

汽车SoC嵌入式存储器的优化诊断策略
电子说
描述
本文介绍了一种在SoC嵌入式存储器测试期间压缩诊断信息方法。 更具体地说,该方法被应用于诊断嵌入式FLASH存储器。 这一策略允许在没有任何损失的情况下重建故障位图,而压缩方法获得一个近似值。 所提出的方法只使用了基于坐标的位映射方法所要求的一小部分内存,并且与压缩方法相当。 以适度的测试时间开销为代价,所提出的策略允许大幅增加可被完全诊断的设备数量,而没有任何位图重建损失。 在一个真实的嵌入式FLASH生产场景中,大多数故障设备在从片上到测试主机的一次传输后就被诊断出来。
I.引言
集成在现代汽车微控制器中的嵌入式存储器占据了很大比例的芯片面积。 由于这个原因,它们对产量有很大的影响,因此在它们的测试和维修程序上投入了大量的精力。 然后必须研究他们的故障和 "故障历史",以诊断生产阶段的问题。
测试的目的是确保每个商业化的设备都能按照预期的规格完美地工作。 在设计测试步骤时,要做很多考虑,要考虑到浴缸曲线上显示的早期失效和其他影响电路物理参数的老化效应。
软件测试是业界经常使用的可行解决方案,但众所周知它的速度特别慢。 作为测试设计工作的一部分,已经开发了专门的硬件,就像在[3][4][5][6][7]中描述的那样来改进这方面问题。 一个标准的方法是实现一个硬件BIST(内置自检)。 这种直接在芯片上执行的硬件可以进行许多内部组件的测试,而采用外部测试工具或软件方法是不切实际或不可能达到的。
对于嵌入式闪存(eFLASH)测试,一个存储器需要多次擦除、编程和验证操作来评估是否存在故障。 在特性化和提升阶段,另一个重要的概念是收集测试数据,将其添加到纯测试中,这使得制造商能够将诊断信息不断反馈给技术专家和设计师。 这样一个精确的流程可以提高产量和盈利能力。
一个广泛采用的报告故障的解决方案是位故障图表示,其中位行为被报告,即创建一个存储器的矩阵表示,显示每一个位,如果正常工作则标记为0,如果检测到故障则为1。 这种技术是内存密集型和时间密集型的,因为它需要在自动测试设备(ATE)和被测设备(DUT)之间进行复杂和耗时的通信。 由于这些原因,位图很少在生产环境中使用,除非在批量生产期间出于统计过程控制的原因,来压缩沿着测试收集的信息。 一个使位图成本最小化的解决方案包括片上位图压缩。
在本文中提出了一种基于数据编码和着色概念的创新方法来收集和压缩eFlash存储器的诊断信息。 使用这种片上方法实现了高度的数据压缩,对速度的影响很小。
在我们的设备(Aurix TC39xB)中,eFLASH测试是由一个可编程的硬件BIST和一个CPU组成的复合片上模式进行的。 当BIST应用测试刺激时,CPU协调整个过程,包括接收和表述来自BIST的故障信息以产生编码的故障位图。 通过谨慎使用这种设置,可以节省很多内存,而且测试时间的开销也是可以接受的。
