

AMU与PMU有哪些差异点呢?
描述
1. AMU简介
AMU是ActivityMonitor Unit的缩写,在Arm v8.4架构中引入。从Arm文档描述来看,AMU与PMU(PerformanceMonitor Unit)有类似的性能监控功能,但其设计初衷是为了系统管理,而PMU的用途是用户态程序或者调试功能。AMU可以为系统性能、功耗管理提供持续不断的监控并获取非常有用的信息。
在介绍AMU之前,先介绍下PMU几个基本概念,对了解AMU会有所帮助。PMU用于跟踪、统计系统内部的一些底层硬件事件,这些事件反映了程序在CPU上执行的行为,可以帮助我们对程序进行分析和调优:
Event,即事件,例如CPU相关的事件包括执行指令数,时钟周期等,cache相关的事件包括各级cache访问、refill计数等,以及与TLB有关的事件等。每个event都有一个特定的eventid。
Counter,事件计数器,数量固定,以Cortex-A53为例,一共有1+6个Counter,CycleCounter只用于记录CPU Cycle数,另外6个Counter是可配置的Counter,根据配置选择的Event进行计数。当计数器发生溢出时,计数器会产生overflow中断。
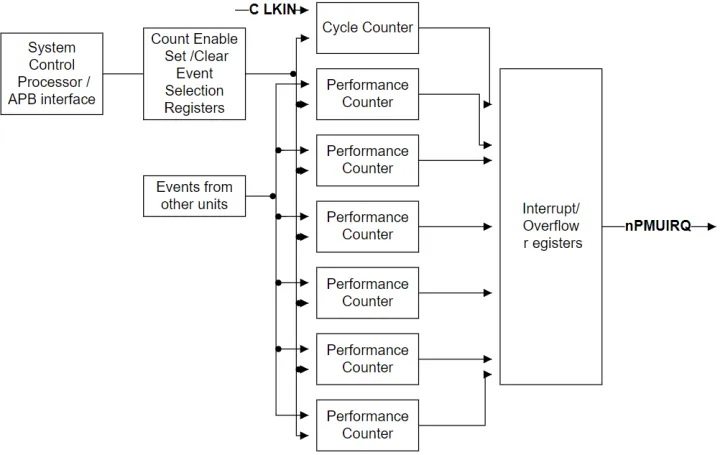
AMUv1架构定义(architecturally defined)4个固定的EventCounter,分别是:

既然是架构规定要实现的,那么一定是被经常用到的Event。未来可能会增加固定Counter的数量,AMU最多可支持16个固定Counter。
除了固定Counter,还支持最多16个辅助的Counter,这些Counter可以做成固定的也可以是可配置的,取决于具体实现。所有AMUEvent Counter都是64位的,在溢出时没有提示或者中断。
2. AMU寄存器
AMU寄存器如下图所列,
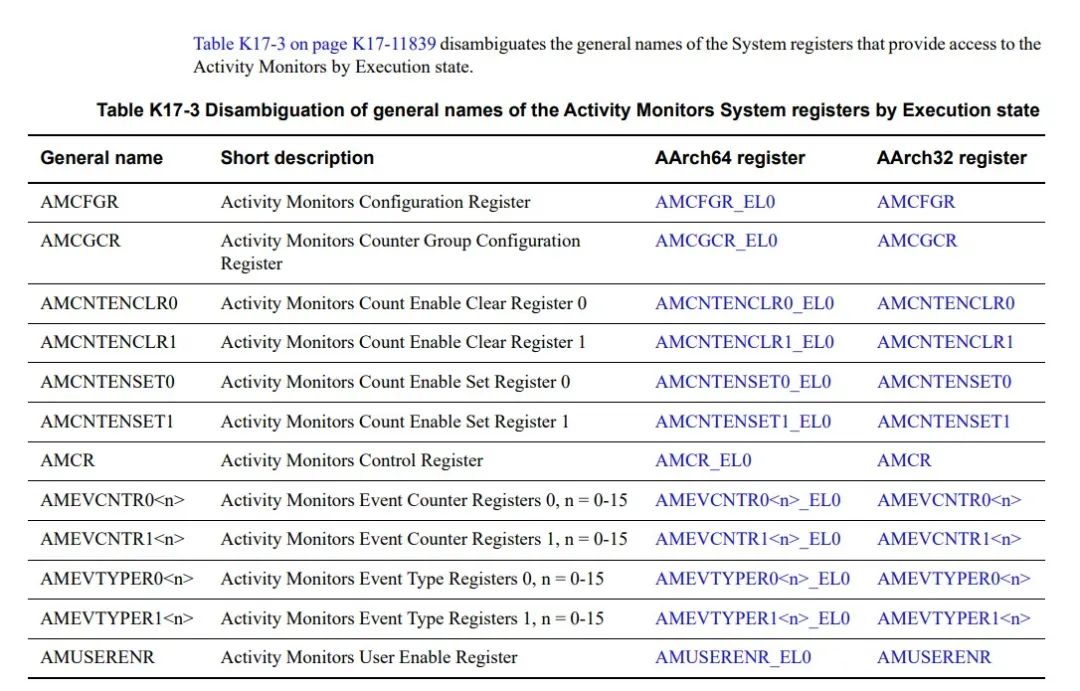
AMU寄存器通过systemregister接口MRS和MSR指令进行访问。
访问控制
可通过配置控制是否允许更低EL级别访问AMU寄存器。AMUSERENR_EL0.ENbit控制EL0访问AMU寄存器,可在EL1,EL2,EL3中配置。CPTR_EL2.TAMbit控制来自EL0和EL1的访问,CPTR_EL3.TAMbit控制来自EL0,EL1和EL2的访问。其他的配置,只允许在最高的EL级别中进行。
Counter寄存器

Counter寄存器都有以下特点:
都是64位寄存器,并且overflow时不产生状态提示或者中断;
CPU复位后Counter寄存器值恢复为0;
Event Type寄存器

EventType寄存器配置了各Counter对哪个event进行计数,这点与PMU的PMEVTYPER
AMCNTENSET0_EL0/AMCNTENCLR0_EL0可对各Counterenable/disable进行控制,其他寄存器含义可参考ARM文档,这里不一一介绍。
3. 代码实现
