

BEV还有什么新的玩法吗
描述
特斯拉 NOA 导航辅助驾驶
大家想象中的自动驾驶,其实没有那么多定语,应该是从任意地点到任意地点都能自动驾驶。
但是自动驾驶技术的开发难度实在太大,各种限制因素也多,所以现在在乘用车自动驾驶领域,业界划分出了不同的 ODD(可运行区域),包括泊车域、行车域,行车域里面又有城市域、高速域,像蔚来还要把换电场景自动驾驶这个域加进去。
一段从车辆启动到车辆停好的旅程,被切割成了细分的很多段,业内企业们正分段攻破。
正是因为这些域的存在,衍生出了很多的自动驾驶功能(现在只能称为「辅助驾驶功能」),比如泊车域的自动泊车、遥控泊车、记忆泊车;而在行车域,又有基础辅助驾驶功能(ACC、LCC、ALC),还有更高级一些的导航辅助驾驶,可覆盖高速域以及城市域,再往后那就是真正的点到点自动驾驶。
不过目前由于自动驾感知技术还未达到极致成熟,从高速到城市,感知难度指数级提升,同时有其他限制因素,当下最主流的智驾功能——导航辅助驾驶系统开城的速度依然很慢。
01
导航辅助加速内卷
BEV感知技术成主流
从目前业内自动驾驶的产品形态看,导航辅助驾驶功能越来越火爆,这个由特斯拉带火的层次稍高一些的辅助驾驶功能,正在被国内的新老车企争相推动上车,国内的供应商们也都往这个方向上卷,因为这个方向既受到法规允许,也能吸引到真实消费者使用并为其买单。
未来 1-2 年,国内的导航辅助驾驶功能 NOA、NGP、NOP、NZP、ANP、NOH、NCA、NOM 等将迎来大爆发。当然,速度有快有慢,有的还在打磨高速导航辅助驾驶,有的已经把车开进了城市,开启了更难的挑战。
就在本月,此前主打 Robotaxi 开发和运营的小马智行正式宣布开辟乘用车智能驾驶业务产品线,并已成立独立事业部。
从其公布的智能驾驶量产方案中,要打造高速和城市导航辅助驾驶的规划非常明确。

小马智行公布的量产自动驾驶方案
这也足够说明导航辅助驾驶系统已经成为车企和供应商的兵家必争之地。
在导航辅助驾驶功能火爆和上量的背后,是自动驾驶核心技术在驱动。
感知技术、决策/规划/控制技术、高精地图技术等等,都在深刻影响着导航辅助驾驶产品的能力和体验。其中,感知技术以及定位技术是导航辅助驾驶功能实现的前提,没有这二者,后面的规划控制也就无从谈起。
感知能帮助系统「看」到道路上的参与者和道路要素,定位能告诉系统「我在哪里」,所以你可以看到现在各家的导航辅助驾驶一方面要在传感器种类和数量上卷;另一方面也很依赖于高精地图数据。
其中的高精地图覆盖范围以及新鲜度很大程度上限定了导航辅助驾驶的运行连续性以及可用范围。
可以预见的是,无论是高速导航辅助驾驶还是城市导航辅助驾驶,未来很长一段时间还是得依赖高精地图这一重要「传感器」。因为单从体验上来看,有高精地图的功能和没高精地图的功能确实有着非常大的差距。
但是依赖高精地图也不意味着行业放弃了对车端感知能力和技术的更高追求。其实是要寻找一种平衡:在有高精地图的地方增强车辆智驾系统体验;在没有高精地图的区域,系统能通过车上感知模块来指导车辆完成自动驾驶,比如像北京五环内这样的区域。
所以,行业也在推动自动驾驶感知技术的突破。感知技术接下来的主流会是什么?很多车企和供应商的答案是 —— BEV 感知。
02
BEV是什么?为什么被需要?
