

3D UX-Net:超强的医学图像分割新网络
描述

Title: 3D UX-Net: a Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
Author: Ho Hin Lee et al. (范德堡大学)
Paper: https://arxiv.org/abs/2209.15076
Github: https://github.com/MASILab/3DUX-Net
引言
众所周知,大多数医学图像如 MRI 和 CT 是属于 volumetric data 类型。因此,为了更加充分的利用体素信息,近几年已经提出了不少 3D CNNs 的模型,如 SwinUNETR、UNETR以及笔者前段时间分享过的UNETR++等。
整体来说,这些模型性能是越来越高,在几个主流的 3D 数据基准测试中也实现了大大小小的 SOTA,特别是 3D 医学图像分割这块。当然,时代在进步,作为一名高科技前沿从业者本身也是需要不断汲取新的知识营养才能不被轻易的淘汰。今天小编就带大家解读下 ICLR 2023 新鲜出炉的 3D 医学图像分割之星——3D UX-Net。
3D UXNet 是一种轻量级3D卷积神经网络,其使用 ConvNet 模块调整分层 Transformer 以实现稳健的体素分割,在三个具有挑战性的脑体积和腹部成像公共数据集与当前的 SOTA 模型如 SwinUNETR 对比,同时在以下三大主流数据集性能均达到了最优:
-
MICCAI Challenge 2021 FLARE -
MICCAI Challenge 2021 FeTA -
MICCAI Challenge 2022 AMOS
具体的,相比于 SwinUNETR,3D UX-Net 将 Dice 从 0.929 提高到 0.938 (FLARE2021),Dice 从 0.867 提高到 0.874 (Feta2021)。此外,为了进一步评估 3D UX-Net 的迁移学习能力,作者在 AMOS2022 数据集上训练得到的模型在另一个数据集上取得了 2.27% Dice 的提升(0.880 → 0.900)。
动机
先来看看最近提出的一众基于 Transformer 架构的 ViT 模型有什么优劣势。以 SwinUNETR 为例,其将 ConvNet 的一些先验引入到了 Swin Transformer 分层架构中,进一步增强了在 3D 医学数据集中调整体素分割的实际可行性。此类 "Conv+Transforemr" 的组合拳的有效性在很大程度上归功于以下两个因素:
- 非局部自注意力所带来的大感受野
- 大量的模型参数
