

如何破解PCIe 6.0带来的芯片设计新挑战?
描述

本文转载自《半导体行业观察》感谢《半导体行业观察》对新思科技的关注 PCI Express (PCIe) 6.0规范实现了64GT/s链路速度,还带来了包括带宽翻倍在内的多项重大改变,这也为SoC设计带来了诸多新变化和挑战。对于HPC、AI和存储SoC开发者来说,如何理解并应对这些变化带来的设计挑战变得至关重要。 本文将就上述问题和方案作详细介绍及探讨。 PCIe 6.0的重大新变化 变化一:PCIe 6.0电器性发生根本性的机制改变 为了实现64GT/s的链路速度,PCIe 6.0采用脉冲幅度调制4级 (PAM4) 信号,在与32GT/s PCIe相同的单元间隔(UI)中提供4个幅度级别(2 位)。图1显示了三眼眼图与此前的单眼眼图的对比。
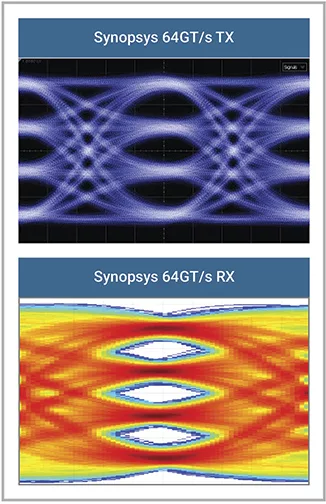 图 1:与NRZ信号相比,PCIe 6.0 PAM-4信号是三眼眼图
与NRZ相比,转换到PAM4信号编码引入了更高的误码率(BER)。为缓解这种情况,6.0规范在以 64GT/s 运行时实现了许多新功能。例如,当将新的4级电压眼图映射到数字值时,格雷编码可以最小化每个 UI 内的错误,并且发送器应用预编码来最小化迸发错误;PCIe 6.0还采用前向纠错(FEC)机制来降低较高的误码率。这些对 PCIe 协议和控制器设计都具有重大影响。
变化二:新一代协议的引入
PCIe 6.0 引入了全新的“FLIT 模式”,其中数据包被组织在固定大小的流控制单元中,而不是过去规范版本中的可变大小。这种模式简化了控制器级别的数据管理,带来了更高的带宽效率、更低的延迟和更小的控制器占用空间。当以 64GT/s 的速率运算时,FLIT 模式使用未编码数据(称为“1b1b 编码”),而 128/130 编码用于 8GT/s 至 32GT/s 的链路速度,经典8b10b编码用于2.5GT/s 和 5GT/s 的链路速度。
与具有相同配置的 32GT/s PCIe 控制器相比,64GT/s PCIe 6.0 控制器所需的硅面积显著增加;支持1b1b编码不仅增加了第三物理层路径(位于 8b10b 和 128b130b 顶部),还增加了数据链路层中的逻辑;FLIT模式中使用的新优化标头,也进一步增加了逻辑门数,超过了 32GT/s 解决方案。
变化三:PIPE数据路径宽度增加,每个时钟周期有多个数据包
为了保持与上一代相同的最大时钟频率,64GT/s下PIPE数据路径宽度增加了一倍,即需要1024位数据路径的16通道设计,这为芯片设计带来了新的问题。
