

一文搞懂神经隐式SLAM方法
人工智能
描述
相关工作
(TSDF-Fusion, DI-Fusion) 首先介绍一下这个TSDF-Fusion,这个是一种非常经典的显示表达,最早于1996年提出。它是在每一个voxtel里面都会存TSDF值,也可以存颜色值。存储的是在一个很密集的一个个网格中,其保存的几何清晰程度与网格的分辨率相关。如果我们想得到一个比较好的结果,即不在TSDF这一步出现精度损失的话,那么则需要一般512左右的分辨率,也就是说要存512*512*512这么多个网格数据。更新方式如图1所示,是通过带DS图来进行融合更新。
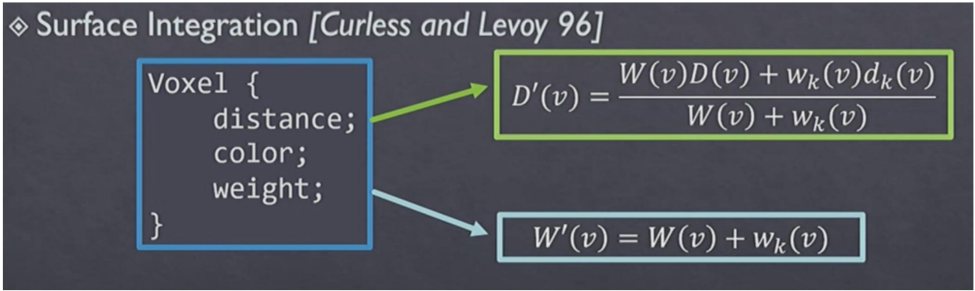
图1 TSDF更新方式 然后我们讲一个非常新的方法是DI-Fusion,分为mapping跟tracking这两个部分。Mapping部分是是单纯前向计算的方法,并不急于优化,而是提前已经训练好编码层和解码层。 编码层输入的就是点的体素范围内的点坐标和法线,然后进行编码后得到一个特征,再通过解码出来这个SDF的值。如果是续接有很多张深度图,则在训练时候已经加入这个更新的过程,来更新特征。tracking有两部分: SDF的loss和基于颜色的intensity warp loss。 基于几何SDF的loss是最小化当前输入的深度图,根据带优化的相机外参反投到点云对应的SDF值,然后这个SDF值按理说是应该接近于0, 所以我们就最小化SDF值。SDF值可以由特征通过解码层得到。基于颜色的优化目标是当前帧的图片根据这个带优化的相机外参wrap到前一帧对应的颜色应该是相同的。
IMAP
IMF的动机是要做一个输入为RGB-D的,只用MLP作为场景唯一表达的实时的SLAM系统。这篇文章主要有3个创新点,首先它是第一个用神经影视表达的稠密实时SLAM系统,同时能够同时优化整个的MLP表达的三维地图。其次它是能够增强隐式神经网络的训练,还能够进行关键帧选择和loss指导采样上。最后,它是并行实现的,能直接的连上RGB-D相机从而在线跑数据。
接下来讲一下这个system overview,如图2所示。
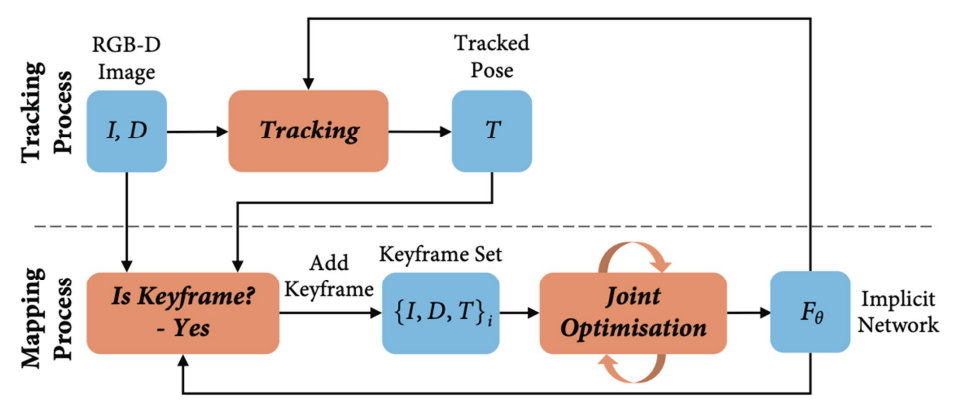
图2 IMF系统概述 上面一行是tracking,下面一行是mapping。tracking是对于新来的每一帧都要优化出它的相机位置,这个tracked pose就是他优化好的相机位置,现在判断新来的这一帧是不是keyframe,如果是的话,则加入keyframe set里面。之后,更新隐式的表达和相机的参数。他使用的是一个单MLP的结构,feature size为256,输出是和nerf一样的color和volume density,可以渲染deeps图和color图。 首先是occupancy probability:,这个是通过一个类似激活函数的变换,得到occupancy,之后就能计算光线到这个点的截止概率,然后我们得到这个权重(类似一个加权平均),如果加到这个deeps上,其实就渲染一张deeps图。