BEV 全称是 Bird's Eye View,也就是鸟瞰图,是一种用于描述感知到的现实世界的视角或坐标系(3D 空间),就像是上帝视角。另外,BEV 也是计算机视觉领域内的一种端到端的、由神经网络将图像信息从图像空间转换到 BEV 空间的技术。
大家知道在自动驾驶车上,有很多的传感器,如摄像头、毫米波雷达、激光雷达,自动驾驶系统里传统的图像空间感知方法是将汽车上的雷达、摄像头等不同传感器采集来的数据分别进行分析运算,然后再把各路分析结果融合到一个统一的空间坐标系,用于规划车辆的行驶轨迹。
但这个过程中每个独立传感器收集到的数据和人眼类似,受特定视角的局限,经过各自的分析运算后,在后处理融合阶段会导致误差叠加,很难精准地拼凑出道路实际全貌,给车辆的决策规划带来困难。
BEV 感知就好比是一个从高处统观全局的「上帝视角」,车身多个传感器采集的数据,会输入到一个统一模型进行整体推理,这样生成的「鸟瞰图」,有效地避免了误差叠加;BEV 方案还支持「时序融合」,也就是不仅收集一个时刻的数据,分析一个时刻的数据,而是支持把过去一个时间片段中的数据都融合进模型做环境感知建模,这样可以让系统感知到的结果更稳定,使得车辆对于道路情况的判断更加准确,让自动驾驶更安全。
BEV 感知技术其实是特斯拉带火的,作为业内纯视觉感知技术的鼻祖,很早就在这方面下功夫。
特斯拉车身上有多个摄像头和毫米波雷达,在做感知的时候,需要把不同传感器的感知数据收集并有效融合起来,输出感知结果。
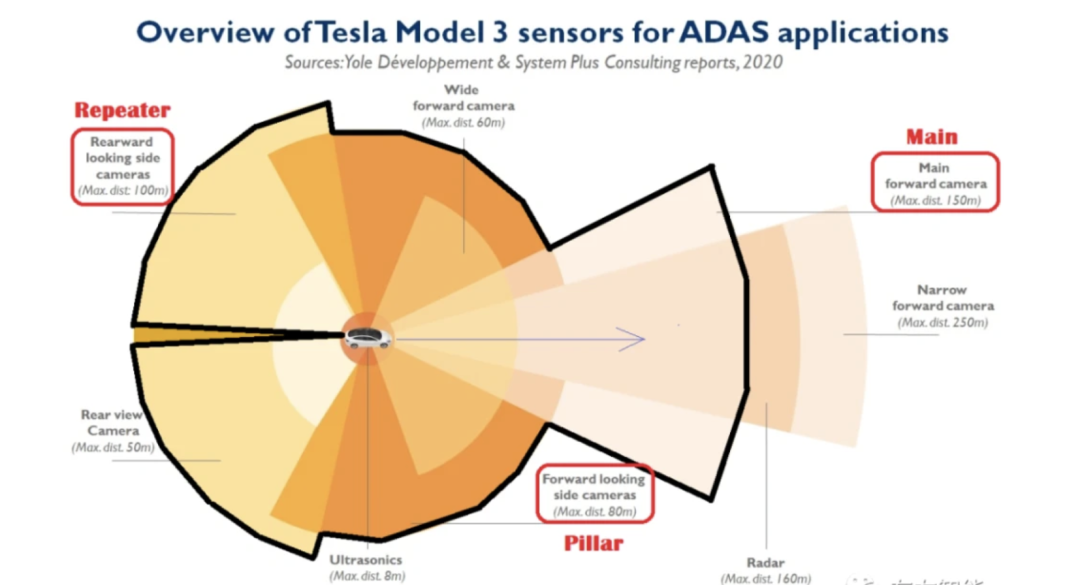
特斯拉车上不同位置的摄像头的参数并不一样(相机的内外参不同),包括焦距长度、视野宽度、深度感受野等等,这就导致同一个物体在不同的相机里是不一样的。
特斯拉在引入 BEV 之前采用的方式是:在每个相机上单独进行感知,然后再将不同相机感知到的结果进行融合。
但这种方式会存在几个问题:
比如融合困难,将不同相机的感知结果进行融合需要大量的超参,写起来非常复杂,并且由于深度估计的误差,最终的输出结果可能会相互冲突,导致融合结果不一致。
另外就是图像空间的输出对于后续任务来说很不友好,比如在一些预测任务上,如果不同相机单独感知,则很难预测被大面积遮挡的物体;单个摄像机也无法看到大物体的全貌,会导致难以正确预测。
为了解决这些问题,特斯拉采取的方法就是用神经网络将图像空间映射到 BEV 空间。
其做法是把多个视角的图像统一通过一个公共的特征提取器投影到一个统一的 BEV 空间里面。
在这个空间里面,通过深度学习去完成一个特征的融合,然后再通过一个 3D 的解码器,直接端到端输出最后的一个 3D 检测和道路结构信息。下游的像规划与控制模块直接可以在 BEV 的空间上去进行。
特斯拉 BEV 坐标转换
从 2D 图像空间到 3D BEV 空间如何转换?