本文组织如下:在第二部分,简要解释了用于eFlash测试的BIST架构,并分析了eFlash测试流程,以了解诊断信息的主要来源。 在第三节中,详细解释了特别是从失败的坐标到创建基本信息结构的过程。 第四节展示了在生产阶段收集的1800多个真实案例位图的实验结果。 在第五部分做了一些总结。
II.背景
A.嵌入式内存结构
在典型的嵌入式存储器中,组成矩阵的位按行(称为字行)和列(称为位行)组织。 每个字行被进一步划分为具有一定数量位的页。 页代表内存的最小粒度,由一定数量的位组成。 整个页面将被访问,并最终被修改,以读取或编程一个单一的位。 由一定数量的字行和位行组成的单一存储器单元被称为物理扇区。 最后,更高层次的结构由多个物理扇区组成。 同样重要的是提到一种常见的内存组织,称为置乱,由多路复用和镜像位组成,详见[3]:
● 复用:具有相同索引的位在字行中物理上是相邻的
● 镜像:字行以其中间点为对称轴进行镜像。
图1显示了一个以4位字组织的16位存储器的可视化表示。 在物理上,它实现了4的多路复用因子和每2个扰乱位的镜像。
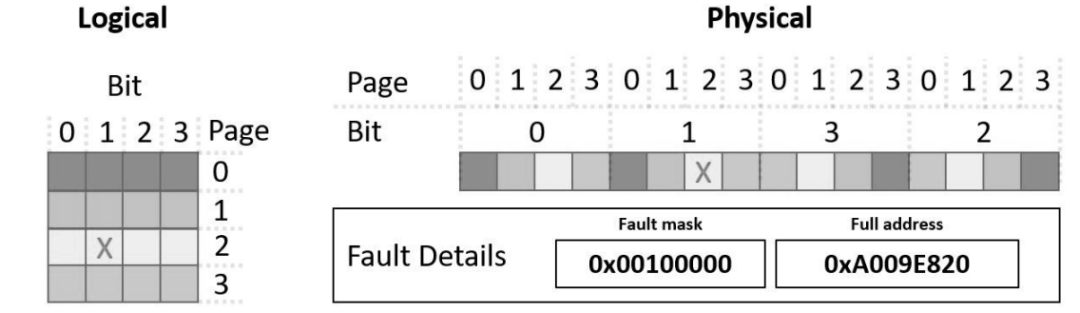
图1.从BIST接收的存储器组织和故障细节
B.用于诊断的架构
Landzberg等人所描述的嵌入式存储器诊断的是最直接的结构。 这项工作提出了一种基于ATE的方法,该方法可以直接访问被测存储器,一旦出现故障坐标或存储在芯片上的坐标集合,就立即检索。 这种方法对收集到的数据不做任何处理,失败的系列可以从整组坐标中重构出来。
不同的是,Schanstra等人、Chen等人和Bernardi等人通过利用整合内存测试能力和支持片上位图收集的额外硬件提出了一些变化。 Schanstra等人的方法使用了一个经过修改的BIST架构,并将其扩展到执行形状识别。 所描述的BIST识别和压缩如失败的位行或字行等形状。 在这种压缩过程中,一些故障可能会丢失,所以这种技术并不能产生准确的位图表示。 Chen等人提出了一种压缩方法,以减少重建故障群集所需的位数; 这种位数的减少是以重建群集的低精确度为代价的。 Bernardi等人使用集成的BIST与他们设备的CPU相结合,以压缩他们测试中发现的故障坐标。 BIST报告了每个故障位的坐标。 然后,CPU对这些地址进行压缩,通过有效搜索Karnaugh图的立方体来利用不关心值。 这种方法限制了ATE和DUT之间的通信数量。
III.拟议的方法
所提出的方法是基于编码的概念来创建片上紧凑的故障位图。 通过利用复合测试架构,位图信息被存储在编码或 "彩色 "片段中,我们称之为 "切片",并随着测试的执行而更新。