如果是加到颜色上的,那么就可以把这个颜色图给渲染出来。此外还要算一个是deeps variance:, 这个是整条ray上深度的方差,即对每个采样点求方差再加权。 接下来看看这个Joint optimization和camera tracking。前一个是用在mapping里,后一个是前端的那个tracking。Joint optimization是隐式表达几何的MLP的所有参数和选中的这些keyframe的相机外参。 光度损失为,然后将所有像素光损失平均起来就是,几何损失也一样。 同时这两个损失之间是有一个平衡权重,也就是我们最小化的一个目标,θ是整个MLP的参数,ti的集合是所有相机的外参。 接下来讲解keyframe selection。先假设每一次已经有一个新keyframe已经加载完成,我们拿到当前整个网络参数的备份就类似当前地图的一个快照,然后我们每新来的一帧,就从这个快照里面渲染一张depth图。它不需要渲染整个depth图,就能得到统计规律。 所以渲染一部分depth的pixel就跟grand truth的depth pixel相减,然后看这一帧这多少区域是已被lock区域表达。如果小于这个阈值,则说明这一帧看的地方是比较新的,那么就把它加到keyframe list或者keyframe set里面。 IMF还有一个比较好的贡献是active sampling。首先是image active sampling,就比如 我们要把一张待优化的图片,可以将它分成一个个bin,先均匀采样并渲染出来,得到loss的分布,若loss相差较大则根据lost distribution来分配每个bin中的pixel数量。另外一个是keyframe active sampling,首先它是有一个全局的keyframe set,但每次mapping的时候,只选常数个frame,这个选法是能设计一种机制或随机选,然后加入到mapping中。 然后讲一下他的实验部分,首先这个就是他渲染出来的结果还有keyframe tracking跟ground truth之间的对比。首先它是跟TSDF fusion进行的比较,但TSDF fusion只是一个mapping的方法,所以要给一个相机位置。这样跑完之后可以发现就是TSDF fusion的accuracy是最低的,加粗的就代表是最好的结果。
NICE-SLAM
接下来讲解这个NICE SLAM,这个是CVPR2022的一个方法。先看一下这个demo,给定手持相机捕获的RGB-D序列,NICE SLAM可以在大规模的室内场景中生成密集的集合以及准确的相机跟踪,实现这一点的关键组件是神经隐式表达,给定空间中的点p来训练神经网络,以表示该点的不同场景属性。例如有符号、距离场或颜色值。