这里不得不提到 Transformer。
大概从 2017 年开始,Transformer 作为一种新型的神经网络结构开始引起研究人员的广泛关注。
Transformer 与处理序列数据常用的循环神经网络(RNN)不同,Transformer 中的注意力机制并不会按照顺序来处理数据,也就是说,每个元素和序列中的所有元素都会产生联系,这样就保证了不管在时序上相距多远,元素之间的相关性都可以被很好地保留。通俗点说就是会「联系上下文」,而且还会抓重点。
Transformer 首先被应用在自然语言处理领域(NLP),用来处理序列文本数据。在自然语言处理领域取得广泛应用后,Transformer 也被成功移植到了很多视觉任务上,比如「图像分类,物体检测」等,并同样取得了不错的效果。而且,Transformer 在海量数据上可以获得更大的性能提升,这不正好就是自动驾驶领域所需要的吗?
正是因为看到了这一点,面向量产的自动驾驶公司在拥有数据收集优势的情况下,自然就会倾向于选择 Transformer 作为其感知算法的主体。
2021 年夏天,特斯拉的自动驾驶技术负责人 Andrej Karpathy 在 AI Day 上,公开了 FSD 自动驾驶系统中采用的算法,而 Transformer 则是其中最核心的模块之一。
BEV 感知技术要广泛应用,离不开 Transformer 这样的模块进行空间坐标系的转换,比如将 2D 图像转换到 3D 空间里去。
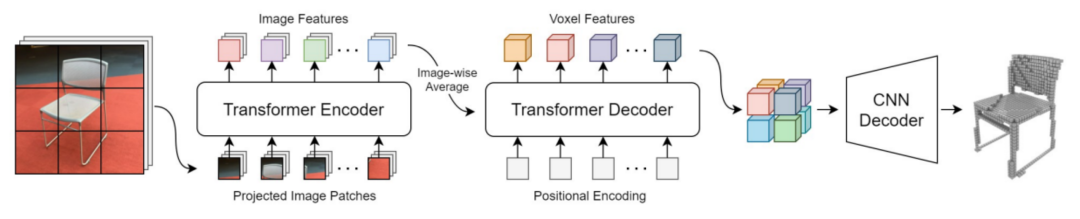
其架构简单说就是:先通过一个共享的主干网络来提取每个相机的特征,然后再通过 Transformer 等将多摄像头数据,完成从图像空间到 BEV 空间(3D)的转换。
在 BEV 空间内,由于坐标系相同,可以很方便地将图像数据和激光雷达、毫米波雷达数据进行融合,还可以进行时序融合形成 4D 空间,这也是当下 BEV 技术的大趋势。当然,特斯拉目前不需要融合激光雷达数据。
BEV 感知技术很好地解决了传感器融合的很多阻碍性难题,而且也给了后续异构传感器大量上车之后的融合提供了借鉴。
国内的自动驾驶团队百度 Apollo 也经历了这个过程,他们在 2019 年推出了 Apollo Lite 方案,其实也是一个多摄像头融合的方案,包括单目前视+多个环视。
他们当时也是采用后融合方式来做。
在这个感知方案的整体框架方面,每一个不同朝向的相机,会先经过一个神经网络去推理出相机下面的障碍物位置、大小、朝向等信息;单相机里面的目标跟踪,以及多相机融合等都是一些基于规则的方案去做的。
百度团队在单相机里面把深度学习做到一个比较高的程度了,整个单相机里面的 3D 感知信息都可以通过模型来输出,然后基于 3D 标注结果,直接端到端产出单相机的结果。