要知道,大于128位的数据路径宽度,可能会导致SoC需要在每个时钟周期处理多个PCIe 数据包。最小的PCIe事务层数据包 (TLP) 可以被视为 3 个 DWORD(12 字节)加上 4 字节 LCRC,总共 16 个字节(128 位)。在 8GT/s 时,使用PCIe PHY的 500MHz 16 位 PIPE 接口最为常见,这意味着8通道及以下(16 位/通道 * 8 通道 = 128 位)的链路宽度会在每个时钟最多传输一个完整的数据包。但是,16通道(16位/通道 * 16通道 = 256位)在每个时钟周期就需要传输两个完整的数据包。
如表1显示,随着链路速度的提高,每个时钟的完整数据包的数量相应增加,从而影响越来越多的设计。
图 1:与NRZ信号相比,PCIe 6.0 PAM-4信号是三眼眼图
与NRZ相比,转换到PAM4信号编码引入了更高的误码率(BER)。为缓解这种情况,6.0规范在以 64GT/s 运行时实现了许多新功能。例如,当将新的4级电压眼图映射到数字值时,格雷编码可以最小化每个 UI 内的错误,并且发送器应用预编码来最小化迸发错误;PCIe 6.0还采用前向纠错(FEC)机制来降低较高的误码率。这些对 PCIe 协议和控制器设计都具有重大影响。
变化二:新一代协议的引入
PCIe 6.0 引入了全新的“FLIT 模式”,其中数据包被组织在固定大小的流控制单元中,而不是过去规范版本中的可变大小。这种模式简化了控制器级别的数据管理,带来了更高的带宽效率、更低的延迟和更小的控制器占用空间。当以 64GT/s 的速率运算时,FLIT 模式使用未编码数据(称为“1b1b 编码”),而 128/130 编码用于 8GT/s 至 32GT/s 的链路速度,经典8b10b编码用于2.5GT/s 和 5GT/s 的链路速度。
与具有相同配置的 32GT/s PCIe 控制器相比,64GT/s PCIe 6.0 控制器所需的硅面积显著增加;支持1b1b编码不仅增加了第三物理层路径(位于 8b10b 和 128b130b 顶部),还增加了数据链路层中的逻辑;FLIT模式中使用的新优化标头,也进一步增加了逻辑门数,超过了 32GT/s 解决方案。
变化三:PIPE数据路径宽度增加,每个时钟周期有多个数据包
为了保持与上一代相同的最大时钟频率,64GT/s下PIPE数据路径宽度增加了一倍,即需要1024位数据路径的16通道设计,这为芯片设计带来了新的问题。
要知道,大于128位的数据路径宽度,可能会导致SoC需要在每个时钟周期处理多个PCIe 数据包。最小的PCIe事务层数据包 (TLP) 可以被视为 3 个 DWORD(12 字节)加上 4 字节 LCRC,总共 16 个字节(128 位)。在 8GT/s 时,使用PCIe PHY的 500MHz 16 位 PIPE 接口最为常见,这意味着8通道及以下(16 位/通道 * 8 通道 = 128 位)的链路宽度会在每个时钟最多传输一个完整的数据包。但是,16通道(16位/通道 * 16通道 = 256位)在每个时钟周期就需要传输两个完整的数据包。