为此,本文作者想到了应用深度卷积以更少的模型参数来模拟这些方法让网络学会如何捕获更大感受野的行为。这一点笔者在前文《关于语义分割的亿点思考》中也提过,文中对整个任务进行了深度剖析,有兴趣的读者可以自行翻阅公众号历史文章:
语义分割任务的核心思想是如何高效建模上下文信息,它是提升语义分割性能最为重要的因素之一,而有效感受野则大致决定了网络能够利用到多少上下文信息。
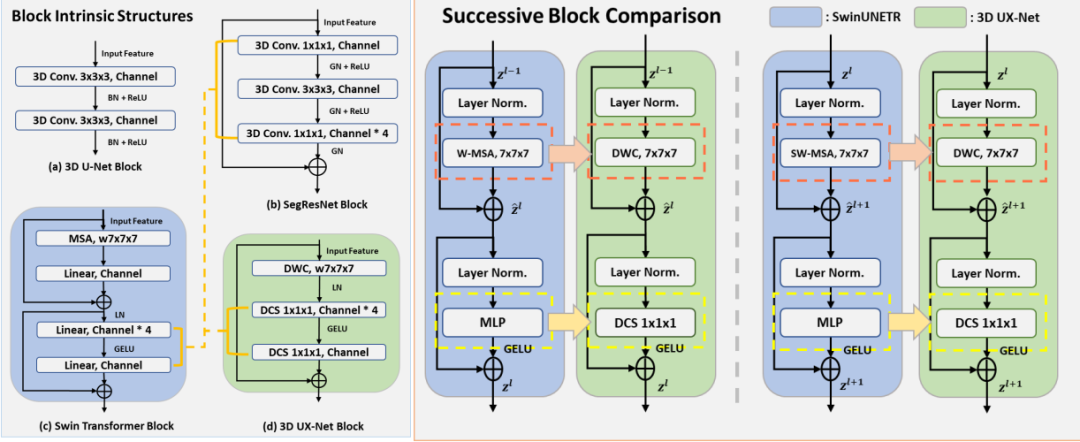
回到正文,本文的设计思路主要是受 ConvNeXt 启发,还没了解过的同学也可自行移动到公众号翻阅历史文章,笔者之前对该系列也讲解过了,此处不再详述。3D UX-Net 核心理念是设计出一种简单、高效和轻量化的 网络,其适用于 hierarchical transformers 的能力同时保留使用 ConvNet 模块的优势,如归纳偏置。具体地,其编码器模块设计的基本思想可分为: 1) block-wise(微观层面) 及 2) layer-wise(宏观层面)【可以类比下 ConvNeXt】。
block-wise
首先,我们先从下列三个不同的视角进行讨论。
Patch-wise Features Projection
对比 ConvNets 和 ViTs 之间的相似性,两个网络都使用一个共同的基础模块将特征表示缩小到特定的尺寸。以往的方法大都没有将图像块展平为具有线性层的顺序输入,因此作者采用具备大卷积核的投影层来提取 patch-wise 特征作为编码器的输入。
Volumetric Depth-wise Convolution with LKs
Swin transformer 的内在特性之一是用于计算非局部 MSA 的滑动窗口策略。总的来说,有两种分层方法来计算 MSA:基于窗口的 MSA (W-MSA) 和 移动窗口 MSA (SW-MSA)。这两种方式都生成了跨层的全局感受野,并进一步细化了非重叠窗口之间的特征对应关系。
受深度卷积思想的启发,作者发现自注意力中的加权和方法与每通道卷积基础之间的相似之处,其认为使用 LK 大小的深度卷积可以在提取类似于 MSA 块的特征时提供大的感受野。因此,本文建议采用 LK 大小(例如,从 7 × 7 × 7 开始)通过深度卷积压缩 Swin transformer 的窗口移动特性。如此一来便可以保证每个卷积核通道与相应的输入通道进行卷积运算,使得输出特征与输入具备相同的通道维度。
Inverted Bottleneck with Depthwise Convolutional Scaling
