

介绍一下Polars这个模块的使用方式
描述
Polars 是一个速度极快的 DataFrames 库。
它拥有以下特性:
1.多线程
2.强大的表达式API
3.查询优化
下面给大家简单介绍一下这个模块的使用方式。
1.准备
请选择以下任一种方式输入命令安装依赖:
1. Windows 环境 打开 Cmd (开始-运行-CMD)。
2. MacOS 环境 打开 Terminal (command+空格输入Terminal)。
3. 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install polars
2.Polars 使用介绍
在初始化变量的时候,Polars用起来的方式和Pandas没有太大区别,下面我们定义一个初始变量,后面所有示例都使用这个变量:
import polars as pl
df = pl.DataFrame(
{
"A": [1, 2, 3, 4, 5],
"fruits": ["banana", "banana", "apple", "apple", "banana"],
"B": [5, 4, 3, 2, 1],
"cars": ["beetle", "audi", "beetle", "beetle", "beetle"],
}
)
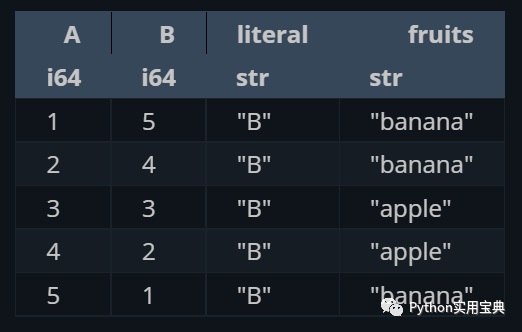
选择需要展示的数据:
(df.select([
pl.col("A"),
"B", # the col part is inferred
pl.lit("B"), # we must tell polars we mean the literal "B"
pl.col("fruits"),
]))
效果如下:
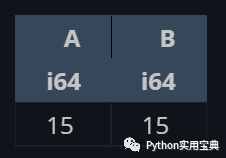
他还能使用正则表达式筛选值并进行求和等操作:
# 正则表达式
(df.select([
pl.col("^A|B$").sum()
]))
# 或者多选
(df.select([
pl.col(["A", "B"]).sum()
]))
Polars支持下面这样复杂且高效的查询及展示:
>>> df.sort("fruits").select(
... [
... "fruits",
... "cars",
... pl.lit("fruits").alias("literal_string_fruits"),
... pl.col("B").filter(pl.col("cars") == "beetle").sum(),
... pl.col("A").filter(pl.col("B") > 2).sum().over("cars").alias("sum_A_by_cars"),
... pl.col("A").sum().over("fruits").alias("sum_A_by_fruits"),
... pl.col("A").reverse().over("fruits").alias("rev_A_by_fruits"),
... pl.col("A").sort_by("B").over("fruits").alias("sort_A_by_B_by_fruits"),
... ]
... )
shape: (5, 8)
┌──────────┬──────────┬──────────────┬─────┬─────────────┬─────────────┬─────────────┬─────────────┐
│ fruits ┆ cars ┆ literal_stri ┆ B ┆ sum_A_by_ca ┆ sum_A_by_fr ┆ rev_A_by_fr ┆ sort_A_by_B │
│ --- ┆ --- ┆ ng_fruits ┆ --- ┆ rs ┆ uits ┆ uits ┆ _by_fruits │
│ str ┆ str ┆ --- ┆ i64 ┆ --- ┆ --- ┆ --- ┆ --- │
│ ┆ ┆ str ┆ ┆ i64 ┆ i64 ┆ i64 ┆ i64 │
╞══════════╪══════════╪══════════════╪═════╪═════════════╪═════════════╪═════════════╪═════════════╡