如表1显示,随着链路速度的提高,每个时钟的完整数据包的数量相应增加,从而影响越来越多的设计。
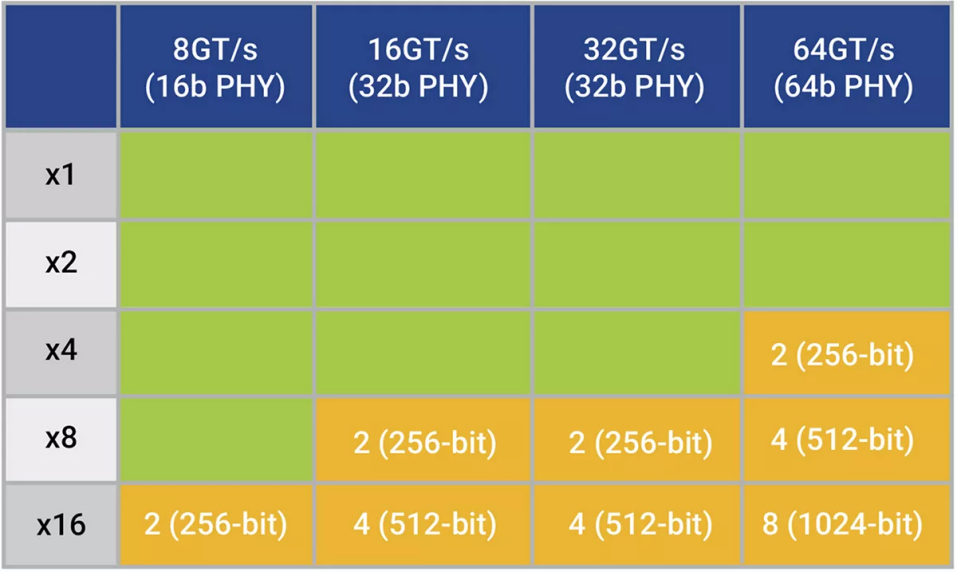 表 1:数据路径宽度随链路速度增加,导致更多配置超过128位阈值
PCIe 6.0的优化设计
1.松弛排序
PCIe排序规则需要Posted事务,例如内存写入保持有序,除非数据包标头中设置了松弛排序 (RO) 或 ID 排序 (IDO) 属性。使用RO集的Posted事务可以传递任何先前 Posted 事务,而使用IDO集的事务只能使用不同的请求者ID传递先前事务。
以下四个示例展示了这两种属性对于实现完整的PCIe 64GT/s 性能的重要性。他们均利用4个PCIe内存的序列写入256字节中的每一个,表示将1KB 有效载荷递送到地址1000,然后是4个字节的PCIe内存写入,表示将“成功完成”指示递送到地址7500。表中的每一行代表一个时间段,而三列(从左到右)表示事务到达PCIe引脚、应用程序接口和 SoC 内存。在所有 4 次内存写入之前,“成功完成”指示到达内存的任何场景都反映出失败,因为软件在收到指示后立即可进行数据处理,因此在交付正确的数据之前处理。
示例1:只要其中一个应用程序接口的带宽至少等于 PCIe 带宽,该接口就可以正常工作。
表 1:数据路径宽度随链路速度增加,导致更多配置超过128位阈值
PCIe 6.0的优化设计
1.松弛排序
PCIe排序规则需要Posted事务,例如内存写入保持有序,除非数据包标头中设置了松弛排序 (RO) 或 ID 排序 (IDO) 属性。使用RO集的Posted事务可以传递任何先前 Posted 事务,而使用IDO集的事务只能使用不同的请求者ID传递先前事务。
以下四个示例展示了这两种属性对于实现完整的PCIe 64GT/s 性能的重要性。他们均利用4个PCIe内存的序列写入256字节中的每一个,表示将1KB 有效载荷递送到地址1000,然后是4个字节的PCIe内存写入,表示将“成功完成”指示递送到地址7500。表中的每一行代表一个时间段,而三列(从左到右)表示事务到达PCIe引脚、应用程序接口和 SoC 内存。在所有 4 次内存写入之前,“成功完成”指示到达内存的任何场景都反映出失败,因为软件在收到指示后立即可进行数据处理,因此在交付正确的数据之前处理。
示例1:只要其中一个应用程序接口的带宽至少等于 PCIe 带宽,该接口就可以正常工作。