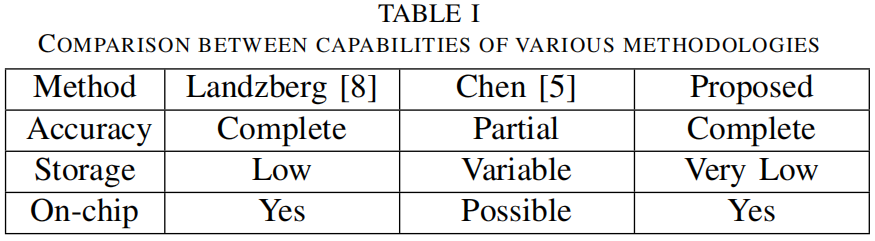
提出的压缩方法保证了高精确度,与[8]类似。 相反,由于压缩而返回一个近似的信息,如表I所示。 关于内存需求,所提出的方法需要的内存资源比[8]所要求的少,而在使用最小压缩比时,比[5]中的方法略多。 拟议的方法在片上运行,能够在测试结束时下载完整的信息,就像[8]所做的那样,也可能是[5]中的方法,它最初是通过额外的硬件和测试器能力来实现的。
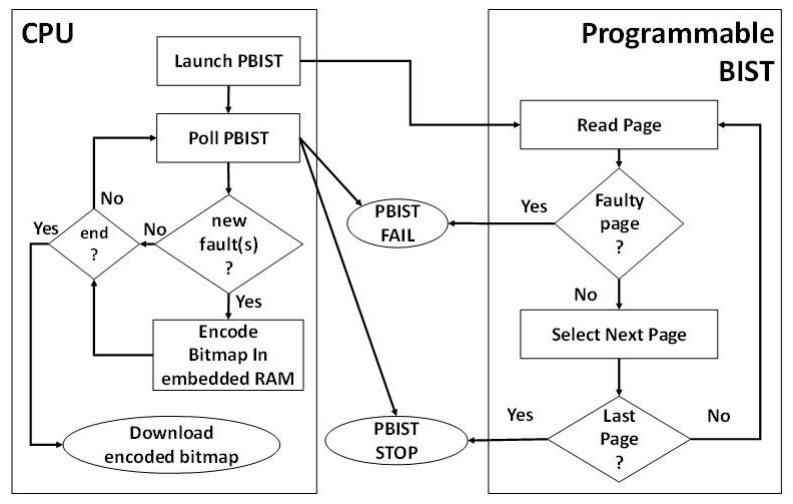
图2. CPU和可编程BIST组织
我们提出的位映射模式是由一个合适的硬软件设计支持的,其中一个可编程的BIST可以直接从CPU中访问,就像在[9]和[10]中一样。 图2展示了用于测试的闪存设计是如何工作的。 CPU激活可编程BIST运行的选定过程,然后等待故障事件。 当遇到故障时,BIST停止并显示一个标志。 一旦CPU通过轮询动作注意到这个缺陷,它就可以访问数据,恢复BIST操作,然后进行一些计算。 这些片上计算可能涉及到分配一些冗余元素的修复算法和像本文所述的位映射算法。 在图3中,显示了一个黄金无故障测试的执行情况。 在这里,在初始阶段之后,BIST在称为 "tgold "的参考时间内独立测试整个嵌入式闪存。
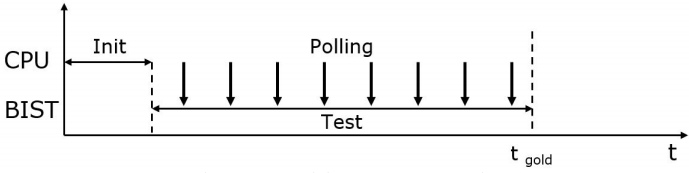
图3.黄金测试执行
图4显示了一个不同的情况。 在这里,BIST发现了一个故障并停止,等待CPU读取它并恢复其操作。 在这一点上,CPU和BIST可以以交错的方式独立工作。 因此,当BIST忙于测试存储器的其他部分时,CPU可以分析发现的故障,并运行位映射算法或本文提出的着色算法。
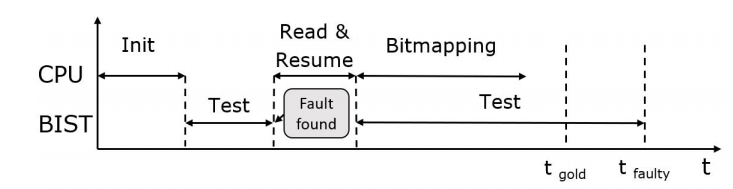
图4.故障位和交织CPU和BIST操作的测试
总的测试时间增加,现在是 "tfaulty",它小于整个系统的单一时间成分的总和(例如,tfaulty小于tgold、tread 和tencoding的总和)。 当计算需要对故障的出现作出反应时,这样的折叠方法对节省测试时间非常有利。 在我们的案例中,我们利用这种可能性对存储在芯片上的位图信息进行增量编码。 每当PBIST返回一个故障时,编码算法被执行,当前的位图信息被更新。
A.拟议的编码策略
所提出的方法的目标是产生失败位图的片上和动态编码表示。 该方法的主要目标是使预先分配的片上存储器所能容纳的信息数量最大化。 片上存储器构成了一个非常强的约束条件。 假设可用的内存资源在测试结束前就已经用完了。 在这种情况下,位图将导致不完整,或者测试人员应该通过下载当前部分进行干预,恢复测试,并继续反复进行,直到测试结束。 尽管多次下载的解决方案在理论上看起来是可行的,但很少有测试器架构支持它,而且它严重影响了测试时间。
