

基于端到端可操作性学习的机器人操纵框架
描述
导 读
本文是国际机器人和自动化顶级会议 ICRA 2023入选论文 RLAfford:End-to-end Affordance Learning for Robotic Manipulation 的解读。这项研究通过使用强化学习训练过程中产生的接触信息来预测物体可操作性信息,更好地实现机器人***任务,并对各种算法以及环境具有即插即用的能力。
01
研究背景
随着生活逐渐智能化,通过机器人与物体交互变得越来越重要。如何让机器人学会***不同形状的物体并且学会稳定有效的交互策略成为了当前的研究热点。近年来,强化学习(RL)为这一问题提供了解决方案。然而,在互动环境中学习***不同形状、不同结构、不同功能的三维物体一直是强化学习的挑战。特别是,我们往往很难训练出一个能够处理不同语义类别、不同几何形状和多样功能的物体的策略。
最近,视觉可操作性(Visual Affordance)学习技术在提供以物体为中心的信息先验和有效的可操作语义方面展现出巨大的潜力。例如,一个理想的策略可以通过了解到把手的可操作性来打开一扇门。然而,学习视觉可操作性往往需要人类定义的原子动作(抓、握、推、拉等动作),这限制了适用任务的范围。
在本文中,我们提出了 RLAfford。在研究中,我们抓住了智能体与世界交互的最本质信息:接触点信息,来预测 RL 系统感兴趣的物体上的接触位置(也即物体的可操作性),预测的信息又反过来指导 RL 进一步训练。这样的接触预测系统实现了端到端(End-to-end)的 Visual Affordance 学习框架,它可以广泛地适用于不同类型的***任务中。
令人兴奋的是,我们的框架甚至在多阶段(Multi-stage)和多智能体(Multi-agent)的任务中也能保持有效性。我们在八种类型的***任务上测试了我们的方法。结果显示,我们的方法在成功率上远远超过了基线(Baseline)算法,同时,我们的方法成功地在现实世界中成功完成了这八种***任务。部分 Visual Affordance 学习结果如图1所示。
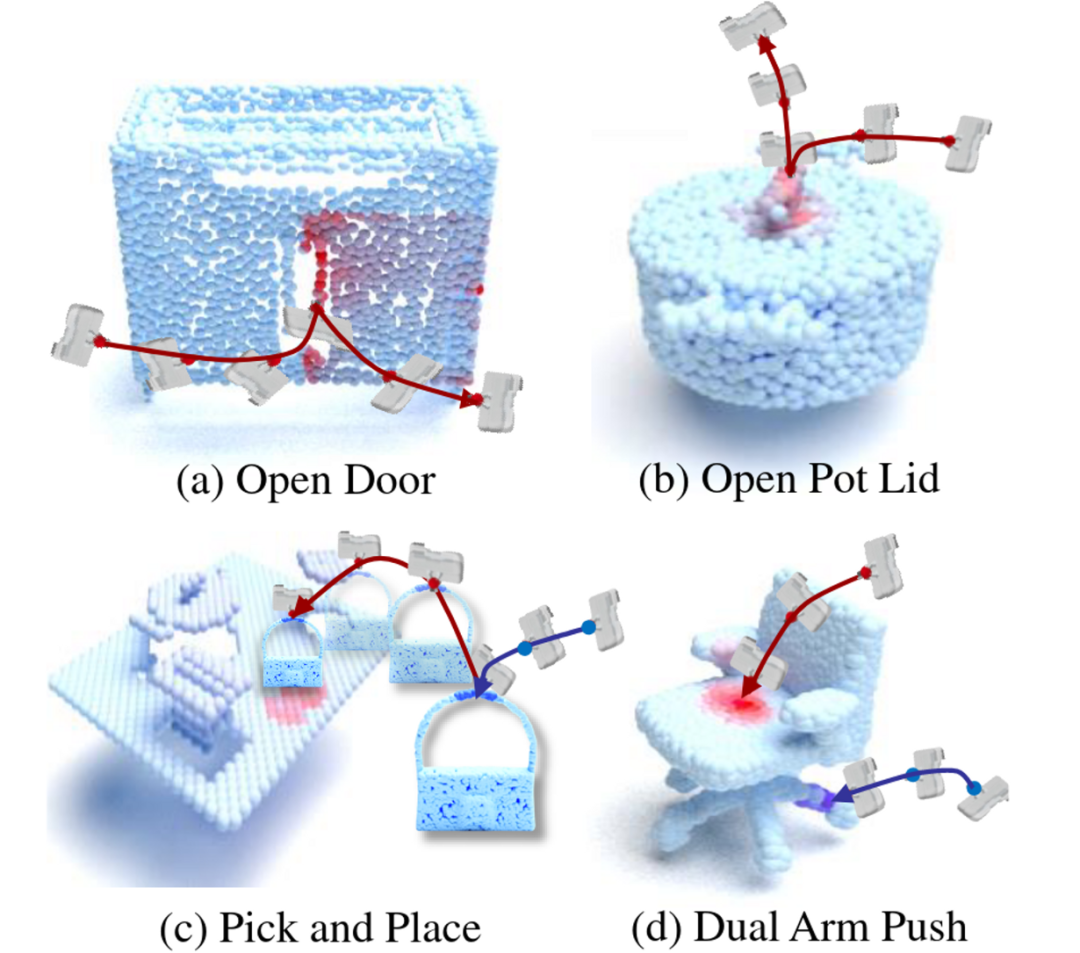
图1. 输入一个物体的点云信息,我们利用 RL 交互过程中的接触信息来预测以物体为中心的可操作性信息。图中颜色越深意味着可操作性越强。可以看出,这样的信息对于完成物体操作非常有意义。
02
方 法
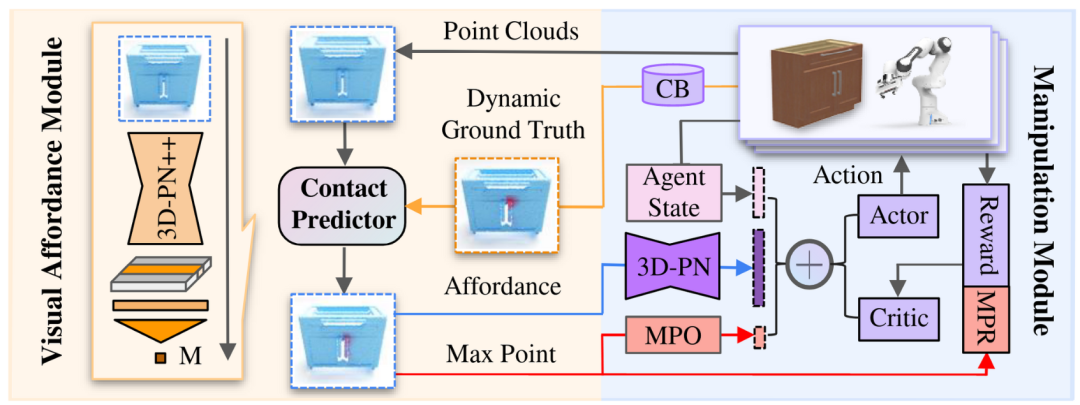
图2. 框架结构。
如图2所示,我们的方案包含两个主要模块。其中 1)操作模块(Manipulation Module)生成交互轨迹,2)视觉可操作性模块(Visual Affordance Module)用来学习生成基于实时点云的可操作性信息(Affordance)。接触预测器(Contact Predictor)在两个模块***享,作为它们之间的桥梁。
操作模块使用接触预测器的预测结果作为输入观察的一部分,同时预测的最大值点参与操作模块的奖励函数计算(MPR),以激励 RL 算法去探索最感兴趣的点附近的区域;
操作模块通过收集交互中的碰撞信息实时生成动态的 Visual Affordance 学习目标(Dynamic Ground Truth)来训练视觉可操作性模块。
具体算法结构如图3所示。