神经隐式表达可以捕获高保真的几何,然后还可以渲染很高清晰度的图片,然而,几乎所有这种方法都被认为是离线的工具,通常需要数小时或者数天的训练或者优化,并且是已知相机位置的。IMAP首次展示了使用单个多层感知器及MLP作为神经隐式场景表达的在线RGB-D SLAM system,对于这样一个小房间,IMAP可以持续学习的方式进行同时估计相机位姿和密集的场景几何。但他们使用单个大MLP作为场景的唯一表达,因此存在以下问题。 首先,由于容量有限,当场景变大时IMAF会失败。其次,每个新的输入RGB-D帧都可以更新整个MLP,因此会遇到遗忘的问题。最后,优化整个MLP非常慢,尤其是当MLP变得很大时。 相比之下,NICE SLAM对场景表达进行了简单而非常有效的改进,NICE SLAM优化分层特征网格,并结合不同空间层级下域训练的微型MLP的归纳偏差,使用这种表达,使得NICE SLAM在大规模室内场景中表现良好,解决了网络遗忘问题,同时保证了更少的运行时间,可以快速收敛。 接下来介绍这个系统的pipeline,如图3所示。
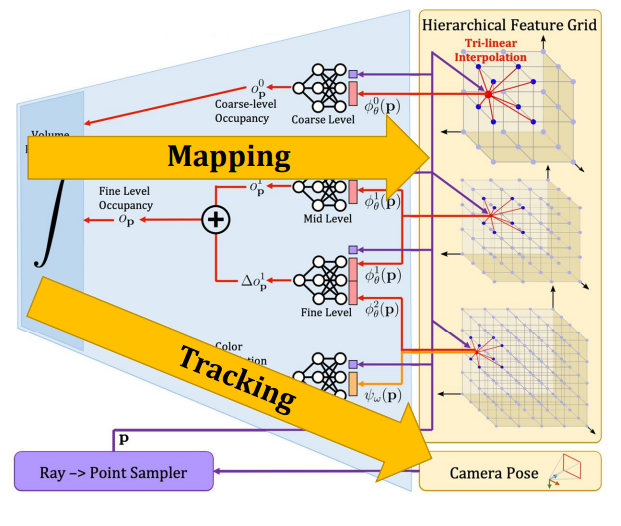
图3 NICE SLAM整体框架 给定RGB-D序列,NICE SLAM能同时估计相机位姿和场景的三维几何,即表示为分层特征网格。首先根据相机参数随机采样射线,沿每条射线,进行3维点的采样,并使用3线形插值提取每个点的特征,接着使用微型的MLP预测光线上三维点的占用值跟颜色值,最终使用类似nerf的体渲染方程,沿射线去核,生成深度跟彩色图像。 我们关注输入跟生成图像之间的重渲染损失,由于渲染过程是可微的,能够以交替方式反向求导最小化重渲染损失,通过优化分层特征网格来实现建图(也就是mapping),通过优化相机参数来实现跟踪。 这个微型MLP的解码器是作为网络的一部分进行了预训练,occupancy network由一个CNN的编码器和一个MLP的解码器组成,与其相同,我们在训练的时候也是使用了预测值跟真实值之间的交叉商损失来训练编码器解码器。训练后NICE SLAM使用解码器MLP,这样在优化特征网格时,预训练的解码器可以利用从训练集中学习到的特定先验来指导优化。 接下来仔细讲讲,在图3中,首先coarse level对应的网格的分辨率是比较大的,会单独的出一个occupancy,也是单独会渲染一张coarse的depth图,是只用在没有观测到的那部分的几何上,但训练是用观测到的depth图来进行训练。然后中间的这层,首先是middle level,它对应的是一个分辨率中等的一个特征网格,从中拿到feature和点坐标,然后经过MLP得到了一个occupancy值,我们的fine-level是在他基础上要预测出来一个residual,那么他是从更高的分辨率里去得到feature,同时他还把中等分辨率结合起来通过MLP,这两个occupancy就叠加起来,得到这个fine level occupancy。 最终是颜色,它是要需要分辨率比较高的网格,而且高频的细节比较多,我们是只从这个features grid里面取到feature,然后跟点坐标经过MLP,拿到color prediction。