在过去的几年里,单相机的 3D 感知能力也有一个比较大的提升,但是最后也遇到了一些瓶颈,比如有一些截断的物体,在一个相机里面是看不全的,就没办法很好地去对它做感知。
另外,一些跟踪和平滑策略在图像视角下,和最后规划控制模块所要的输出空间其实是不一致的,这样会总体上限制自动驾驶的能力。
所以在过去一年里,百度 Apollo 的团队也将 BEV 感知应用了进来,整体上使用一种持续并列的框架去端到端地做障碍物检测、轨迹预测以及道路结构感知,整体上会有一个时间序列,多幅图像输入进来。然后通过图像的特征提取器之后,得到图像视角的特征,然后再通过 Transformer 把那个特征投影到一个统一的 BEV 空间,再经过解码,最终得到一个端到端的一个 3D 感知效果。
特别是在道路结构这一部分,百度因为有自己的高精地图数据,把这些数据和车辆的高精定位信息结合起来,是可以直接转换成 BEV 道路结构的训练数据,用于算法的训练。
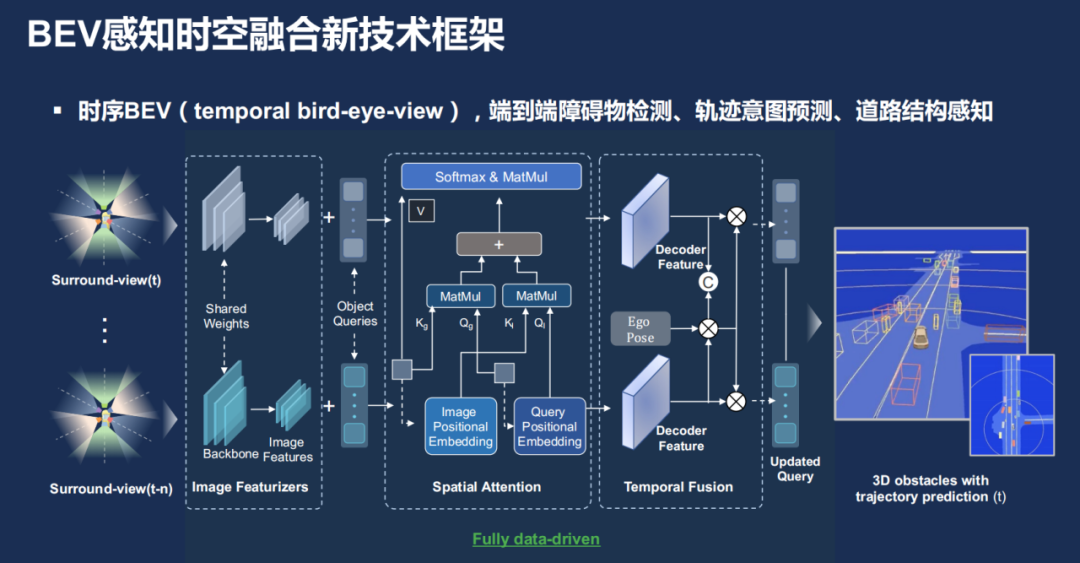
也正是在 BEV 感知技术的加持下,百度的导航辅助驾驶 ANP 3.0 系统正在加速落地,这套系统能覆盖高速场景、城市场景,甚至能自动通过收费站。作为已经确定应用这套能力的集度 ROBO-01 车型,最近也已经去到交通流复杂的广州进行测试,去征服更多的感知难题。
除了像特斯拉和 Apollo Lite 这种纯视觉自动驾驶方案,国内现在掀起的是多传感器融合方案,激光雷达(单颗或多颗)、摄像头(像素越来越高)、毫米波雷达、超声波传感器等等。
这么多的异构传感器放在一起,感知数据如何融合?视觉数据和激光雷达点云数据如何融合?它们一个是 2D 图像空间,一个是 3D 空间,如何比较稳定的融合,而且效果还要好?
答案依然是 BEV 感知。
如前文所述,可以先通过 Transformer 把视觉的 2D 图像转换到 3D 坐标下,和其他的传感器数据如激光雷达点云在空间坐标上保持一致,在相同坐标下融合起来就更加游刃有余。
如果从国内的这些车企和供应商的选择来看,BEV 感知已经是主流了。
而 BEV 感知技术成为应用主流,也意味着其将推动导航辅助驾驶这类功能更快量产、更好地落地。
一方面,那些应用 BEV 感知技术的造车新势力们,能更加好的提升系统的感知能力,让功能的体验更好。
另一方面,那些应用 BEV 感知技术的智驾供应商,能够更快去适配不同车企、不同车型的五花八门的需求,比如他们对车上智驾传感器的不同配置的需求,可以灵活应变,在感知效果上也不会因为传感器配置变化而变得不稳定、不可控。
03
哪些公司在用BEV?