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 4 ┆ 4 │
│ "apple" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 7 ┆ 3 ┆ 3 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 5 ┆ 5 │
│ "banana" ┆ "audi" ┆ "fruits" ┆ 11 ┆ 2 ┆ 8 ┆ 2 ┆ 2 │
│ "banana" ┆ "beetle" ┆ "fruits" ┆ 11 ┆ 4 ┆ 8 ┆ 1 ┆ 1 │
└──────────┴──────────┴──────────────┴─────┴─────────────┴─────────────┴─────────────┴─────────────┘
3.Polars 高级使用
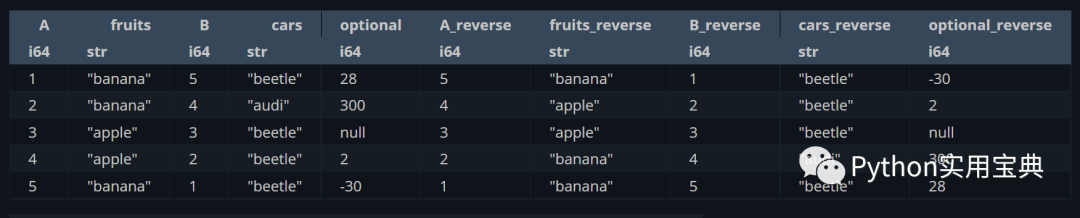
倒序操作,将值倒序后重新放回变量中,起名为xxx_reverse:
(df.select([
pl.all(),
pl.all().reverse().suffix("_reverse")
]))
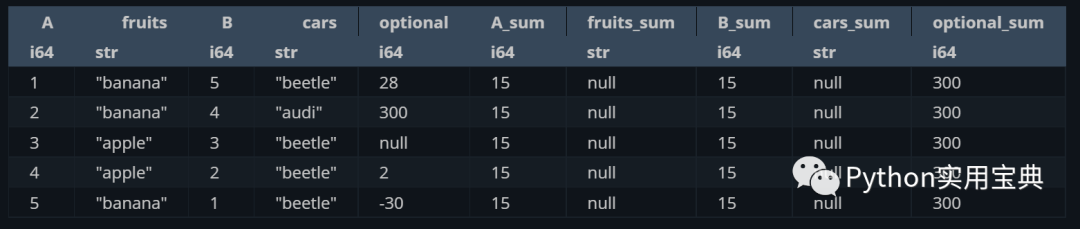
对所有列求和,并放回变量中,起名为 xxx_sum:
(df.select([
pl.all(),
pl.all().sum().suffix("_sum")
]))
正则也能用于筛选:
predicate = pl.col("fruits").str.contains("^b.*")
(df.select([
predicate
]))
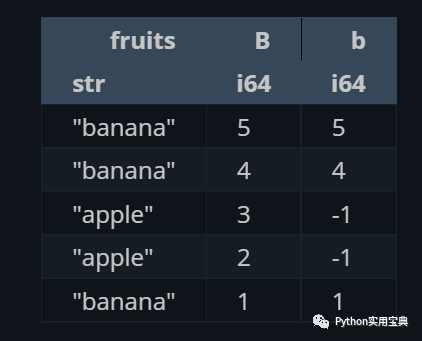
在设定一个新列的时候,甚至可以根据条件来给不同的行设定值:
(df.select([
"fruits",
"B",
pl.when(pl.col("fruits") == "banana").then(pl.col("B")).otherwise(-1).alias("b")
]))
fold 函数很强大,它能在列上执行操作,获得最快的速度,也就是矢量化执行:
df = pl.DataFrame({
"a": [1, 2, 3],
"b": [10, 20, 30],
}
)
out = df.select(
pl.fold(acc=pl.lit(0), f=lambda acc, x: acc + x, exprs=pl.col("*")).alias("sum"),
)
print(out)
# shape: (3, 1)
# ┌─────┐
# │ sum │
# │ --- │
# │ i64 │
# ╞═════╡
# │ 11 │
# ├╌╌╌╌╌┤
# │ 22 │
# ├╌╌╌╌╌┤
# │ 33 │
# └─────┘
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
详细介绍一下PSS+Pnoise仿真2023-11-03 24819
-
请问一下这个模块用的什么芯片?2018-10-30 2092
-
介绍一下波形占空比实现的方式2021-08-04 1664
-
介绍一下三菱变频器控制方式负载特征点2021-09-03 2632
-
介绍一下ESP8266 WiFi 模块2022-01-18 1800
-
介绍一下SPI协议2022-02-17 1064
-
简要介绍一下Python-UNO的使用方法2018-01-04 10071
-
介绍一下这款4g模块的功能2019-05-07 24104
-
电磁炉加热一下就停一下什么原因2021-06-04 42175
-
介绍一下机电暂态开源工具箱MatTrans的注意事项2022-01-10 524
-
Polars是一个使用Apache Arrow列格式作为内存模型2022-07-07 1670
-
简单介绍一下什么是微波通讯?2023-03-05 4880
-
Polars模块的使用方式2023-10-17 1363
-
浪涌抗扰度怎么测?我们用这个A/D转换器试了一下2023-11-27 1860
-
将NVIDIA加速计算引入Polars2024-11-20 1882
全部0条评论

快来发表一下你的评论吧 !