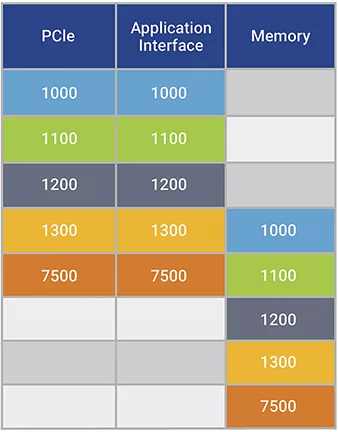 表 2:单一全速率应用程序接口可正确传输数据
示例2:双接口通常会出现故障,因为无法保证SoC中两个通往内存的独立路径之间的到达顺序。
表 2:单一全速率应用程序接口可正确传输数据
示例2:双接口通常会出现故障,因为无法保证SoC中两个通往内存的独立路径之间的到达顺序。
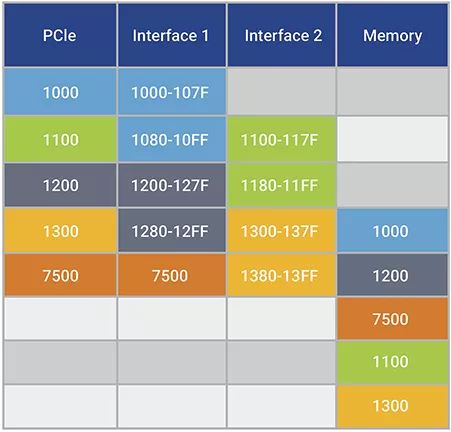 表 3:显示双半速率应用程序接口失败,原因是“成功完成”指示早于所有数据到达
示例3:将强排序流量强制到单个接口可避免出现无序到达,但由于无法使用全部内部带宽,因此很快落后于 PCIe 链路。
表 3:显示双半速率应用程序接口失败,原因是“成功完成”指示早于所有数据到达
示例3:将强排序流量强制到单个接口可避免出现无序到达,但由于无法使用全部内部带宽,因此很快落后于 PCIe 链路。
 表 4:由于无法全速传输数据,所示的双半速应用程序接口失败
示例4:当链路伙伴把数据有效载荷数据包标记为 RO 且把成功完成数据包标记为强排序时,两个半速率接口可以成功传输。请注意,当 RO 有效载荷数据无序到达时,非 RO 写入 7500 不被允许传递有效载荷写入,因此在发送所有先前写入之前,不会将其发送到应用接口。
表 4:由于无法全速传输数据,所示的双半速应用程序接口失败
示例4:当链路伙伴把数据有效载荷数据包标记为 RO 且把成功完成数据包标记为强排序时,两个半速率接口可以成功传输。请注意,当 RO 有效载荷数据无序到达时,非 RO 写入 7500 不被允许传递有效载荷写入,因此在发送所有先前写入之前,不会将其发送到应用接口。
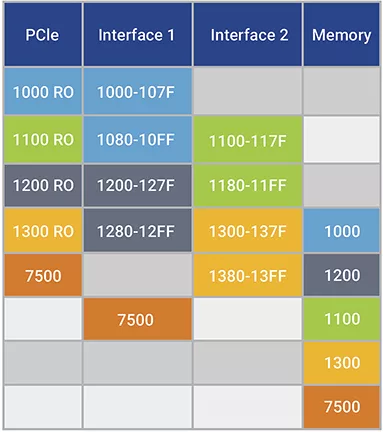 表 5:显示双半速应用程序接口通过对有效载荷数据使用松弛排序成功
SoC 设计人员可以在其出站数据流中设置RO属性,并显著提高PCIe链路性能。IDO排序属性在许多情况下都具有类似的优势,大多数 PCIe 实现都可以将其应用于其传输的每个数据包。
具有IDO集的数据包仅被允许传输具有不同请求者 ID 的先前事务,这意味着数据包来自 PCIe 链路上的不同逻辑代理。大多数端点实现(单功能和多功能)都对与往返于其他 PCIe 端点的流量相关的数据排序漠不关心,因为它们通常只与RC通信。同样,大多数RC通常不会在多个端点之间混合相同的流量流,因此在这两种情况下,都没有与其他设备的请求者 ID 相关的排序问题。与此类似,大多数多功能端点对功能之间的数据排序也不关心,因此也不必担心自己的请求者ID之间的排序。因此,大多数实施已经可以为他们发起的所有事务设置IDO。
2.增加应用程序接口