在Kernel中通过CONFIG_ARM64_AMU_EXTN宏进行AMU代码控制,Kernel最早支持AMU的功能,在这个patch中:
arm64: add support for the AMU extension v1
在arch/arm64/include/asm/sysreg.h中定义了AMU各寄存器的地址
/* Definitions for system register interface to AMU for ARMv8.4 onwards */ #define SYS_AM_EL0(crm, op2) sys_reg(3, 3, 13, (crm), (op2)) #define SYS_AMCR_EL0 SYS_AM_EL0(2, 0) #define SYS_AMCFGR_EL0 SYS_AM_EL0(2, 1) #define SYS_AMCGCR_EL0 SYS_AM_EL0(2, 2) #define SYS_AMUSERENR_EL0 SYS_AM_EL0(2, 3) #define SYS_AMCNTENCLR0_EL0 SYS_AM_EL0(2, 4) #define SYS_AMCNTENSET0_EL0 SYS_AM_EL0(2, 5) #define SYS_AMCNTENCLR1_EL0 SYS_AM_EL0(3, 0) #define SYS_AMCNTENSET1_EL0 SYS_AM_EL0(3, 1) #define SYS_AMEVCNTR0_EL0(n) SYS_AM_EL0(4 + ((n) >> 3), (n) & 7) #define SYS_AMEVTYPER0_EL0(n) SYS_AM_EL0(6 + ((n) >> 3), (n) & 7) #define SYS_AMEVCNTR1_EL0(n) SYS_AM_EL0(12 + ((n) >> 3), (n) & 7) #define SYS_AMEVTYPER1_EL0(n) SYS_AM_EL0(14 + ((n) >> 3), (n) & 7) /* AMU v1: Fixed (architecturally defined) activity monitors */ #define SYS_AMEVCNTR0_CORE_EL0 SYS_AMEVCNTR0_EL0(0) #define SYS_AMEVCNTR0_CONST_EL0 SYS_AMEVCNTR0_EL0(1) #define SYS_AMEVCNTR0_INST_RET_EL0 SYS_AMEVCNTR0_EL0(2) #define SYS_AMEVCNTR0_MEM_STALL SYS_AMEVCNTR0_EL0(3)
在arm-trusted-firmware中,也有AMU寄存器读写相关代码,还包括上下电时AMU备份恢复的操作,代码主要在lib/extensions/amu/aarch64/和lib/cpus/aarch64/cpuamu_helpers.S。
4. AMU的应用
在内核中有这么一个patch,目的是为了让调度LoadTracking的FIE计算更准确,
arm64: use activity monitors for frequency invariance