Swin transformer 的另一个固有结构是,它们被设计为 MLP 块的隐藏层维度比输入维度宽四倍,如下图所示。有趣的是,这种设计与 ResNet 块中的扩张率相关。因此,我们利用 ResNet 块中的类似设计并向上移动深度卷积来计算特征。此外,通过引入了具有 1 × 1 × 1 卷积核大小的深度卷积缩放(DCS),以独立地线性缩放每个通道特征。通过独立扩展和压缩每个通道来丰富特征表示,可以最小化跨通道上下文产生的冗余信息,同时在每个阶段增强了与下采样块的跨通道特征对应。最后,通过使用 DCS,可以进一步将模型复杂度降低 5%,并展示了与使用 MLP 模型的架构相当的结果。
layer-wise
介绍完微观层面的设计思想,再让我们从宏观层面出发,以另外三个崭新的视角去理解作者的动机。
Applying Residual Connections
从上图左上角可以看到,标准的 3D U-Net 模型内嵌的模块为 2 个 3 x 3 x 3 卷积的堆叠,其展示了使用小卷积核提取具有增加通道的局部表示的朴素方法;而其右手边的 SegResNet 则应用了类似 3D 版本的瓶颈层,先降维再升维最后再接残差表示;紧接着左下角的便是 Swin Transformer,其基于窗口注意力+MLP层的组合;最后右下角便是本文所提出的模块,其在最后一个缩放层之后应用输入和提取特征之间的残差连接。此外,在残差求和前后并没有应用到任何的归一化层和激活层。
Adapting Layer Normalization
我们知道,在卷积神经网络中,BN 是一种常用策略,它对卷积表示进行归一化以增强收敛性并减少过拟合。然而,之前的工作已经证明 BN 会对模型的泛化能力产生不利影响。因此作者这里跟 ConvNeXt 一致,将 BN 替换为 LN。
Using GELU as the Activation Layer
ReLU 是个好东西,几乎是现代 CNNs 模型的首选激活函数。作者在这里提倡使用 GELU,这是一种基于高斯误差的线性变换单元,相对 ReLU 更加平滑,也是其中一种变体,解决 ReLU 因负梯度被硬截断而导致的神经元失活问题。
方法
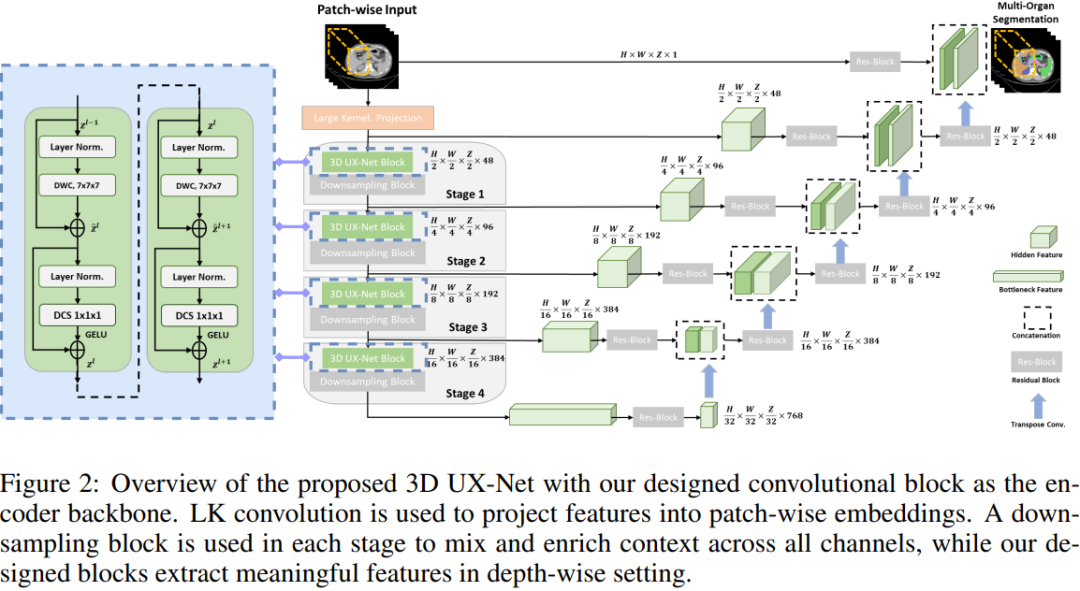
可以看出,整体的设计思路非常简洁,框架也是一目了然,就一个标准的 3D U-Net 架构,由编码器-解码器组成,同时结合长跳跃连接操作帮助网络更好的恢复空间细节的定位。也没啥好分析的,下面就简单拆开来看看,带大家快速的过一遍就行。
DEPTH-WISE CONVOLUTION ENCODER
首先,输入部分应用一个大卷积核将原始图像映射到一个低维空间分辨率的潜在空间特征表示,一来降低显存参数量计算量等,二来可以增大网络感受野,顺便再处理成编码器输入所需的格式,总之好处多多,不过都是基操。
处理完之后就输入到编码器中进行主要的特征提取,该编码器共4个stage,也是标准的16倍下采样。每个stage由多个不同的 3D UX-Net Block 构成,具体长啥样自己看下左图一点就通。主要的特点就是主打轻量化和大感受野。