除了上文讨论的因素外,当数据包小于接口宽度时,利用多个较窄的应用程序接口可显著提高整体性能。图 2 显示了新思科技 PCI Express 6.0 控制器IP上64GT/s Flit模式下在发送连续的 Posted TLP流方面的传输链路利用率。对于更大的数据路径宽度,显然需要更大的数据包来通过单个应用程序接口保持完全的链路利用率,1024 位接口需要 128 字节的有效负载。
表 5:显示双半速应用程序接口通过对有效载荷数据使用松弛排序成功
SoC 设计人员可以在其出站数据流中设置RO属性,并显著提高PCIe链路性能。IDO排序属性在许多情况下都具有类似的优势,大多数 PCIe 实现都可以将其应用于其传输的每个数据包。
具有IDO集的数据包仅被允许传输具有不同请求者 ID 的先前事务,这意味着数据包来自 PCIe 链路上的不同逻辑代理。大多数端点实现(单功能和多功能)都对与往返于其他 PCIe 端点的流量相关的数据排序漠不关心,因为它们通常只与RC通信。同样,大多数RC通常不会在多个端点之间混合相同的流量流,因此在这两种情况下,都没有与其他设备的请求者 ID 相关的排序问题。与此类似,大多数多功能端点对功能之间的数据排序也不关心,因此也不必担心自己的请求者ID之间的排序。因此,大多数实施已经可以为他们发起的所有事务设置IDO。
2.增加应用程序接口
除了上文讨论的因素外,当数据包小于接口宽度时,利用多个较窄的应用程序接口可显著提高整体性能。图 2 显示了新思科技 PCI Express 6.0 控制器IP上64GT/s Flit模式下在发送连续的 Posted TLP流方面的传输链路利用率。对于更大的数据路径宽度,显然需要更大的数据包来通过单个应用程序接口保持完全的链路利用率,1024 位接口需要 128 字节的有效负载。
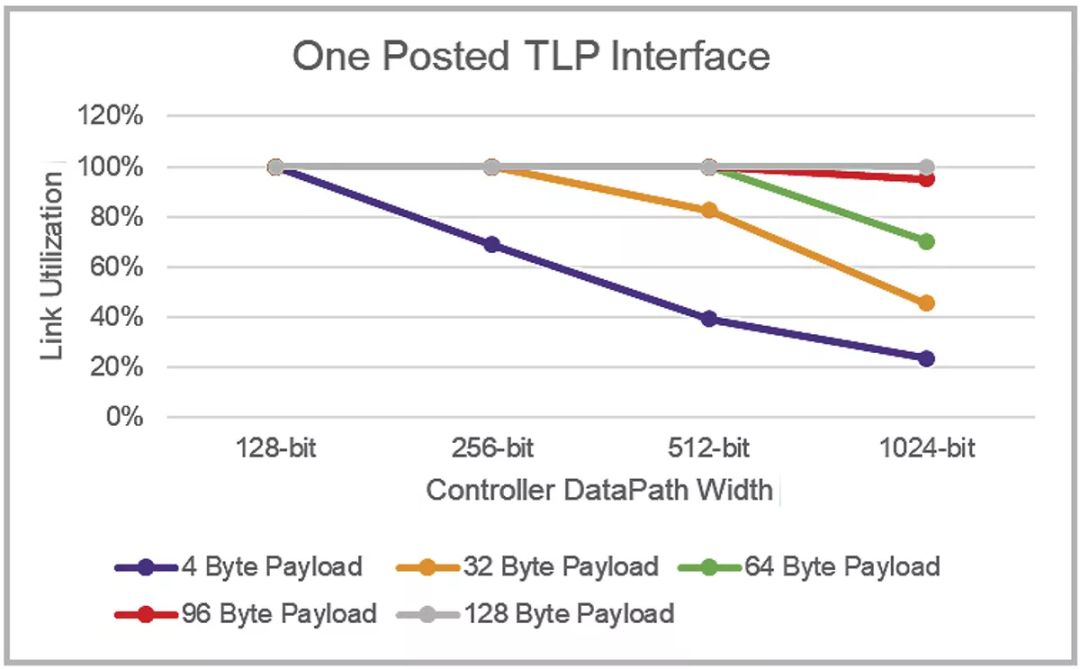 图 2:在 64GT/s FLIT 模式下,利用单个应用程序接口进行传输的各种有效荷载大小和数据路径宽度的链路利用率
3.解决小数据包效率低下
相反,当新思科技控制器配置为两个应用接口并运行相同的流量模式时,就会有明显的改进,现在64字节的有效负载即使在 1024 位数据路径中也能产生完全的链路利用率,如图 3 所示。
图 3:在 64GT/s FLIT 模式下,通过两个应用接口配置进行传输的各种有效载荷大小和数据路径宽度的链路利用率
虽然大多数设备几乎无法控制其流量模式,但小数据包可以实现更少带宽。新思科技 CoreConsultant 使用最大有效负载大小和往返时间 (RTT) 等参数来配置 PCIe 6.0 控制器中的缓冲区大小、突出 PCIe 标签数量和其他关键参数。