我们最终是通过这个渲染,跟nerf一样的渲染器,能渲染出来depth跟colorful。需要注意的是这个几何MLP是进行局部的更新。 下面来看一些结果。首先,在replica数据集与复现的IMAP进行比较,即使在较小的室内场景中,NICE-SLAM也能产生更准确的几何和相机的跟踪。接下来是一个相对比较难一点的ScanNet数据集,相比于IMAP跟DIF fusion,我们的相机跟踪更为稳健。 与IMAP相比,NICE SLAM新颖的场景表示不仅提高了建图和跟踪的质量,同时需要更少的计算,从图4中可以看出,NICE SLAM只需要IMAP 1/4的flops。而值得一提的是,即使对于非常大的场景,NICE SLAM所需要的flops也保持不变,这是因为我们只在当前相机视锥内的这些feature我们进行优化。相反由于IMAP使用单个MLP,MLP容量限制导致其在处理更大型的场景时会需要更多的参数,从而会导致更多的flopes。
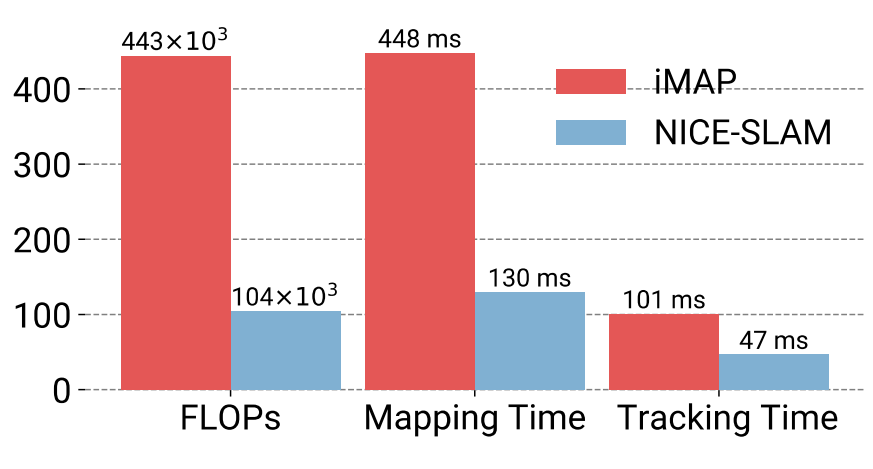
图4 计算复杂度对比
未来工作
接下来讲讲神经隐式表达未来的一些工作。首先加入loop closer,这个是一个比较难加的一个东西,尤其是在场景很大的时候。其次如何加入Global BA是一个很有意思的点。 同时我们可以自适应的去分配voxels。如果是能延展到室外场景就更好了,因为室外场景会影响key next sensor,所以我们得看看怎么样。还有一点期望是怎么样能让相机的跟踪比传统方法还好或者跟传统方法一样好。
编辑:黄飞
-
动态环境中基于神经隐式表示的RGB-D SLAM2024-01-17 1832
-
一文搞懂UPS主要内容2021-09-15 2033
-
一文搞懂开关电源波纹的产生2021-12-30 2598
-
网络隐通道的构建方法研究2009-03-31 580
-
基于隐式PIGPC的网络控制系统时延补偿方法2017-01-07 844
-
一种具有分级安全的文本隐写方法2018-01-14 649
-
LSTM隐层神经元结构分析,及应用的程序详细概述2018-07-29 10101
-
一文搞懂几种常见的射频电路类型及主要指标2020-07-27 1560
-
基于三维激光数据的层级式SLAM方法2021-04-20 3056
-
基于机器学习的中文隐式实体关系抽取方法2021-06-02 781
-
GTC 2023:3D技术位姿估计与预处理、 神经隐式曲面建模加速2023-03-24 2322
-
用于神经场SLAM的矢量化对象建图2023-06-15 1794
-
基于几何分析的神经辐射场编辑方法2023-11-20 1557
-
一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统2023-11-29 1739
全部0条评论

快来发表一下你的评论吧 !
