

基于DNN模型的ADS深度学习算法选型探讨
电子说
描述
对于自动驾驶ADS行业而言,其核心演进趋势可以定义为群体智能的社会计算,简单表述为,用NPU大算力和去中心化计算来虚拟化驾驶环境,通过数字化智能体即自动驾驶车辆AV的多模感知交互决策,以及车车协同,车路协同,车云协同,通过跨模数据融合、高清地图重建、云端远程智驾等可信计算来构建元宇宙中ADS的社会计算能力。
ADS算法的典型系统分层架构一般包括传感层,感知层,定位层,决策层(预测+规划)和控制层。每个层面会采用传统算法模型或者是与深度学习DNN模型相结合,从而在ADS全程驾驶中提供人类可以认可的高可靠和高安全性,以及在这个基础上提供最佳能耗比、最佳用车体验、和用户社交娱乐等基本功能。
01 基于DNN模型的感知算法
ADS部署的传感器在极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的影响程度是不一样的。所以传感器组合应用可以来解决单传感器的感知能力不足问题,常用的多模传感器包括Camera (Front-View or Multiview or Surround-View; Mono or Stereo;LD or HD),毫米波Radar (3D or 4D)和激光雷达LIDAR(LD or HD)。ADS的一个主要挑战是多模融合感知,即如何在感知层能够有效融合这些多模态传感器的输出,配合高清HD地图或其它方式定位信息,对应用场景中的交通标识,动态目标属性(位置、速度、方向、高度、行为),红绿灯状态,车道线,可驾驶区域,进行特征提取共享和多任务的2D/3D目标检测、语义分割、在线地图构建、Occupancy特征和语义提取(Volume/Flow/Surface)等等。基于DNN模型的感知算法,在实际工程部署中的一个挑战,还需要解决图 1所示的三个方向关键难题:数据挑战、模型挑战、和复杂场景挑战。
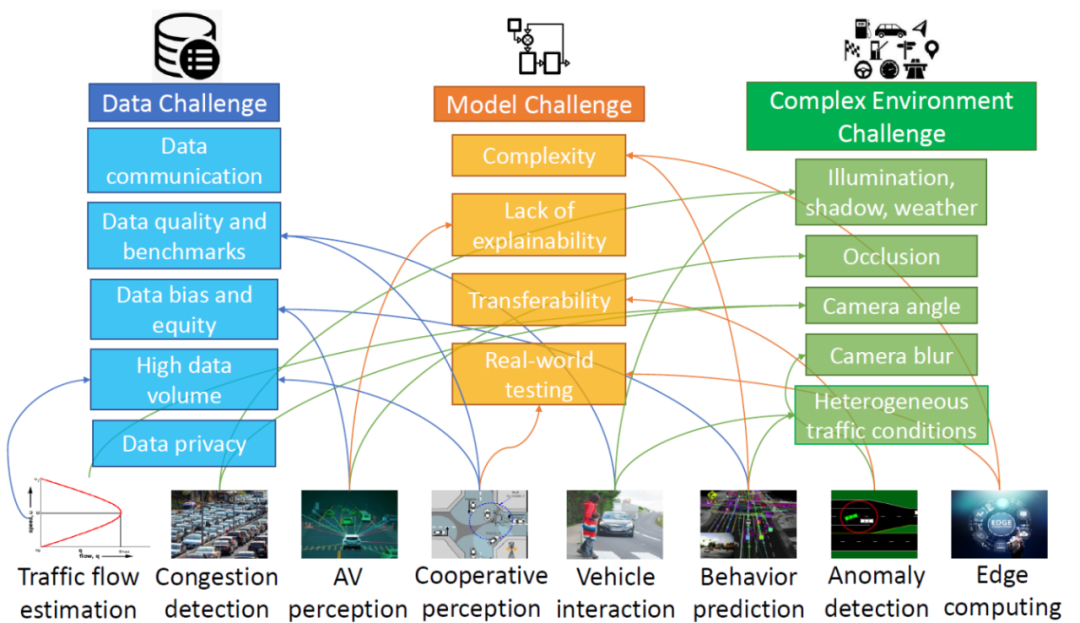
图 1 DL算法在智能交通ITS和自动驾驶领域ADS的部署挑战(Azfar 2022) 目前大多数AI视觉感知任务,包括目标检测跟踪分类识别,场景语义分割和目标结构化,其算法流程都可以简单总结为特征抽取,特征增强和特征融合,然后在特征空间进行(采样)重建,最后进行多任务的各类检测识别与语义理解。以目标检测任务为例,一个主要的发展趋势,是从CNN (Compute-bound)向 Transformer (memory-bound)演进。CNN目标检测方法包括常用的Two-Stage Candidate-based常规检测方法(Faster-RCNN)和One-Stage Regression-based 快速检测方法(YOLO, SSD, RetinaNet, CentreNet)。