因此,节省大量完整位图的最可行的解决方案是通过对信息进行编码来压缩它们。 虽然代价编码计算所带来的测试时间开销。
在我们的方法中,我们将芯片上的位图信息编码为 "彩色段",也称为 "切片",这是我们压实算法的基本结构。 在仔细检查了成千上万的故障集群后,我们选择了片段而不是其他类型的形状(即矩形)。 故障大多在字行和位行上排列,这使得片段成为编码它们的最有效和最直接的方式。 一个片断代表一个或多个属于同一位行或字行的故障,其格式包括:
● 指示该段是水平还是垂直
● 该段中第一个和最后一个故障的物理坐标部分
● 一种颜色,考虑到它所覆盖的故障的分布情况,来描述该段的特征。
对于拟议方法,提出了四种颜色,如图5所描述的,并在下文中说明:
A) 黑色:一个黑色段包括一个单一的故障
B) 蓝色: 代表两个相距甚远的故障
C) 红色: 代表在奇数或偶数位置的两个或多个故障(一个或多个故障定期由工作位交错)。 这种颜色在应用棋盘图案时是有好处的,因为内存准确地在其编码图案中测试。
D) 橙色: 两个或更多物理上相邻的故障
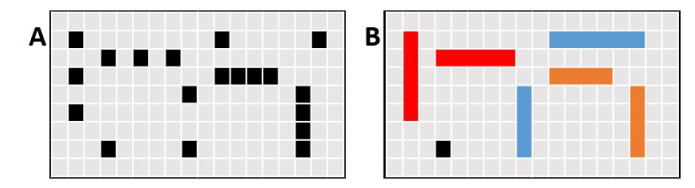
图5.断层形状到颜色表示
在图5中,左边的部分显示了实际的位图,而右边则报告了彩色的片段或切片。
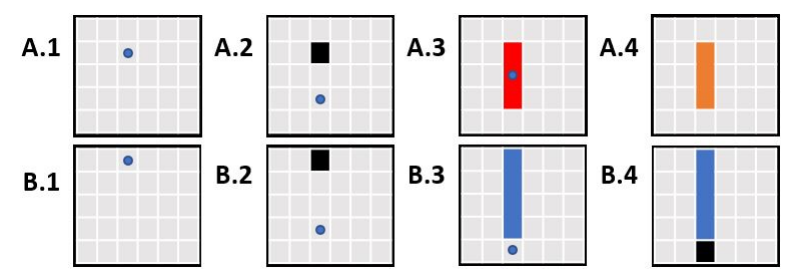
图6.基于以蓝点表示的新输入故障的位置更新切片
拟议的方法的目的是创建一个切片集,以满足我们的DUT的故障集群。 这样一个集合是由CPU在fly上建立的,它通过更新现有切片的内容或初始化一个新的切片来应对新的故障。
在图6中,显示了当新故障到来时如何更新切片的例子:
● 首先,收到一个故障,即A.1,然后在A.2中创建一个黑色切片。 在A.2中,收到一个新的故障,导致A.3中的黑色切片更新为红色切片。 类似地,A.3中红色切片中间收到的故障导致其更新为A.4中所示的橙色切片
● 首先,收到一个故障,即B.1,然后在B.2中创建一个黑切片。 在B.2中,收到一个新的故障,该故障导致B.3中的黑色切片更新为蓝色切片。 在B.3中,在蓝色切片的正下方发现了一个故障。 由于蓝色片断不能包含额外的故障,因此创建了一个黑色切片来编码B4中的最后一个故障。
B.编码信息的片上内存
需要考虑的一个重要问题是片上存储器是如何组建的。 这不仅与潜在的存储能力有关,而且还与内存信息的访问时间有关。 事实上,该算法应该能够快速检查已经包含的信息,以演变出当前的编码位图。 换句话说,该算法必须在当前的切片集合中搜索是否有一个现有切片要更新或创建一个新的黑色切片。
拟议方法旨在最大限度地减少需要存储的信息和算法处理一个新故障所需的时间。 存储器组织就像缓存中使用的组织,它实现了一个集合关联的方法。
