

基于 FPGA 的目标检测网络加速电路设计
可编程逻辑
描述
第一部分 设计概述 /Design Introduction
目前主流的目标检测算法都是用CNN来提取数据特征,而CNN的计算复杂度比传统算 法高出很多。同时随着CNN不断提高的精度,其网络深度与参数的数量也在飞快地增长, 其所需要的计算资源和内存资源也在不断增加。目前通用CPU已经无法满足CNN的计算需 求,如今主要研究大多通过专用集成电路(ASIC),图形处理器(GPU)或者现场可编程门 阵列(FPGA)来构建硬件加速电路,来提升计算CNN的性能。
其中 ASIC 具备高性能、低功耗等特点,但 ASIC 的设计周期长,制造成本高,而 GPU 的并行度高,计算速度快,具有深度流水线结构,非常适合加速卷积神经网络,但与之对 应的是 GPU 有着功耗高,空间占用大等缺点,很多场合对功耗有严格的限制,而 GPU 难 以应用于这类需求。近些年来 FPGA 性能的不断提升,同时 FPGA 具有流水线结构和很强 的并行处理能力,还拥有低功耗、配置方便灵活的特性,可以根据应用需要来编程定制硬 件,已成为研究实现 CNN 硬件加速的热门平台。
综上所述,使用功耗低、并行度高的 FPGA 平台加速 CNN 更容易满足实际应用场景中 的低功耗、实时性要求。而且目标检测算法发展迅速,针对 CNN 的硬件加速研究也大有可 为。所以本项目计划使用 PYNQ-Z2 开发板设计一个硬件电路来加速目标检测算法。
本项目设计的目标检测算法硬件加速电路可以应用在智能导航、视频监测、手机拍照、 门禁识别等诸多方面,比如无人汽车驾驶技术,高铁站为方便乘客进站而普遍采用的人脸 识别系统,以及警察抓捕潜逃罪犯而使用的天网系统等都可以应用本项目的设计,加速目 标检测算法的运算速度以及降低系统的功耗。

在本次项目的设计开发过程中,我们参考 DAC 2019 低功耗目标检测系统设计挑战赛
GPU、FPGA 组双冠军方案,学习到了基于 SkyNet 和 iSmart2 设计一个轻量级神经网络的 技巧,尤其是他们采用的自底向上的硬件电路设计思路给我们带来了巨大的启发。我们在将训练好的神经网络部署在硬件平台的过程中,加深了对 HLS 的理解,开始初步掌握使用 HLS 进行并行性编程的方法。我们学习了 PYNQ 框架,在 PYNQ-Z2 上实现神经网络加速 电路,有了软硬件协同开发的经历。除此之外,我们还学习了 Vitis AI,虽然在项目中并没 有使用到 Vitis Ai,但是对它的学习扩宽的我们的视野。
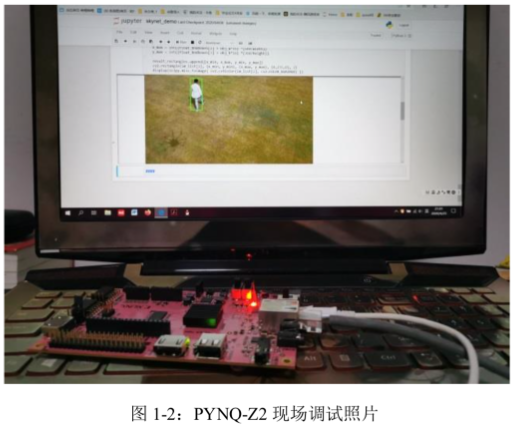
第二部分 系统组成及功能说明 /System Construction & Function Description