Transformer目标检测方法包括DETR, Vision Transformer, Swin Transformer, DTR3D, BEVFormer, BEVFusion等等。两者之间的主要差别是目标感知场的尺寸,前者是局部视野,侧重目标纹理,后者是全局视野,从全局特征中进行学习,侧重目标形状。可以看出针对各类模型包括混合模型和通过NAS架构搜索生成的模型,学术界和工业界在持续推陈出新,高速迭代,依旧呈现出多元多样化态势,但如何有效进行模型选型,以及模型小型化和工程化加速,一直是ADS产业算法能否成功落地的核心难题。
02 基于DNN模型的决策算法
基于DNN模型的决策算法,是一种在数据充分的条件下,通过少量的人力投入就可以提供非常有力的设计表达。尤其是针对社交关系建模与推理来解决ADS中预测与规划问题,通过监督和自监督学习的方式,单独或者联合建模的方式,以及模仿学习IL和强化学习RL的学习流程。交互建模的输入来自车辆状态,包括定位信息,速度,加速度,角速度,车辆朝向等。端到端的DL-based方法通常直接通过卷积处理原始传感数据(RGB图像和点云),计算简洁但会损失弱的或者隐含的交互推理的内容表达。如图 2所示,深度学习模型中的不同构建模块,是可以对多智能体的交互推理进行有效建模和表达的,其中
(a)全连接FC层:又称多层感知器MLP,其中所有输入通过连接可以与输出交互并对输出做出贡献。 (b)卷积CONV层:卷积层采用局部感知场,所以每层的连接会比较稀疏,通常假定合适用来捕获空间关系,最初的底层卷积层一般提取类似边缘纹理类的信息,越接近顶层也偏语义特征。 (c)递归Recurrent层 :通常用来处理时间维度的数据序列,多用来捕获时间关系。 (d)图Graph层:典型的图包括节点、边(用来描述节点间关系)、和上下文全局属性,通常用来捕获图结构表征中显性关系推理,与FC层和RNN层一个不同之处是输入的先后次序不会影响结构,图结构还可以处理不同数目的个体,比较适合多个体的ADS环境。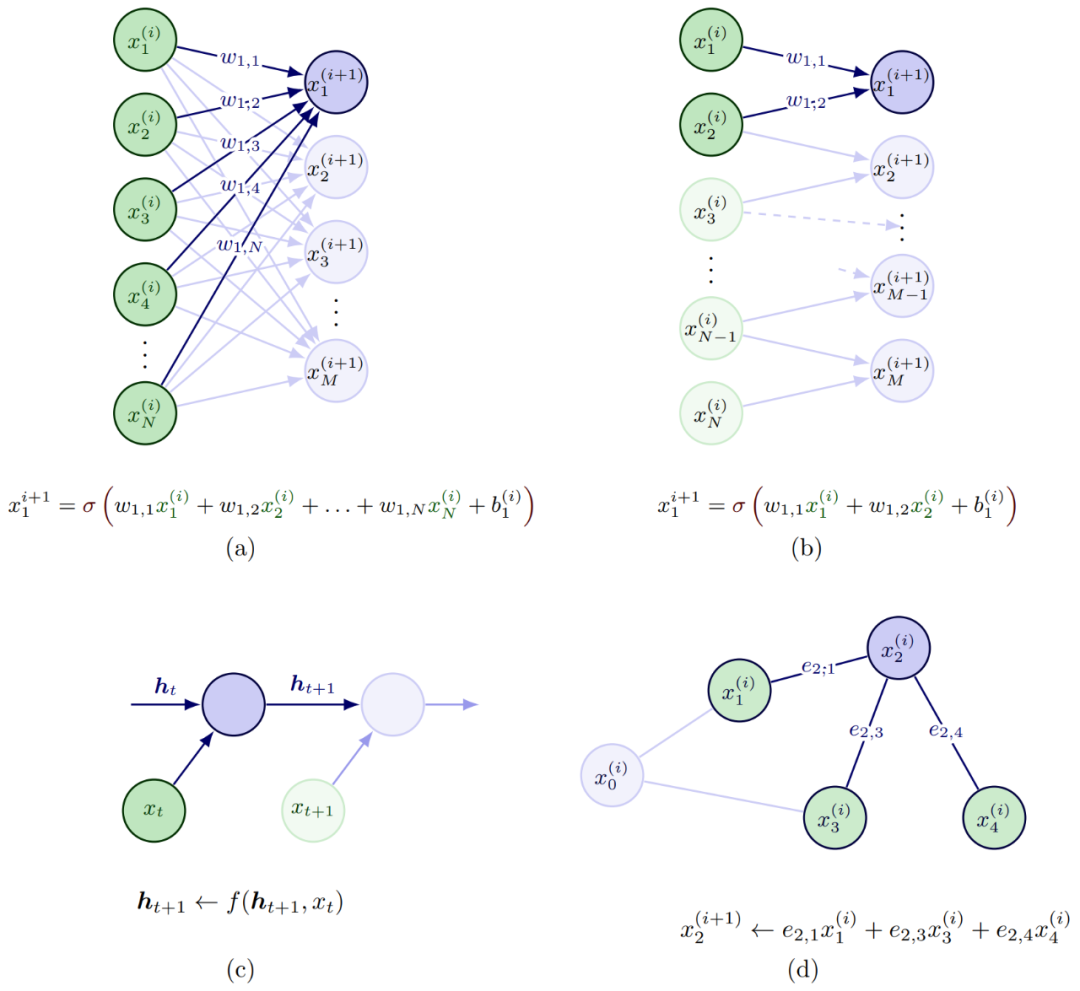
图 2 DNN模块对多智能体交互的建模案例(Wang 2022) 对于ADS中社交特征表征,常用的有空间时间状态特征矢量,空间占用方格和图区域动态插入等方式。空时状态特征矢量比较难以定义,尤其是个体数量变化和有效时间步长的不同,另外一个限制是依赖于个体插入的次序。所以一个常用的设计思路是采用占用方格地图Occupancy Grid Map (OGM)来解决上述的两个问题。OGM是以本体ego agent为中心来构建空间方格图,可以处理ROI区域不同数目的智能体。OGM通常采用原始状态(定位,速度,加速度)或者采用FC层来进行状态编码,如果FC层隐层包括个体的历史轨迹信息,可以同时捕获空间时间信息。
