

C语言语句简析
描述
开发过程中,你是否会发出“基础不牢,地动山摇”的感慨,我相信,只要有经验的工程师,应该都有过。
鱼鹰曾经因为一个很基础的知识,差点毁了整个项目,这不是危言耸听。
因为这个代码用于整个系统自检,一旦运行出错,整个系统就废了。
为了不让别人篡改鱼鹰的代码,鱼鹰设计了多套机制,其中一个就是定时检查关键代码是否已执行,如果有一次没有执行,那么系统进入异常状态,这个功能类似窗口看门狗。
uint16_t run_cnt, run_cnt_next;
void function1()
{
do something ;
run_cnt++; // 自加,表示该函数已执行
}
int main()
{
while(1)
{
function1();
if(run_cnt != run_cnt_next + 1) // 判断两个变量是否匹配
{
do error some thing
}
run_cnt_next++; // 这个位置也自加,表示这里已执行
}
}
类似流程如上,当时鱼鹰为了减少变量空间,将计数器设计成了 uint16_t 类型,导致埋下了隐患。这个流程乍一看没有问题,因为 run_cnt 比 run_cnt_next 先加,那么 run_cnt_next + 1 应该等于 run_cnt,如果不相等,作错误处理。
甚至短时间内运行不会有任何问题,除非 16 位溢出…… 所以一个量产项目,任何一点改动,都可能需要长时间的稳定测试,只有这样才能确保系统稳定性,不能认为自己能力强,写的代码不用测试就直接合并了。
原先鱼鹰以为,这两个变量都是 16 位,那么 + 1 的结果应该也是16 位,最后比较时,也是 16 位比较,这样即使最终 16 位自加溢出了,结果也会是正确的。
if(run_cnt != run_cnt_next + 1) // 判断两个变量是否匹配
{
do error some thing
}
但你以为,终究是你以为。 实际上,因为你和 1 自加了,最终比较是按照 32 位进行比较,而 run_cnt 受到变量位数限制,始终是 16 位的结果(但扩展成 32 位比较,即高 16 位全是 0)
这样就会导致在溢出时,两者是不相等的。 比如上一次 run_cnt 为 0xFFFF 时(受位数限制,最大只能是这个),run_cnt_next 为 0xFFFE,此次结果比较即使按 32 位比较,也是没有问题的,都是 0xFFFF。
但下一次运行时,run_cnt 自加,溢出变成 0,而 run_cnt_next 是 0xFFFF,再和 1 相加,因为比较会使用 32 位比较,所以此时结果是 0x10000,最终导致两者不相等(0 != 0x10000)。
那么为什么会导致上面的问题呢?这里涉及到两个 C 语言基础知识点,估计大家以前都了解过,但估计没有当回事。
1、常量默认为 int 型(但不一定是 32 bit ,和内核和编译器有关,上面的 +1 就是 int 型)
2、整型提升(详细可网上查找) 因为两边的结果类型不一致(+ 1 导致右边结果成了 int 类型),所以最终按 int 型处理。
最终导致溢出时,结果判断失败。 我们可以通过汇编看出一些端倪: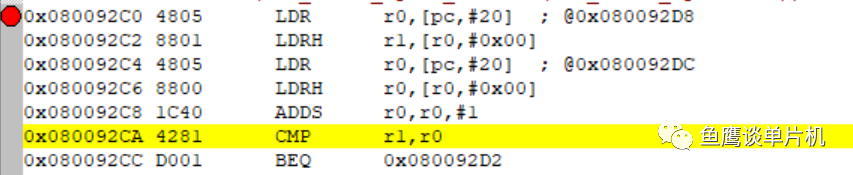
我们可以看到 r0 + 1 之后,直接和 r1 比较,也就是说,结果可能超过 0xFFFF,导致出错。
那么,怎么样才可以保证结果为 16 位呢? 我们可以这样处理:
if((uint16_t)run_cnt != (uint16_t)(run_cnt_next + 1)) // 强制转化为 16 位比较
{
do error some thing
}
我们可通过汇编发现,多了一条 UXTH 指令,用于把 16 位结果扩展成 32 位(从这里我们也可以得出结论,结果比较总是 32 bit 比较)。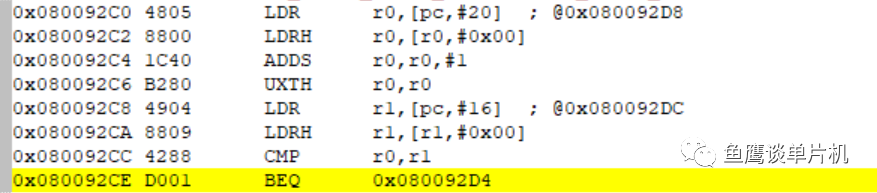
到此,分析结束,可以看到,为了解释这么一条简单的 C 语言语句,还是挺困难的事情。
审核编辑:刘清
-
C语言中if语句、if-else语句和switch语句详解2023-08-18 13646
-
C语言for语句介绍2023-03-09 2369
-
C语言_语句与位运算基本练习2022-08-14 2526
-
单片机中常用的C语言语句合集2022-01-12 1271
-
嵌入式SQL语句与主语言之间的通信2021-12-22 2322
-
区分SQL语句与主语言语句2021-10-28 1777
-
C语言语句的规则函数2021-07-14 1008
-
Prel语法与C语言语法的异同综述2021-05-25 1003
-
怎么理解Assert中的断言语句?2020-03-03 3779
-
请问下面的C语言语句表达什么意思?2019-11-01 1504
-
C语言的if条件语句演示实例和proteus仿真图2019-07-10 1013
-
C语言入门C语言语句的更换技巧2017-04-28 1572
-
C语言语句用法2017-01-05 4225
-
单片机C语言教程-基础语句2010-03-27 3335
全部0条评论

快来发表一下你的评论吧 !