本项目针对DAC2019 System Design Contest测试集,计划采用PYNQ-Z2开发板加速目标 检测网络,综合考虑数据访问、存储、并行计算等问题进行优化处理,设计出高速高精度 且低功耗的加速方案,并完成相关仿真和FPGA平台的验证,实现一个可以框选出图像中行 人或其他物体位置的硬件电路。
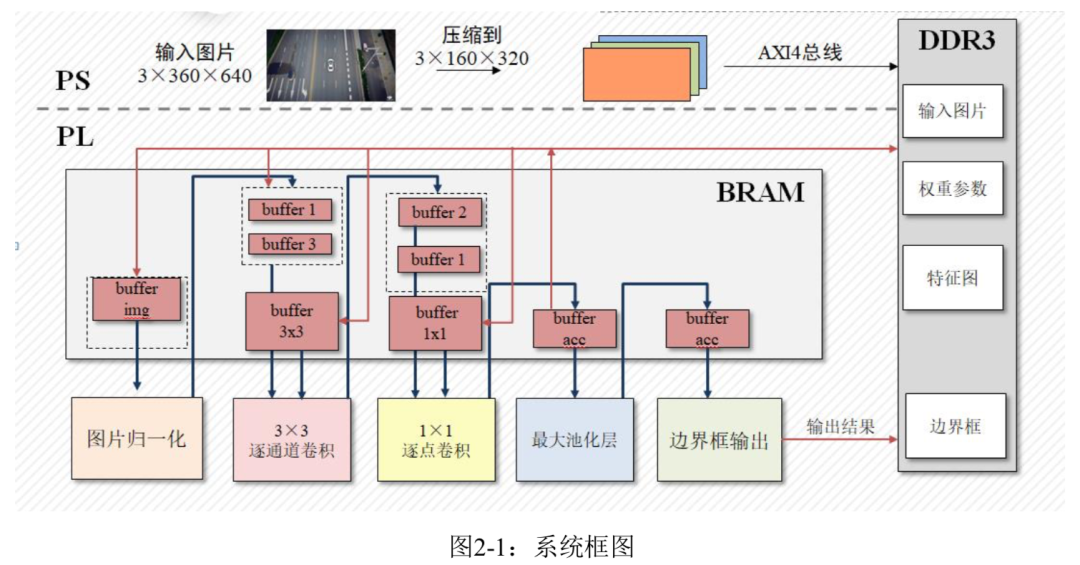
本项目的系统框图如图2-1所示,首先PS端从SD卡读取图片并压缩,之后将图片和参 数权重一起传输到 DRAM中,PL端再从DRAM中读取数据并归一化,经过卷积和池化将输 出特征图传回到DRAM中,再进行下一层卷积运算;直到网络最后一层输出送入到边界框 输出模块中选择置信度最高的边界框传输到DRAM中,供PS端读取。
2.1 神经网络模型的设计方案
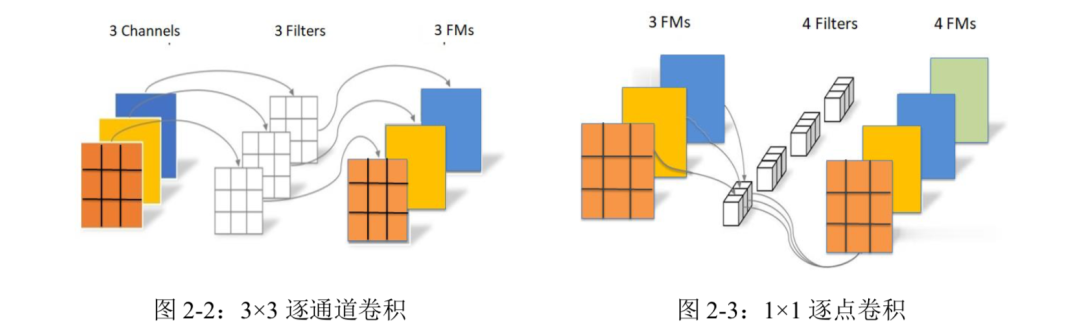
针对 DAC-SDC 数据集并结合 SkyNet 和 iSmart2 网络设计原理,挑选出的基本单元Bundle 由 3×3 逐通道卷积(Depthwise Convolution),1×1 逐点卷积(Pointwise Convolution)和 激活函数 ReLU6 组成。
其中 3×3 逐通道卷积和 1×1 逐点卷积的参数量和计算量远远少于传统的卷积。如图 2-2 和 2-3 所示,首先每个 3×3 逐通道卷积核与各自对应的输入通道数据进行卷积运算,所以 输出通道数等于输入通道数;然后上一步运算得到的特征图继续进行 1×1 逐点卷积,每个 1×1 逐点卷积核对输入的所有通道进行卷积运算,并将结果相加得到一个输出特征图,所以输出通道数等于逐点卷积核的数量。
ReLU6 激活函数与传统的 Relu 激活函数相比,当 ReLU6 函数的输入值大于等于 6 时 输出值恒为 6,可以使模型更快地收敛。同时网络采用大小为 2×2,步长也为 2 的最大池化 层(Max pooling)来降低运算量并防止过拟合,特征图每经过一次最大池化层其宽和高都减小一半。
综上所述本项目构建的神经网络模型如图 2-4 所示:
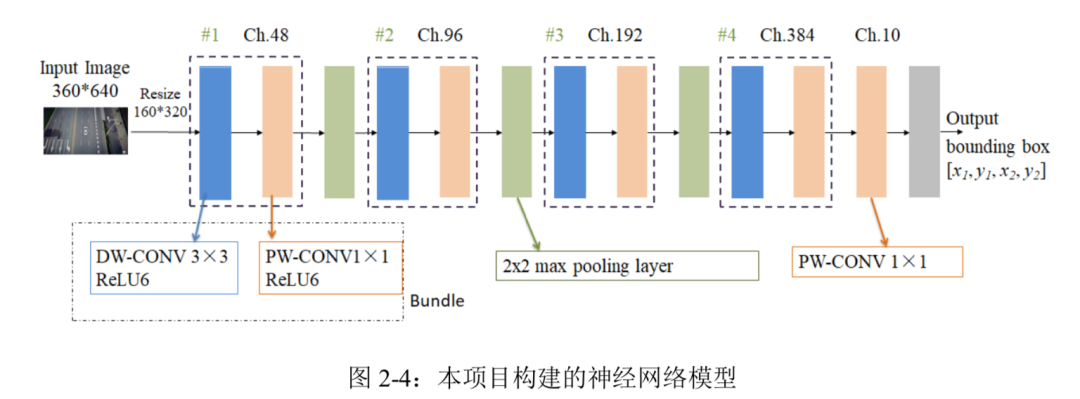