OGM的分辨率对计算性能影响比较大。 相对而言,图网络GNN可以通过动态插入区域DIA抽取来更好地构建空间时间交互图关系,图的类型可以基于个体(车辆,行人,机动车等),也可以基于区域area,后者主要聚焦对车辆意图(车道保持,换道并道,左拐右拐)的表征,这里DIA指的是可驾驶场景中空闲空隔。如图 3所示,DIA的优势在于对环境中静态元素(道路拓扑,类似stop道路标志牌等)和动态元素(行驶车辆)非常灵活,可以认为是动态环境的统一表征或者也可以叫做环境的虚拟化。所有时间地平线的DIAs可以用来构建空间时间语义图。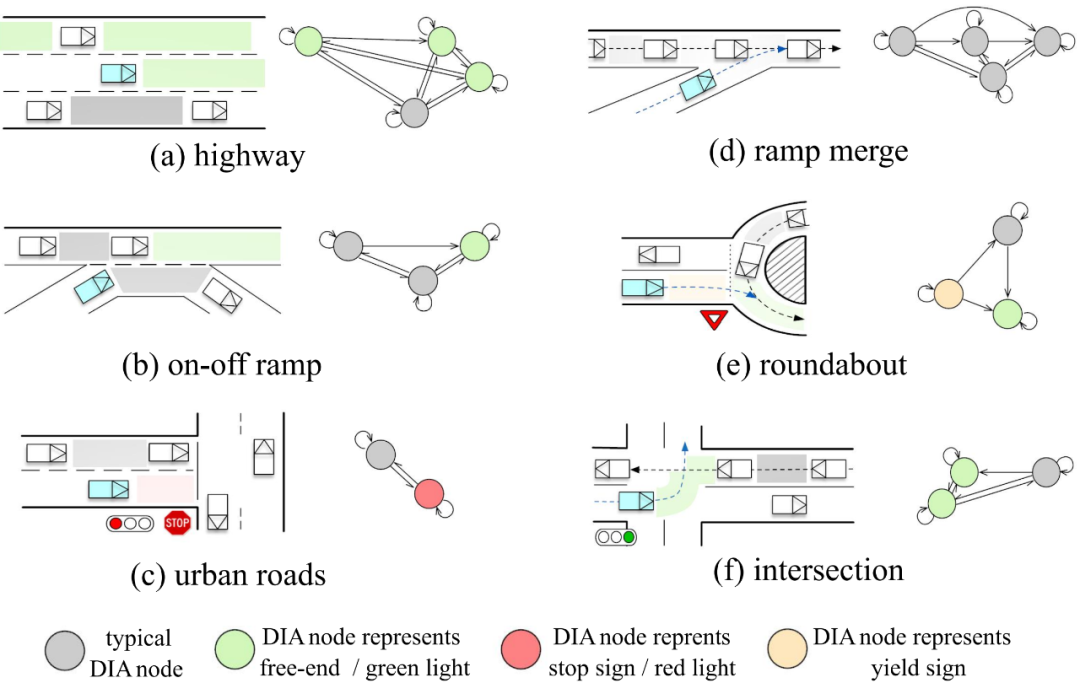
图 3 动态插入区域抽取和场景语义图 构建案例(Wang 2022) 如图 2所示,群体智能的社会计算,其中的社交关系,可以采用不同的深度学习层来进行交互建模和编码:
FC层交互编码:采用将不同个体的特征进行拉平,拼接成一个向量。多用来对单体single agent进行运动和意图建模,很少用于multiple agent。
CONV层交互编码:将空间时间特征(状态特征张量)或占用方格地图做为CNN输入来进行交互编码。
Recurrent层交互编码:多采用LSTM来进行时间维度推理,编码产生的embedding张量可以捕获时间空间的交互信息。
Graph层交互编码:对多智能体之间的关系采用节点之间的无向或者有向边来表征,可以用消息传递机制来进行交互学习,每个节点通过聚集邻近节点的特征来更新自身的属性特征。
在实际设计中,多将Recurrent层和Graph层相结合,可以很好地处理时间信息。而注意力attention机制编码可以更好地量化一个特征如何影响其它特征。人类司机会在交互场景中有选择地选取其它个体来进行关注,包括其过去现在的信息和未来的预判。所以注意力机制编码可以基于时间域(短期的和长期的)和空间域(本地的和偏远的),在上述方法中通过加权方案分别进行应用。对个体的注意力建模,可以采用基于距离的方法,这意味着其它个体越近,关注度也越高。 综上所述,DL-based方法由于模块化的设计和海量数据贡献,性能占优,但如何能够提供模型的安全能力和大规模部署,需要解决几个挑战:在保证性能基础上改善可解释性;在不同的驾驶个体,场景和态势下继续增强模型的推广能力;模型选型和工程实现如何有效加速落地问题。
03 CNN与Transformer选型对比探讨