鉴于所选集的数量为N,可用的内存被分成N个相等的部分。 当一个新的故障被记录下来时,它的地址和故障掩码被CPU检索到,CPU对它们进行处理以提取三个部分:
● 从字行地址中可以看出
– 切片所属的集合索引,如:计算地址%N
– 以Address/N计算的集合归一化后的故障坐标
● 从故障掩码中提取了一个标签,然后用来进行搜索,表明该位在故障掩码中的位置。
图7用一个例子说明了如何解析PBIST的输出。 图8完成了内存组建的概述,在一个集数为N=32的情况下,故障掩码包括256bits。 根据集合关联组建的要求,内存被分为N个大小相同的块。 一旦从故障信息中计算出集合,就会访问正确的内存部分,并使用标签在集合中寻找具有相同标签值的切片。 如果这样的切片已经存在于相应的集合中,那么它将按照前面的描述进行操作。 反之,如果当前的故障不能与以前存储的任何故障相联系,就会存储一个新的切片。
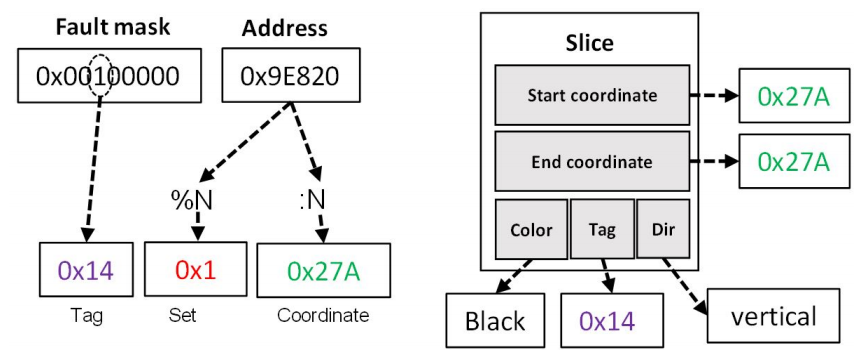
图7.当N=32时CPU分析的故障信息
图示方法在搜索时间和所需位方面都非常有效。 以集为单位的划分可以将搜索时间减少一个系数,该系数取决于集的数量N。 设定值不存储在切片中,但可以通过反向公式从片上存储器中的切片地址推断出来。
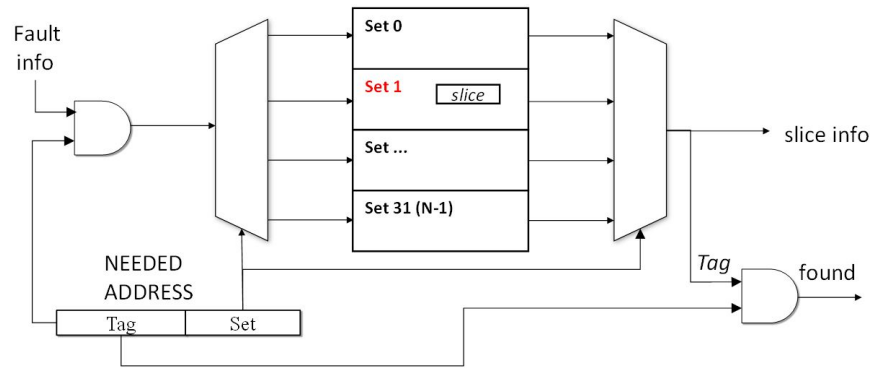
图8.用于片上切片存储的可用存储器的类似高速缓存的组织
C.选择水平或垂直编码方向
当然,故障掩码可能包含一个以上的故障位。 在这种情况下,该算法可以创建一个垂直(面向位线)或水平(面向字线)的切片。 尽管垂直着色比较容易,而且是通过在故障掩码中一次考虑一个位来进行的,但通过尽快识别水平形状来尽可能减少其使用量是至关重要的。 由于扰乱效应,导致故障分布在一个字行中的许多闪存页上,要断定一个段是水平方向的,因此变得很困难。
为了解决在选择垂直或水平方向的速度和准确性之间的权衡,当算法 "猜测 "到有一个水平形状存在时,就会触发水平着色。 这个猜测是基于当前页面收到的故障数量; 如果超过一个给定的阈值,水平着色就被激活。
图9中解释了方向的选择机制。 根据故障掩码中的故障数量,如果它们的数量小于阈值,就立即逐个地垂直着色,或者暂时保存在缓冲区中,以便以后着色。 事实上,如果将按照置乱模式在同一字行上排列的所有页面都一起处理,那么水平着色就更有效率。 一旦采取了水平方向,临时缓冲区就会用最终来自同一字行的其他页面的失败数据来更新。 缓冲区的内容在第一次遇到不再是被调查的字行的故障时被处理。 所创建的水平切片被储存在相应的内存组中。
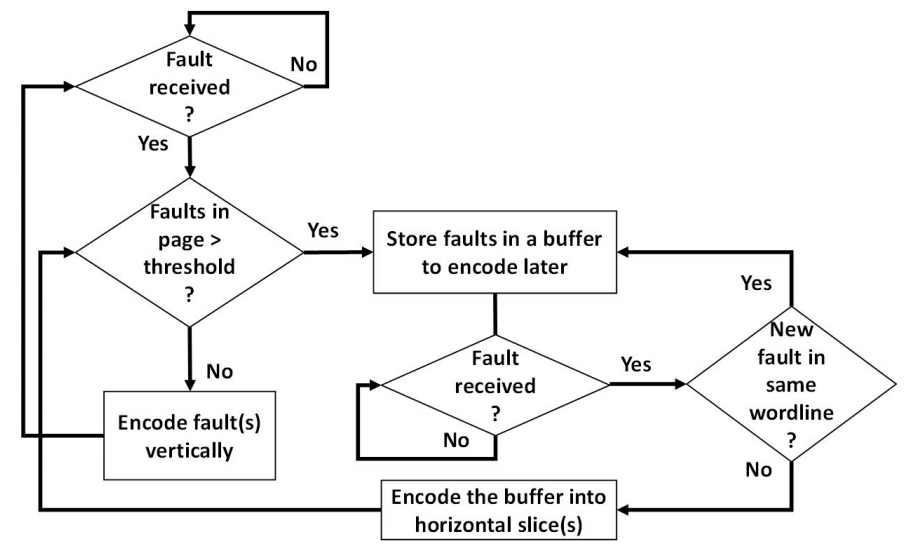