在此之前,Kernel中的freq scale计算都是通过cpufreq模块记录的当前频率和最大频率来计算的,但是实际频率可能在Kernel之外的地方发生变化,与Kernel cpufreq模块记录的当前频率不同,或者支持ACPI的cpufreq driver是不知道当前频率的。因此AMU就为获取CPU平均频率提供了一个方法。通过CPU_CYCLES和CNT_CYCLES的Counter计数来计算CPU频率,具体代码如下。
arch/arm64/kernel/topology.c
/* Initialize counter reference per-cpu variables for the current
CPU */
void init_cpu_freq_invariance_counters(void)
{
this_cpu_write(arch_core_cycles_prev,
read_sysreg_s(SYS_AMEVCNTR0_CORE_EL0));
this_cpu_write(arch_const_cycles_prev,
read_sysreg_s(SYS_AMEVCNTR0_CONST_EL0));
}
void topology_scale_freq_tick(void)
{
u64 prev_core_cnt, prev_const_cnt;
u64 core_cnt, const_cnt, scale;
int cpu =
smp_processor_id();
if
(!amu_freq_invariant())
return;
if
(!cpumask_test_cpu(cpu, amu_fie_cpus))
return;
const_cnt =
read_sysreg_s(SYS_AMEVCNTR0_CONST_EL0);
core_cnt = read_sysreg_s(SYS_AMEVCNTR0_CORE_EL0);
prev_const_cnt =
this_cpu_read(arch_const_cycles_prev);
prev_core_cnt =
this_cpu_read(arch_core_cycles_prev);
if (unlikely(core_cnt
<= prev_core_cnt ||
const_cnt <= prev_const_cnt))
goto
store_and_exit;
/*
* /core arch_max_freq_scale
* scale = ------- * --------------------
* /const SCHED_CAPACITY_SCALE
*
* See validate_cpu_freq_invariance_counters()
for details on
* arch_max_freq_scale and the use of
SCHED_CAPACITY_SHIFT。
*/
scale = core_cnt -
prev_core_cnt;
scale *=