Transformer或Transformer + CNN + RNN混合模型选型呈现出了高效的算法性能,对应在工程实现上也开始主导整个ADS行业市场。Transformer采用Attention机制的主干网络,而CNN在 特征提取和变换上由Convolution来主导,深度理解两种模型的主要收益到底来自什么样的算法模块或者算子,对ADS主流算法的未来演进,可能会有一种积极的推动作用。
一种看法(Dai 2022)认为,这主要的差别来自特征变换模块(Attention vs Convolution)对空间特征聚类的处理方式,即所谓的Spatial Token Mixer(STM)问题。当前常用构建DNN网络模型包括Attention, Convolution, Hybrid等模块的多种变形,以分类算法为例,先后有HaloNet(Halo Attention), PVT(Spatial Reduction Attention, 2021), Swin Transformer(Shifted Window Attention, 2021), ConvNeXt(7x7 Depth-Wise Convolution, 2022), InternImage (Deformable Convolution v3, 2022)等SOTA模型出世。
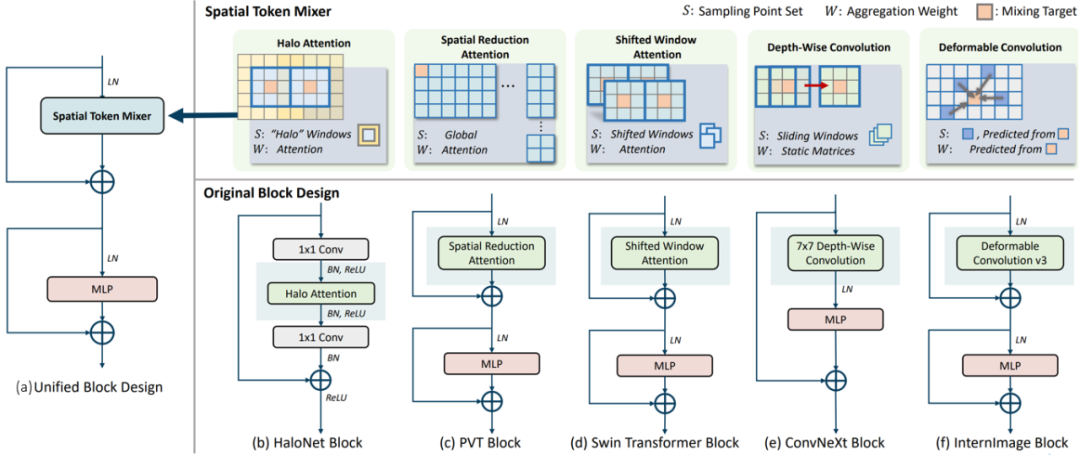
图 4 特征变换模块的实现案例(Dai 2022) 如图 4所示,CNN和Transformer模型中最常用的四种STM算子类型包括:Local Attention, Global Attention, Depth-Wise Convolution, Dynamic Convolution。采用固定感知场的Static Convolution只在小容量模型(~5MB参数)中表现不错,而Local-Attention STM模型结合跨窗间信息转移策略可以显著提升性能。
STM的设计也反映了假定空间即归纳偏置中采用的先验知识和约束条件对模型学习的影响,包括局部特性Locality、平移不变性,旋转不变性和尺寸不变性等模型特性,这可以从有效感知场ERF与下游多任务学习的关联关系来体现,有趣的是,当上调模型参数时,扩大ERF反而会导致模型饱和,同样我们工程实现中也观察到,对特征提取backbone而言用CNN来替代Transformer Encoder进行推理加速,也有类似模型饱和问题和上下游任务匹配不齐的问题。