图3. 算法结构。
03
实 验

图4. 顶部:模拟器中的任务设置。中间:在端到端训练期间,Visual Affordance Map 的变化以及部分 Visual Affordance 学习结果。底部:真实世界实验示意图。
如图4所示,我们设计了三种类型的***任务:单阶段、多阶段和多智能体。在所有的任务中,都要求一个或两个机械臂来完成对不同物体的特定***任务。我们使用了 Isaac Gym 物理模拟器、PartNet-Mobility 数据集和 VAPO 数据集来完成虚拟环境的实验。我们也利用了数字孪生方法在真实世界中完成了我们设计的任务。最终,我们进行了一些消融实验,实验结果表明我们的方法在成功率上远远超过了基线算法,包括基于 Visual Affordance 的方法和 RL 方法。
04
总 结
据我们所知,这是第一项将 Visual Affordance 与 RL 完成端到端的结合的工作。在 RL 训练中,Visual Affordance 可以通过提供额外的观测和奖励信号来提高策略学习的效果。我们的框架通过 RL 训练自动学习 Visual Affordance 语义,而不需要额外的演示或人工标注。我们方法的简单性、比所有基线更出色的性能以及广泛灵活的适用场景,证明了我们的方案的有效性以及对各种算法、环境具有即插即用的能力,同时也为解决更多复杂任务打开了一种新的思路。
审核编辑:刘清
-
双臂协作机器人的应用场景2023-06-27 2492
-
浅谈儿童陪护机器人2023-05-11 1183
-
#机器人基础原理 奇异及可操作性第1部分电子技术那些事儿 2022-09-21
-
深圳CCD点钻系统,视觉对位算法,可操作性好2021-07-27 745
-
深圳视觉对位雕刻机系统,软件可操作性好2021-07-22 943
-
机器宠物解决方案开源资料(原理图+源码+视频演示)2020-10-12 4740
-
HPC应用程序高性能分析及如何使用系统资源的可操作性洞察2018-11-08 4754
-
高通、诺基亚完成基于全球5G NR标准的端到端互操作性连接测试2018-02-08 5602
-
【orangepi zero申请】画图机器人控制端2016-12-09 2555
-
智能小车机器人控制端V2.022015-04-12 6692
-
什么是工业机器人2015-01-19 6815
-
蓝牙控制机器人端2013-07-20 4814
-
水下机器人便携式遥控单元设计2011-03-08 10046
-
TD-LTE完成全球首个端到端互操作性试验2010-04-25 813
全部0条评论

快来发表一下你的评论吧 !