虽然 BEV 感知技术不能解决自动驾驶感知领域的一切疑难杂症,但它提供了一个相比图像更加贴近物理世界的空间,可以给后续的融合、规划提供更多的可能性。
现在很多自研智驾系统的车企以及智驾供应商都在使用 BEV 技术。
比如车企里面的蔚来、理想、小鹏;供应商里面的百度 Apollo、毫末智行、纽劢科技、地平线;Robotaxi 公司转型做智驾系统供应商的轻舟智航、小马智行等等。
每一家在具体使用这项技术的时候肯定会有不同,但是大致的技术框架应该如下:
先将摄像头数据输入到共享的骨干网络(Backbone),提取每个摄像头的数据特征(Feature);
把所有的摄像头数据进行融合,并转换到 BEV 空间;
在 BEV 空间内,进行异构传感器数据融合,将视觉数据和激光雷达点云进行融合;
进行时序融合,形成 4D 时空维度的感知信息(3D+速度);
进行多任务输出,可以是静态语义地图、动态检测和运动预测等,给到下游规控模块使用。
就拿刚刚公布要进行智驾系统量产上车的小马智行来讲,其已明确自研了 BEV 感知算法。
可通过大模型识别各类型障碍物、车道线及可通行区域等信息,最大限度降低算力需求,同时在无高精地图的情况下,仅用导航地图也可实现高速与城市导航辅助驾驶功能。
特别是在高速场景中,小马智行压榨传感器的性能,用鱼眼相机参与行车 BEV 感知模型,减少对传感器数量的依赖—— 使用 6 个摄像头(4 个鱼眼相机及前后向各 1 个长距相机)与 1 个前向毫米波雷达就可以实现高速导航辅助驾驶这样的功能。
成功推出高速及城市 NOH 系统的毫末智行在感知领域同样采用了 BEV 融合感知技术,毫末的融合感知其实包含三个不同的维度:空间、时间和传感器。
空间融合主要是将来自多个相机的图像转换到统一的 BEV 坐标,再进行特征层融合;另外,单帧的信息会有很大的随机性,因此,时序信息对于自动驾驶环境感知来说是非常重要的,毫末的时序融合也是采用了车辆自身的运动信息来统一多帧数据的空间坐标系,从而在一个统一的空间坐标系下融合来自不同时间的数据。
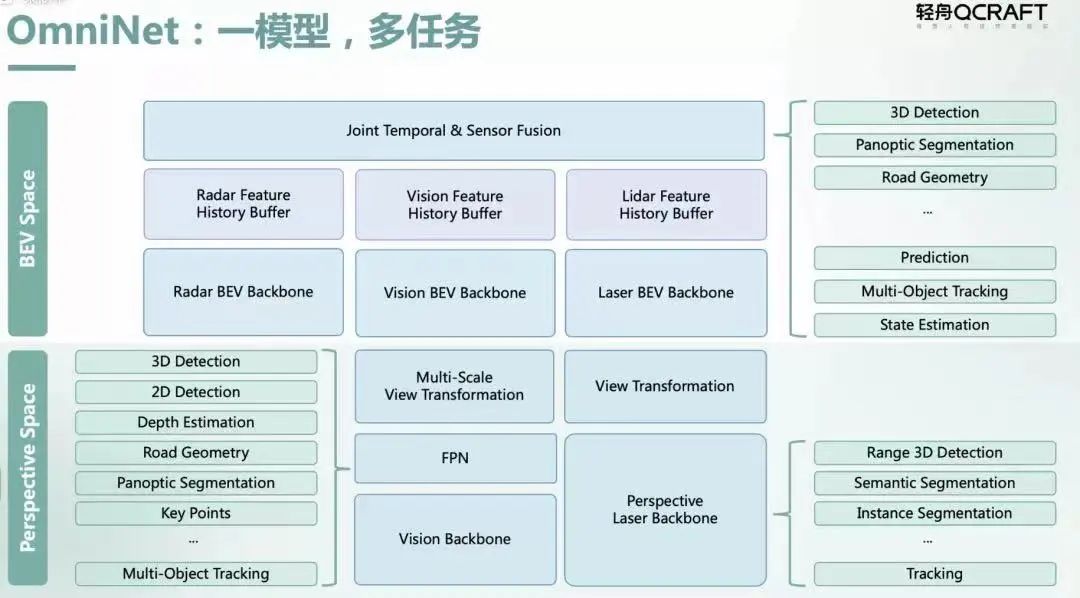