本项目构建的网络模型主要由四个 Bundle 基本单元和三个 Max pooling 层组成,其中每个 Bundle 由 3×3 逐通道卷积,ReLU6 激活函数,1×1 逐点卷积,ReLU6 激活函数依次排 列组成。通过每个 Bundle 中的 1×1 逐点卷积实现输出特征图通道数翻倍,通过 Bundle 其 后紧接着的 Max pooling 层实现输出特征图的尺寸减半。因为数据集内的样本图片分辨率均 为 3×360×640,为了降低计算量就选择将图片压缩到 3×160×320,这个尺寸既可以尽量保 留图片的信息以防止目标检测准确率下降,又可以在神经网络运算过程中很方便地通过 Max pooling 进行降采样。经过三层 Max pooling 后特征图的大小为 20×40,再经过最后一 层 1×1 逐点卷积后输出为 10×20×40,是将输入图片分为 20×40 个分块,又因为输出通道数 为 10,即每个分块将会得到两个边界框和对应的置信度,本项目设计的算法会遍历所有分 块的边界框,选择置信度最大的边界框输出。
2.2 FPGA加速电路设计方案
本项目设计的硬件电路主要有两个模块模块:数据读取与传输模块。首先需要读取图片和模型参数的数据,并对输入的图片数据进行归一化处理,然后送入到卷积运算模块中 进行计算,接着将计算结果送入到边界框输出模块,最后将得到的边界框结果传输到DDR3内存中。
2.2.1 数据读取与传输模块
优化设计一个高效的数据读取与传输模块是完成目标检测任务的前提。首先考虑到FPGA 自身 BRAM 资源有限,所以在数据读取模块中会将每一层的特征图切分成多个数据 块逐次送入到运算模块中进行运算。每个数据块的大小为 20×40,例如将大小为 3×160×320 的输入图片分成 64 个 3×20×40 的数据块。
数据读取时每次读取 3×3 逐通道卷积核参数的大小为 16×3×3,读取 1×1 逐点卷积核参 数的大小则为 16×16,两者均为 16 通道,是因为卷积运算模块为提升运算速度采用了 16 通道并行计算的结构。数据传输过程中将特征图,网络参数通过指针连续地存储在 DDR3 内存中,方便数据存取,提高传输效率。
PYNQ-Z2 的 PS 端通过 AXI4 总线与 PL 端进行通信,AXI4 总线协议具有高性能,高 频率等优势。在 Vivado HLS 中编写硬件代码时需要将输入图片,模型参数和边界框等 PS 端与 PL 端传递数据的接口定义为主或从接口,之后在 Vivado 中自动连线时软件会添加 AXI Interconnect 用于管理总线,并自动为接口分配地址。
在硬件代码编写完成后,需要进行 C 仿真和 C 综合等步骤,最后导出 RTL,可以在导 出的 IP 核驱动的头文件中找到接口的地址,然后在 PS 端开发时将图片和网络参数数据写 入对应地址即可,并从相应的接口地址读取输出数据。
2.2.2 卷积运算模块
设计卷积运算模块来加速卷积运算是 FPGA 加速电路的关键,卷积运算模块由 3×3 逐 通道卷积运算模块和 1×1 逐点卷积运算模块组成。