图4和图5显示了从新思科技的 64GT/s x4 控制器的仿真中获得的数据。该控制器配置为 512 字节最大有效载荷大小和 1000nS RTT 扫描,覆盖一系列有效载荷大小和 RTT 值。如果在同一范围内重复相同的扫描,但任意一个参数降低,则当扫描通过优化范围后,性能会降低。
图 2:在 64GT/s FLIT 模式下,利用单个应用程序接口进行传输的各种有效荷载大小和数据路径宽度的链路利用率
3.解决小数据包效率低下
相反,当新思科技控制器配置为两个应用接口并运行相同的流量模式时,就会有明显的改进,现在64字节的有效负载即使在 1024 位数据路径中也能产生完全的链路利用率,如图 3 所示。
图 3:在 64GT/s FLIT 模式下,通过两个应用接口配置进行传输的各种有效载荷大小和数据路径宽度的链路利用率
虽然大多数设备几乎无法控制其流量模式,但小数据包可以实现更少带宽。新思科技 CoreConsultant 使用最大有效负载大小和往返时间 (RTT) 等参数来配置 PCIe 6.0 控制器中的缓冲区大小、突出 PCIe 标签数量和其他关键参数。
图4和图5显示了从新思科技的 64GT/s x4 控制器的仿真中获得的数据。该控制器配置为 512 字节最大有效载荷大小和 1000nS RTT 扫描,覆盖一系列有效载荷大小和 RTT 值。如果在同一范围内重复相同的扫描,但任意一个参数降低,则当扫描通过优化范围后,性能会降低。
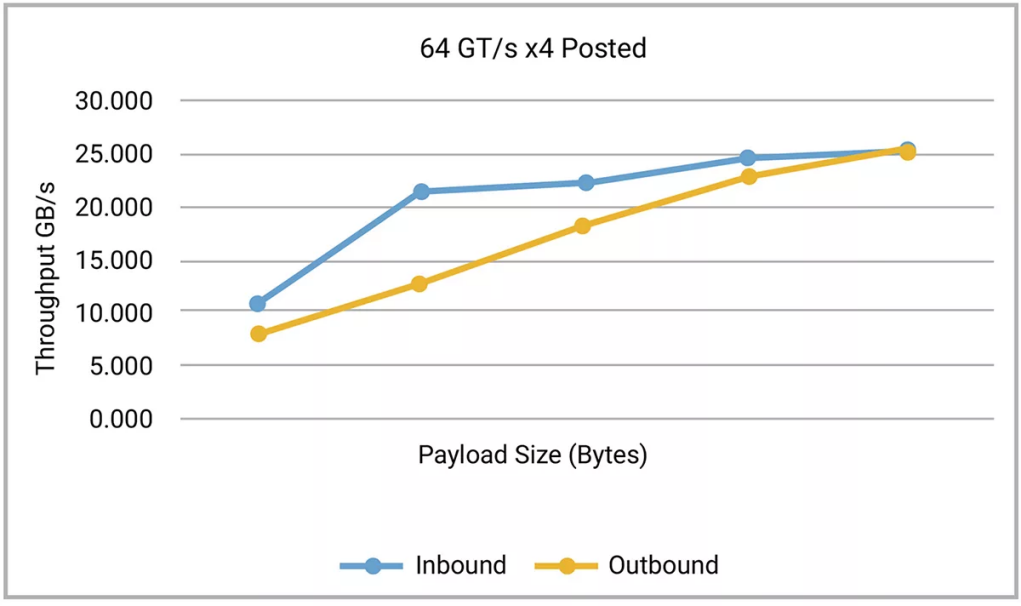 图 4:小尺寸 Posted 数据包效率低下
图 4:小尺寸 Posted 数据包效率低下
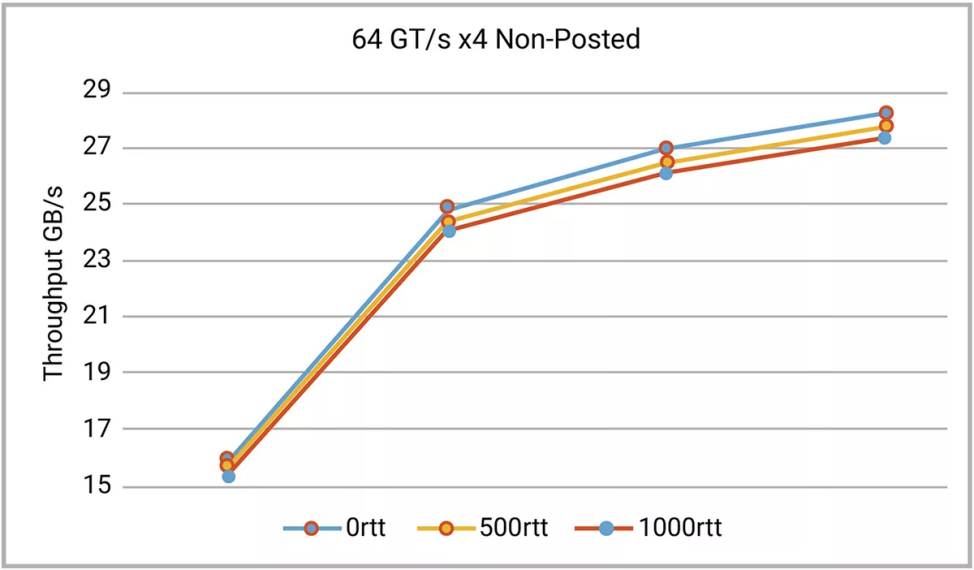 图 5:小尺寸Non-Posted数据包效率低下,在一系列往返时间范围内扫描
总结
实施 64GT/s PCIe 接口的 SoC 设计人员应确保其支持松弛排序属性,即有效载荷而非相关控制上的RO,以及所有数据包上的IDO,除非应用程序有异常要求。这是在整个 64GT/s 生态系统中实现高性能的关键部分。
为x4和更宽链路实施64GT/s PCIe的设计人员需要注意每个时钟周期的多个数据包,并应根据其典型流量大小考虑多个应用接口。
所有64GT/s实施者都应为1GHz(或更快)的设计实现做好准备,并且应确保通过硅前性能模拟检查其假设。
对于上述这些优化设计办法,新思科技提供完整的PCIe 6.0解决方案(包括控制器、PHY 和 VIP)。这些解决方案支持松弛排序属性、PAM-4 信号、FLIT 模式、L0p 电源、高达 1024 位的架构以及多个应用程序接口选项,有助于更轻松地过渡到64GT/s PCIe设计。
图 5:小尺寸Non-Posted数据包效率低下,在一系列往返时间范围内扫描
总结