图9.垂直/水平编码决定的流程图
***IV.***实验结果
本节显示了拟议算法在各种研究案例中获得的结果。 参考设备是Aurix TC39xB,由Infineon Technologies制造。 对于这个设备,在测试操作系统组件大小的过程中,将RAM内存中存储位图信息的限制定为24KB。 可用的片上内存约束是评估该方法的关键因素。
在下面的段落中将比较所提出的压缩方法与采用逐位坐标的方法或像[5]中的压缩方法的利弊。 根据置乱参数将这样的空间分为32组。 配置参数,包括256位的故障掩码和32位的地址,导致所提出的方法有6字节大小的切片。 相反,逐位法直接将故障坐标保存为4字节的元素,[5]则采用字行和位行之间的共享位。
接下来的实验结果表明,图示方法在内存需求方面保证了稳定的平均存储,这意味着在提供相同数量的内存时,它可以比参考的逐位方法存储更多的信息。 换句话说,与逐位法相比,所提出的方法可以完全记录更多的故障设备。 该方法在增加位图生成时间方面付出了代价,考虑到占用优势,这看起来是可持续的。
关于与[5]的比较,在运行实验时的压缩率为4480倍。 这是可能的最低分辨率,它需要一个固定的20KB的片上存储器,因此,在存储器限制下,这种方法在片上是可行的。
在这一点上,首先报告了所提出的方法的优点和成本,并提到了来自生产数据的四个真实和典型的故障场景。 报告了所提出的方法和[8]之间的比较,后者在片上保存了故障单元坐标的完整列表。
然后,考虑了一个更广泛的失败设备集,大约2000个,这些设备被准确地挑选出来,构成了大量的生产样本。 这一部分揭示了逐位法的速度稍快,但受到可用的片上存储器空间的限制。 同时,这种限制在所提出的方法中得到了缓解。 还比较了[5]中压缩后重建的位图的平均精度,并计算了一个相关指数,以评定与无损方法相比在精度上的损失。
A.对一些典型阶段的精细分析
下面的图是经过裁剪的位图,显示了一些故障的嵌入式闪存的特定区域。 每张图都有(A)故障位图和(B)算法返回的相应表示。
图10显示了一个垂直方向的故障情况。 在这种特殊情况下,eFlash受到388个故障的影响,相对于黄金执行(具有良好内存的测试)的开销是21ms。 与需要14.35ms的逐位方法相比,拟议方法显示了46%的相对时间开销。 尽管有时间上的损失,但与需要1.51KB的逐位法相比,拟议的算法节省了95%的所需RAM空间,即约78B。
垂直的情况是那些与提议的算法更吻合的情况。 事实上,PBIST需要一些时间来达到后续的故障,因此,在PBIST运行时,CPU极大地利用了这段时间来执行该算法。
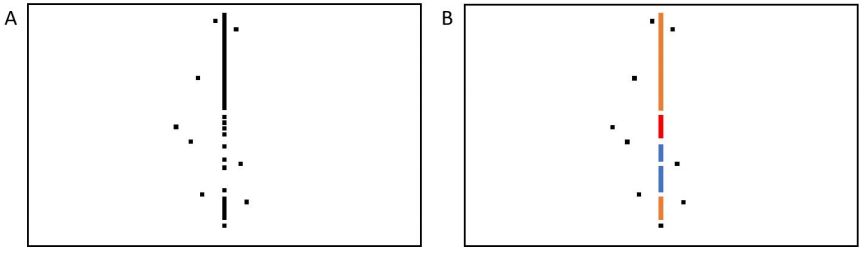
图10.部分故障位线定向场景的示例
