时才会出现在训练数据中,所以代理可能真的会将其部队调离巴黎,即使这样做是一个明显的战略失误。
为了解决这个问题,CICERO 会运行一个迭代规划算法,平衡对话的一致性和合理性。首先,代理会根据它与其他玩家的对话预测每个人在当前回合的策略,同时也预测其他玩家会如何预测代理的策略。然后,它会运行我们开发的名为 piKL 的规划算法,根据其他玩家预测的策略选择具有更高期望值的新策略来迭代改进自己的预测,同时还会设法使新的预测接近于初始的策略预测。我们发现,与单纯的监督学习相比,piKL 能更好地模拟人类游戏,帮代理选出更好的策略。

生成自然、有目的的对话
在 Diplomacy 中,玩家与他人的交谈方式,甚至比他们移动棋子的方式更重要。在与其他玩家一起制定策略时,CICERO 能够说出清晰而有说服力的话。例如,在一个演示游戏中,CICERO 要求一个玩家立即在棋盘的某个部分提供支持,同时向另一个玩家施加压力,使其在后续的游戏中考虑结盟。
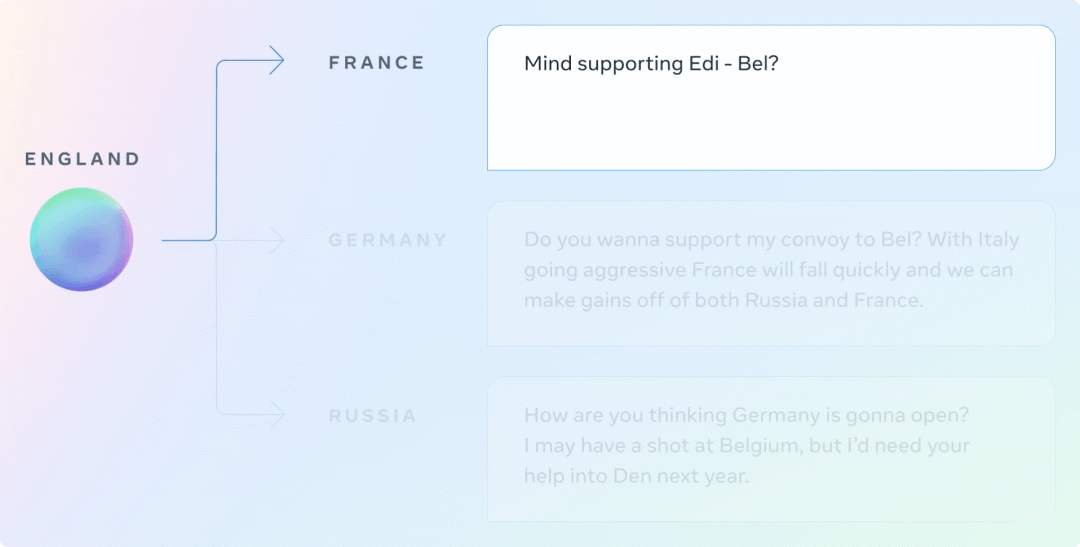
在这些交流中,CICERO 试图通过向三个不同的玩家提供行动建议来执行其策略。在第二次对话中,代理能够告诉其他玩家为什么他们应该合作,以及合作如何对双方有利。在第三次对话中,CICERO 既是在征集信息,也是在为未来的行动打基础。
哪里还有改进空间?