实施 64GT/s PCIe 接口的 SoC 设计人员应确保其支持松弛排序属性,即有效载荷而非相关控制上的RO,以及所有数据包上的IDO,除非应用程序有异常要求。这是在整个 64GT/s 生态系统中实现高性能的关键部分。
为x4和更宽链路实施64GT/s PCIe的设计人员需要注意每个时钟周期的多个数据包,并应根据其典型流量大小考虑多个应用接口。
所有64GT/s实施者都应为1GHz(或更快)的设计实现做好准备,并且应确保通过硅前性能模拟检查其假设。
对于上述这些优化设计办法,新思科技提供完整的PCIe 6.0解决方案(包括控制器、PHY 和 VIP)。这些解决方案支持松弛排序属性、PAM-4 信号、FLIT 模式、L0p 电源、高达 1024 位的架构以及多个应用程序接口选项,有助于更轻松地过渡到64GT/s PCIe设计。
立即扫码了解更多PCIe 6.0 信息



原文标题:如何破解PCIe 6.0带来的芯片设计新挑战?
文章出处:【微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 新思科技
-
绿色制造带来多种挑战 破解工艺成本难题2009-11-12 1507
-
楷登电子发布PCIe 6.0规范Cadence IP2021-10-26 5569
-
PCIe 6.0的新变化与新挑战2022-04-13 6991
-
PCIe 6.0规范及它是如何从过去的规范演变而来的2022-06-01 3678
-
如何破解PCIe 6.0带来芯片设计新挑战?2023-02-03 2827
-
PCIe 6.0入门之什么是 PCIe 6.02023-05-22 10245
-
新思科技PCIe 6.0 IP与英特尔PCIe 6.0测试芯片实现互操作2023-10-12 1167
-
新思科技成功实现与英特尔PCIe 6.0测试芯片的互操作性2023-10-16 2004
-
下一代PCIe5.0 /6.0技术热潮趋势与测试挑战2024-03-06 3326
-
如何简化PCIe 6.0交换机的设计2024-07-05 2095
-
PCIe 6.0时代的测试挑战和解决方案2025-02-19 2304
-
详解PCIe 6.0中的FLIT模式2025-02-27 4790
-
PCIe 6.0 SSD主控芯片狂飙!PCIe 7.0规范到来!2025-09-07 8996
-
【PCIe 6.0 连载 · 下篇】测试才是关键:PCIe 6.0 如何保证稳定量产?(行业干货)2026-04-22 2182
-
Teledyne LeCroy全面PCIe 6.0测试解决方案获得PCI-SIG认证2026-05-12 333
全部0条评论

快来发表一下你的评论吧 !