首先为了让设计的 3×3 逐通道卷积运算模块能够在不同的卷积层间复用,需要保持 3×3 逐通道卷积前后数据块大小不变,这需要对输入和输出数据块进行填充(padding)。输入数 据块原始大小为 20×40,本项目选择 padding=1,则输入数据块大小变为 22×42,经过 3×3 逐通道卷积后高和宽分别为 20 和 40,即输出数据块大小依旧为 20×40。如果接下来还需要 进行 3×3 逐通道卷积,则再对输出进行填充使输出数据块大小也为 22×42,以保持运算过 程中数据块大小不变,这样就能很方便地复用 3×3 逐通道卷积运算模块来节约硬件资源。
因为卷积运算过程中特征图的通道数逐步变为 48,96,192,384,均为 16 的倍数, 所以综合考虑 FPGA 的并行性优点和 PYNQ-Z2 自身资源情况,设计卷积运算模块为 16 个 通道并行计算来提升运算速度。16 通道 3×3 逐通道卷积的输入数据块为 16×22×42,卷积核 为 16×3×3,输出数据块经填充后也为 16×22×42。
因为 3×3 逐通道卷积由乘法和加法运算构成,所以其运算模块需要乘法器,加法器和 寄存器。针对 3×3 逐通道卷积运算模块,以第一个通道为例,首先把偏置
- 相关推荐
- 热点推荐
- FPGA
-
基于紫光同创FPGA的多路视频采集与AI轻量化加速的实时目标检测系统2023-11-02 1333
-
基于 FPGA 的目标检测网络加速电路设计2023-06-20 981
-
FPGA CPLD数字电路设计经验分享.2021-09-18 1462
-
基于FPGA的SIMD卷积神经网络加速器2021-05-28 1367
-
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计2020-09-25 1047
-
FPGA的硬件电路设计教程和FPGA平台资料简介2020-07-06 2487
-
电路设计[FPGA]设计经验分享2019-01-03 2918
-
毕设求助(可以有偿)——基于FPGA的LFMCW雷达多目标检测方法2018-04-08 3022
-
DSP和FPGA的HDLC协议通讯电路设计2017-10-19 1228
-
基于FPGA的压电陀螺数字化检测电路设计_李国斌2017-03-19 715
-
基于FPGA的串口通信电路设计2017-01-24 876
-
诚聘传感器器件检测电路设计(RPO)2016-11-30 2507
-
基于FPGA的惯性平台测试保护电路设计2016-01-04 607
-
电路设计[FPGA]设计经验2012-05-23 7667
全部0条评论

快来发表一下你的评论吧 !