至于对于各类目标不变性的性能对比,性能高的模型,对不同场景变化的鲁棒性会好一些,Static Convolution采用权值共享和局部感知场有利于提升平移不变性,而灵活的采样策略可以动态地进行特征聚类,在动态卷积(例如DCNv3)中表现出更好的旋转和尺寸缩放不变性。 Convolution-based STM模型多采用如下架构:Residual Learning, Dense Connection, Grouping, Spatial Attention,Channel Attention。其中Spatial Attention采用Deformable Convolution和Non-Local算子采用灵活可变的点采样来构建长范围的依赖语义依赖关系。
Vision Transformer的出世也给这类设计带来了新的架构设计和探索思路。 对于Attention-based STM模型,比较而言,Transformer采用的全局感知场和动态的空间聚类,也带来了海量的计算复杂度,尤其是ADS 应用中需要场景覆盖的计算区域越来越大时,这对ADS NPU的加速设计引入了一个全新课题。
从算法角度而言,图 4所示的几个算法,也采用了类似CNN的Local Attention机制,例如采用非重叠的局部计算窗和金字塔结构,以及跨窗间信息迁移的机制,例如Haloing,Shifted Windows等等,当前还有一种新的设计思路采用CNN和Transformer算子块的交织实现方式,也可以称作为联合或者混合架构,可以很好的融合CNN和Transformer的各自优势,适当降低总体计算复杂度。而NAS网络架构检索可以采用更加灵活的算子组合的策略,当然这显然增加了硬件计算架构和数据流优化的设计难度。
审核编辑:刘清
-
AI大模型与深度学习的关系2024-10-23 4246
-
深度神经网络(DNN)架构解析与优化策略2024-07-09 5608
-
深度学习中的模型权重2024-07-04 6393
-
深度学习模型训练过程详解2024-07-01 4645
-
目前主流的深度学习算法模型和应用案例2024-01-03 3785
-
什么是深度学习算法?深度学习算法的应用2023-08-17 3451
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2164
-
TDA4对深度学习的重要性2022-11-03 1515
-
移植深度学习算法模型到海思AI芯片2022-01-26 1640
-
深度学习模型是如何创建的?2021-10-27 2395
-
基于DNN与规则学习的机器翻译算法综述2021-06-29 1007
-
浅析深度神经网络(DNN)反向传播算法(BP)2021-03-22 4625
-
浅谈深度学习之TensorFlow2020-07-28 3260
-
【我是电子发烧友】如何加速DNN运算?2017-06-14 5239
全部0条评论

快来发表一下你的评论吧 !