在水平方向形状的情况下,比如图11中的形状,预计会有更大的时间开销,因为水平方向的着色来自于包含一个以上故障位的故障掩码,因此需要更多的时间来计算,而且PBIST在每次连续读取时都会遇到故障。
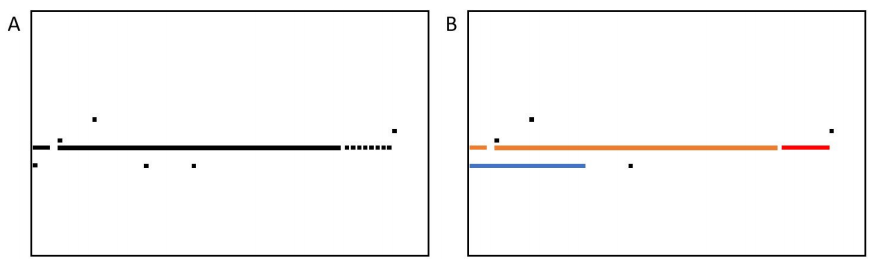
图11.部分失效字线的示例
在这样的情况下,总体上有18229个故障,与逐位法相比,测试时间增加了69%,而RAM内存节省了约98.68%。
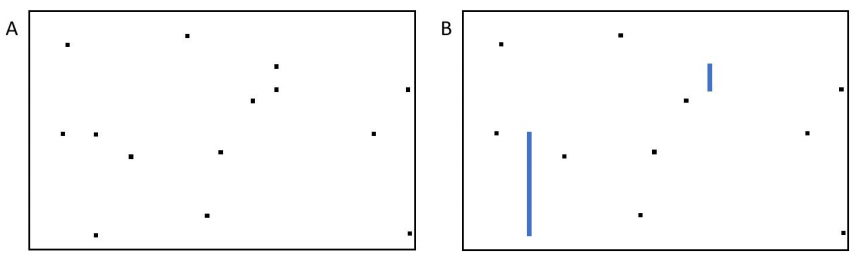
图12.稀疏故障场景的示例
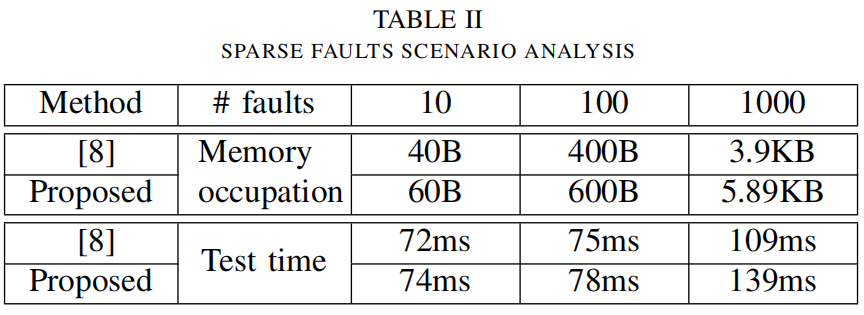
表二显示了在改变失败位数时逐位方法与提议方法的比较。 值得注意的是,拟议的方法比逐位的方法需要稍多的时间和内存,因为故障的稀疏性使其无法聚集。
稀疏的故障构架是另一个需要观察的重要场景。 由于压实的可能性有限,这种集群是最难处理的。 图12描述了一个相当密集的内存矩阵稀疏故障的案例。 其中一些距离较远但在同一位行或字行形状上对齐时,就会出现蓝色的切片,这是以前考虑的情况的综合。 尽管有内在的困难,但与逐位法相比,拟议的方法显示了有限的损失。 在图13中的案例中,包含了9949个故障,收集诊断信息的时间是680ms,而逐位法需要440ms。 相反,内存占用从逐位法的38.85KB急剧下降到拟议法的0.1KB。
B.在更大的设备基础上取得的成果
实验测量也可用于更广泛的基础的设备。 我们考虑了1864个来自前端晶圆测试操作的失败设备。 这样一个集合收集了许多不同的形状,并用于进一步评估拟议方法的优势和成本。
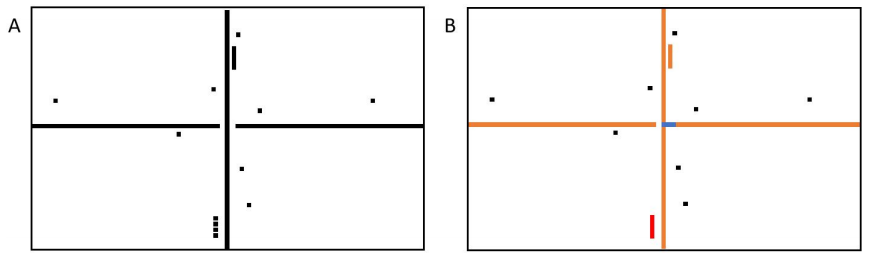
图13.交叉点处具有工作钻头的十字形故障星座图
我们将其与基于逐位坐标的方法和[5]中的压缩方法进行比较。
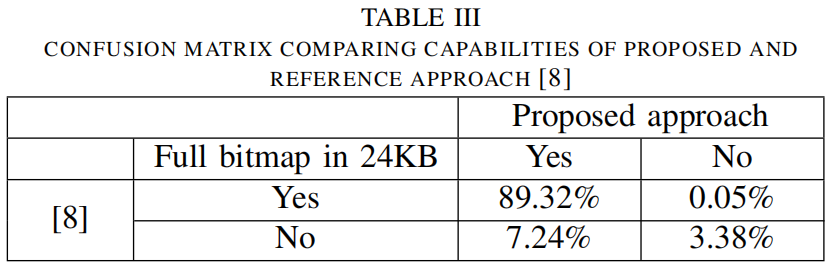
表三报告了这些方法在整个基数上的设备数量,这些设备可以在不超过片上24KB RAM限制的情况下进行位图绘制。 从这个表中可以看出,仅通过我们的方法和基于逐位坐标的方法,有多少设备在24KB内被完全记录下来。
当24KB的片上RAM被填满时,一些诊断信息就会丢失,除非测试和诊断过程被中断,当前的位图被转储到测试仪上,才能恢复内存测试程序。 假设诊断收集被暂停,新的故障不再被记录。 在这种情况下,以前编码的故障被保留下来,在测试流程的最后可以重建一个部分故障集群,如图14所示。 选定的人口平均约为2000人。
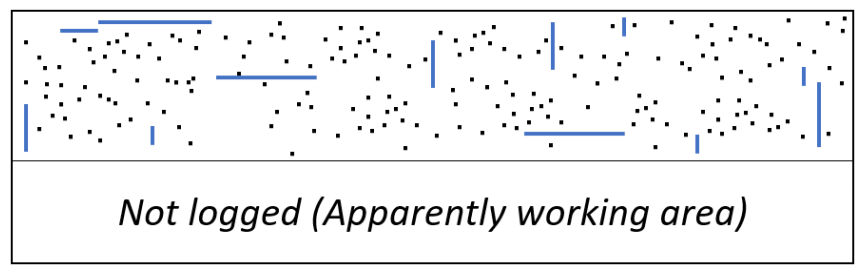
图14.从完整的24KB缓冲区部分重构的故障星座图
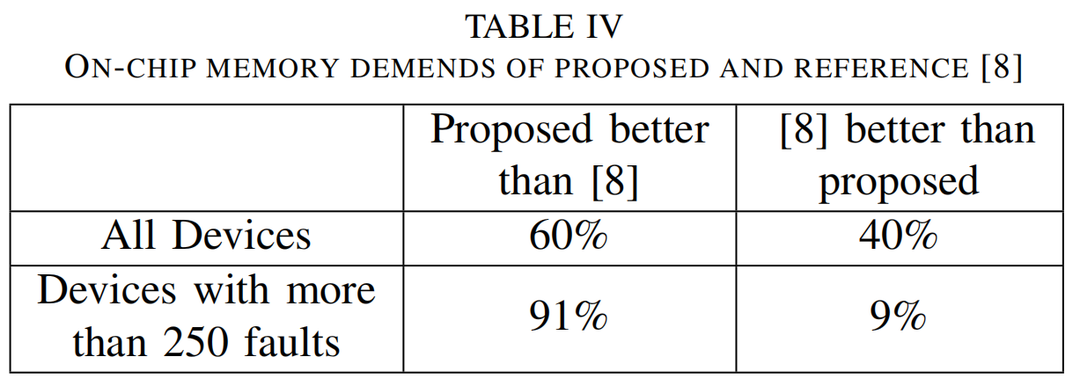