DECODER
编码器中每个阶段的多尺度输出通过长跳跃连接链接到基于 ConvNet 的解码器,并形成一个类似U形的网络以用于下游的分割任务。这一块就跟标准的 3D U-Net 几乎没啥两样了。
实验
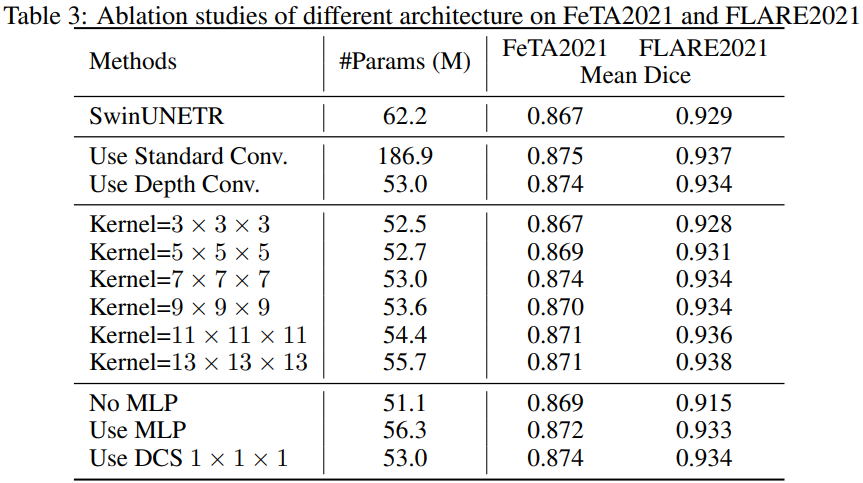
消融实验
可视化效果
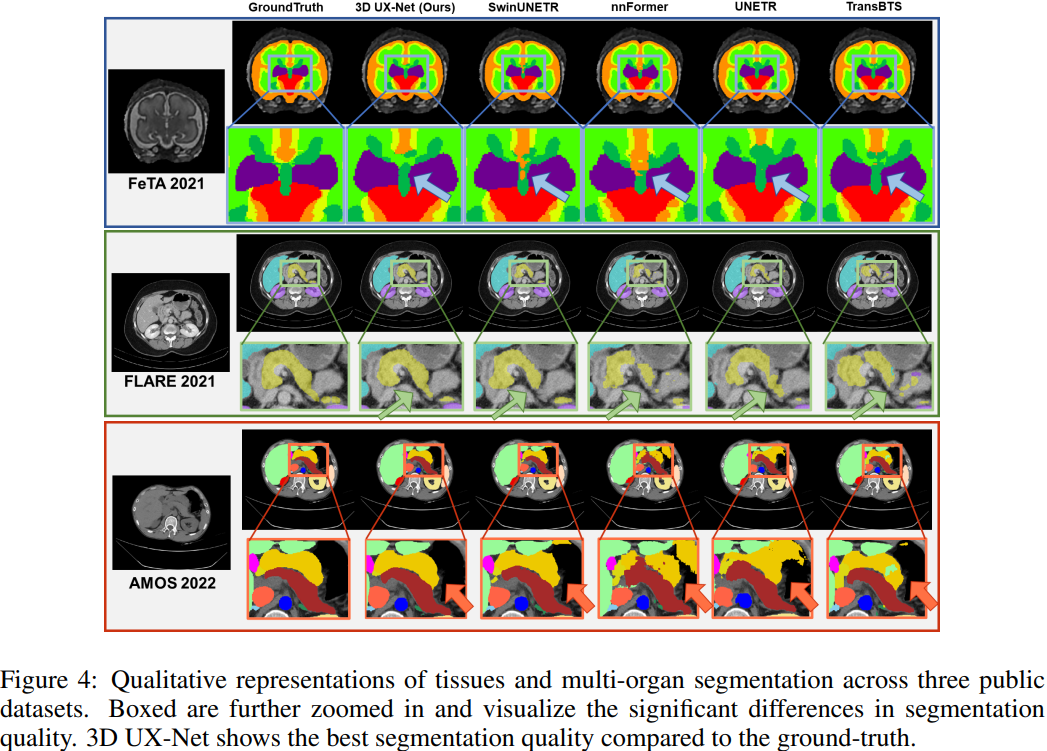
可以看到,与 GT 相比,3D UX-Net器官和组织的形态得到了很好的保存。
与 SOTA 方法的对比
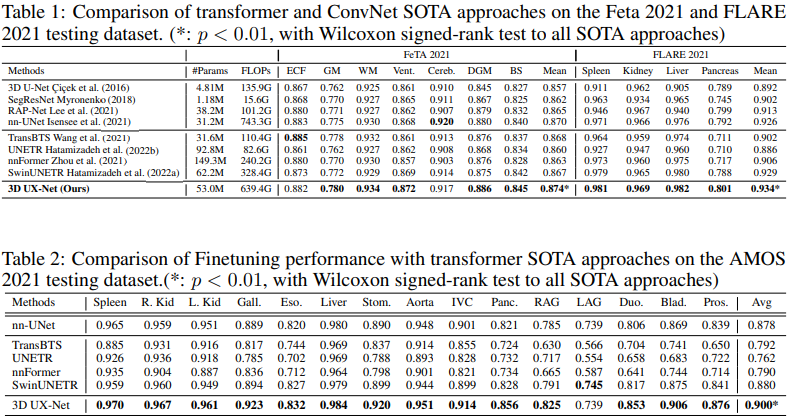
从上述表格可以看出,3D UX-Net 在所有分割任务中均展示出最佳性能,并且 Dice 分数有了显着提高(FeTA2021:0.870 到 0.874,FLARE2021:0.929 到 0.934)。
总结
本文为大家介绍了 3D UX-Net,这是第一个将分层 Transformer 的特征与用于医学图像分割的纯 ConvNet 模块相适应的3D网络架构。具体地,本文重新设计了具有深度卷积的编码器块,以更低的代价实现与 Transformer 想媲美的能力。最后,通过在三个具有挑战性的公共数据集上进行的广泛实验表明所提方法的高效性。
审核编辑 :李倩
-
为什么需要分割?U-Net能提供什么?U-Net和自编码器的区别2023-11-25 8137
-
基于深度学习的3D点云实例分割方法2023-11-13 3959
-
深度学习在医学图像分割与病变识别中的应用实战2023-09-04 2583
-
ImgX-DiffSeg:基于DDPMs的3D医学图像分割2023-05-15 2267
-
基于Diffusion Probabilistic Model的医学图像分割2023-05-04 5460
-
基于MLP的快速医学图像分割网络UNeXt相关资料分享2022-09-23 4408
-
数坤科技3D卷积神经网络模型用于肝脏MR图像的精准分割2022-04-02 5438
-
van-自然和医学图像的深度语义分割:网络结构2021-12-28 2551
-
基于 U-Net 的医学影像分割算法2021-08-25 6038
-
3D打印技术在医学中的应用2021-07-22 3382
-
基于改进CNN的医学图像分割方法2021-06-03 1300
-
基于深度特征聚合网络的医学图像分割方法2021-05-13 1043
-
谷歌发明的由2D图像生成3D图像技术解析2020-12-24 5811
-
3D图像引擎,3D图像引擎原理2010-03-26 1698
全部0条评论

快来发表一下你的评论吧 !