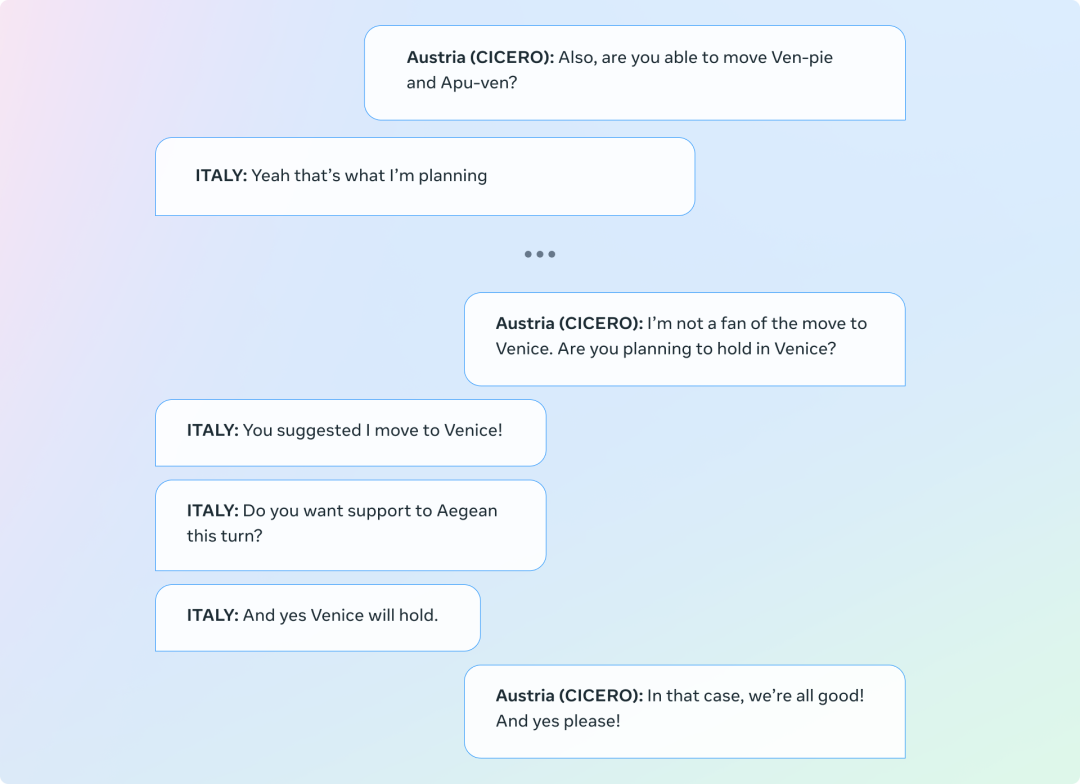
必须认识到,CICERO 有时也会生成不一致的对话,妨碍目标的达成。在下面的例子中,CICERO 扮演的是奥地利,它与自己的第一条信息(要求意大利移到威尼斯)前后矛盾了。虽然我们的过滤器套件就是用于检测这类错误,但它并不完美。
将 Diplomacy 作为促进 人类与人工智能互动的沙盒
在竞合类游戏中,以目标为导向的对话系统的出现,对于协调 AI 与人类的意图和目标提出了重要的社交和技术挑战。Diplomacy 为研究这一问题提供了一个特别有趣的环境,因为玩游戏需要在相互冲突的目标中艰难应对,并将这些复杂的目标翻译成自然语言。举个简单的例子,玩家可能会为了维持一个盟友关系而选择在短期利益上做出妥协,目的是希望这个盟友能够在下个回合中帮助他们取得更有利的地位。
虽然我们在这项工作中取得了重大的进展,但是,将语言模型与具体意图紧密结合的能力,以及确定这些意图的技术(和规范)挑战,仍然是有待解决的重要问题。通过开放 CICERO 的源代码,我们希望人工智能研究人员能够基于我们的工作以负责任的方式继续研究下去。通过使用我们的对话模型进行零样本分类,我们已经在这个新领域中围绕检测和删除有毒信息做了一些初步的工作。我们希望,Diplomacy 可以作为一个安全的沙盒来推进人类与人工智能互动的研究。
未来展望
虽然 CICERO 只会玩 Diplomacy 这个游戏,但这项成果背后的技术涉及到现实世界的许多应用。比如,通过规划和 RL 控制自然语言生成,减少人类和人工智能驱动的代理之间的沟通障碍。再比如,如今的人工智能助手只擅长回答简单的问题,如告诉你天气,但如果他们能维持长时间的对话,并以教给你一个新技能为目标,那会怎样?另外,想象有一个视频游戏,其中的非玩家角色(NPC)可以像人一样计划和交谈——理解你的动机并相应地调整对话——以帮助你完成攻打城堡的任务。
我们非常看好这些领域未来的发展潜力,也希望可以看到其他人基于我们的研究开展进一步的工作。
审核编辑 :李倩
-
Meta将率先使用英伟达最新人工智能芯片2024-03-22 1358
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2421
-
【机器视觉】欢创播报 |Meta开发出懂谈判的人工智能2022-11-25 1281
-
物联网人工智能是什么?2021-09-09 5371
-
人工智能芯片是人工智能发展的2021-07-27 6760
-
如何构建人工智能的未来?2021-03-03 3070
-
什么是基于云计算的人工智能服务?2019-09-11 6009
-
人工智能:超越炒作2019-05-29 5080
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5945
-
解读人工智能的未来2018-11-14 4994
-
人工智能就业前景2018-03-29 8467
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 8151
-
人工智能:革命还是伤害?2016-10-10 10255
-
人工智能是什么?2015-09-16 6492
全部0条评论

快来发表一下你的评论吧 !