所选群体显示出平均约2000个故障,差异约为5000个故障。 通过观察群体样本的表现发现,测试和收集诊断信息的总体时间平均为192ms,差异为279ms。 对于逐位方法,这些值平均为152ms,差异为189ms。 表四涉及位图大小的占用; 它显示了被调查人群中位图创建大小较小的百分比,比较了拟议的方法和参考方法。 考虑到所有的设备,拟议的方法在大约60%的情况下需要更少的内存。 如果只考虑超过250个故障的失败场景,拟议的方法在大约91%的情况下显示出规模优势。 关于与[5]的比较,计算了皮尔逊相关指数来衡量与拟议方法的差异量。 将内存要求限制在20KB,[5]可以以相当低的精度存储任何故障集群; 平均而言,拟议方法计算出的相关指数为61%。 图15显示了重建的故障集群,a)用[5]压缩,b)用拟议的压实方法压实。 在这种特殊情况下,大约有2000个故障,相关指数为83%。
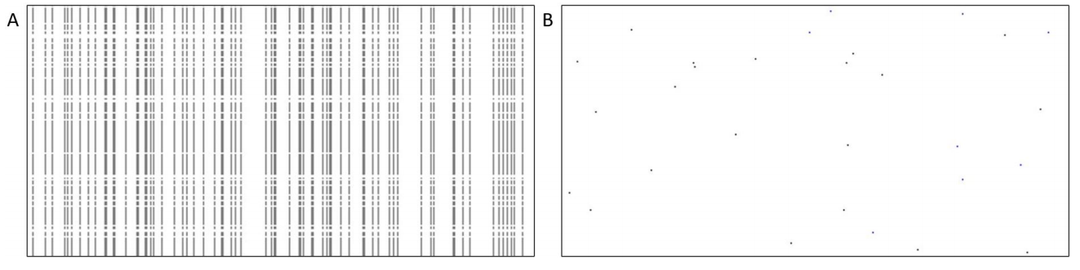
图15.通过[5](A)中所示的方法重建的位图与所提出的兼容位图(B)之间的比较
V.总结
在本文中提出了一种创新的算法,改善了eFlash测试中诊断信息的收集。 从真实数据中得到的结果表明,提出的方法在内存占用方面和速度方面都具备优势。 通过使用开发的算法,考虑到内存的大量保存,有可能将一个设备的完整故障历史永久地存储在一个较小的内存中,为故障设备的分析提供更多关于位图沿着测试步骤演变的细节。
-
嵌入式系统存储的软件优化策略2025-02-28 1767
-
一种在SoC嵌入式存储器测试期间压缩诊断信息方法介绍2022-09-07 3087
-
FPGA中嵌入式块存储器的设计2021-08-04 973
-
嵌入式存储器如何来设计2019-10-18 1567
-
嵌入式相变存储器在汽车微控制器中有什么优点?2019-08-13 1834
-
如何实现嵌入式ASIC和SoC的存储器设计?2019-08-02 1713
-
基于ASIC和SoC设计的嵌入式存储器优化解析2018-06-03 1548
-
关于SoC组成部分之一的嵌入式存储器,这些技术原理您都知道吗?2017-12-26 12989
-
嵌入式存储器的设计方法和策略2014-09-02 2246
-
平板电脑如何选用嵌入式存储器2012-04-20 2428
-
嵌入式存储器内建自修复技术2011-05-28 1223
-
采用嵌入式测试器实现SoC中存储子系统的良品率设计2010-07-26 604
-
嵌入式存储器发展现状2009-12-21 867
-
使用新SRAM工艺实现嵌入式ASIC和SoC的存储器设计2009-02-01 1844
全部0条评论

快来发表一下你的评论吧 !