this_cpu_read(arch_max_freq_scale);
scale = div64_u64(scale
>> SCHED_CAPACITY_SHIFT,
const_cnt - prev_const_cnt);
scale = min_t(unsigned
long, scale, SCHED_CAPACITY_SCALE);
this_cpu_write(freq_scale, (unsigned long)scale);
store_and_exit:
this_cpu_write(arch_core_cycles_prev, core_cnt);
this_cpu_write(arch_const_cycles_prev, const_cnt);
}
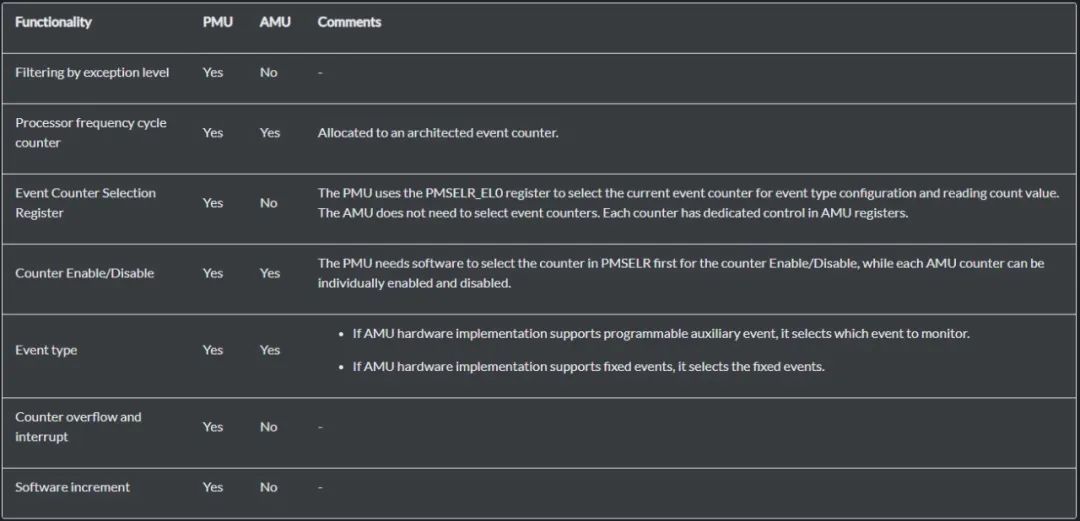
5. AMU与PMU的区别
前文提到AMU与PMU的设计目的不同。除此之外,还有哪些差异点呢?
AMU与PMU具有类似的特性,设计的目的有所不同,AMU是为了系统功耗性能管理,PMU是为了用户态程序或者调试目的。从硬件角度都是对事件进行计数,我们同样也可以使用PMU的统计结果进行功耗和性能管理,为什么还要再引入AMU呢?
可能的原因是,PMU有多个使用场景,如果在性能功耗管理方案上使用了PMU,那么在性能调试时也要获取PMU信息就可能产生冲突,例如使用强大的perf工具抓取PMU信息,尤其在Counter数量有限的情况下,冲突概率更大。引入AMU是为了给固定的资源专门用来做系统控制方案,从而释放PMU资源用作其他目的。
PMU和AMU的软件使用方式上,也有很大的不同。AMU通过system register interface就可以访问,而PMU需要通过内核的perf接口,软件开销远超过AMU。
下图列出了两者功能上的一些差异,
审核编辑:刘清
- 相关推荐
- 热点推荐
- 寄存器
- cpu
- 计数器
- Cortex-A53
-
eMMC与UFS它们之间到底有什么差异呢?2021-06-18 2115
-
STM32的三种Boot模式有何差异呢2021-11-26 2576
-
STM8和STM32的内核有什么差异呢2022-02-23 1867
-
如何对Android 7.1 RK3288 PMU进行调试呢2022-03-04 1337
-
那么AMU和PMU有什么不同呢?2023-02-03 2489
-
一文浅析AMU和PMU的区别2023-02-15 3384
-
Revere AMU系统架构参考指南2023-08-10 678
-
TinyM0配套例程 PMU例程2010-11-15 550
-
PMU基本介绍2017-01-22 2025
-
PMU测试仪的设计与研究2017-08-29 1428
-
PMU量测点优化配置新方法2018-04-17 1428
-
如何使用WEBENCH PMU优化电源设计?2018-08-20 4585
-
你知道PMU与PMU也是有区别的吗2020-10-25 16149
-
雷达信号有什么特点?和通信信号的差异在哪里呢?2021-03-04 15801
全部0条评论

快来发表一下你的评论吧 !