轻舟智航去年发布的 OmniNet 感知融合大模型就是将视觉、毫米波雷达、激光雷达等数据通过前融合和 BEV 空间特征融合,让本来独立的各个计算任务通过共享主干网络(Backbone)和记忆网络(Memory Network)进行高效多任务统一计算,最终同时在图像空间和 BEV 空间中输出不同感知任务的结果,为下游的预测和规划控制模块提供更丰富的输出。
虽然地平线是一家芯片企业,但是其打造的 SuperDrive 全场景智能驾驶方案里,其实也应用了感知融合 BEV 技术,这套方案可支持高速、城区、泊车场景自动驾驶,目前正给吉利方面供货。
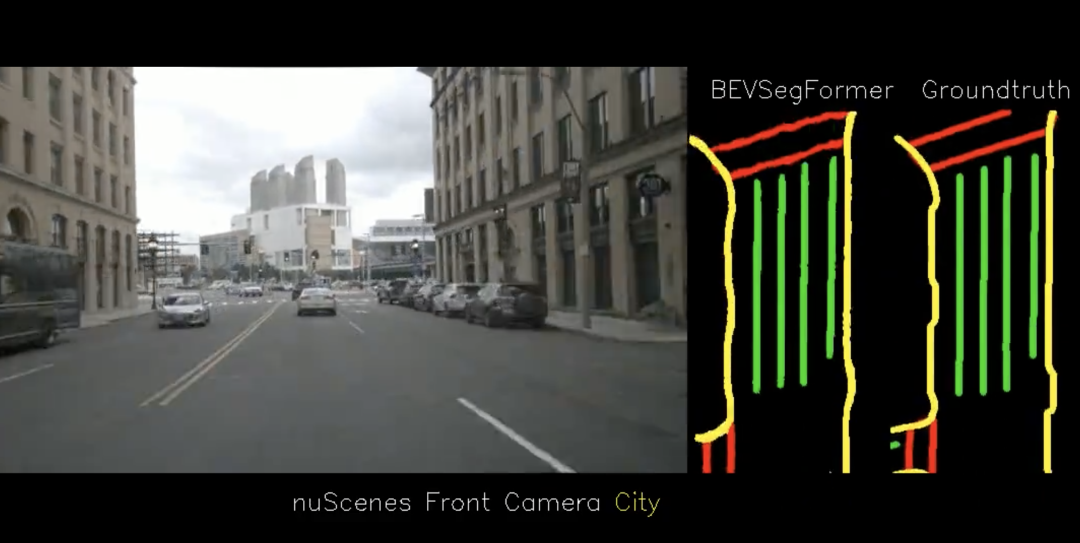
智驾供应商纽劢科技的感知团队也基于 BEV 提出了 BEVSegFormer,一种基于 Transformer 的 BEV 语义分割方法,可面向任意配置的相机进行 BEV 语义分割。
具体来说,BEVSegFormer 首先使用了共享的主干网络,对来自任意相机的图像特征进行编码,然后通过基于可变形 Transformer 的编码器对这些特征进行增强。BEVSegFormer 还引入了一个 BEV Transformer 解码器模块,对 BEV 语义分割的结果进行解析,以及一种高效的多相机可变形注意单元,完成 BEV 到图像的视图变换。最后,根据 BEV 中的网格布局对查询进行重塑,并进行上采样,以有监督的方式生成语义分割结果。
在车企方面,理想汽车的 L9 车型所搭载的 AD Max 系统也应用了融合感知 BEV 技术,它利用所谓「纯视觉」进行运动感知预测,同时多传感融合和高精地图的信息输入作为辅助。
另外,蔚来自动驾驶 NAD 系统,在 2023 年的上半年,也会进行底层感知架构的切换,转向 BEV 模型,向特斯拉看齐。
当然,以上并未完全列出所有采用 BEV 技术的行业玩家。
BEV 技术成为了厂商们选择的主流感知融合技术,该如何去定位这一技术?MAXIEYE CEO 周圣砚是这么看的:BEV 是深度学习之后的又一个新台阶,解决了过去多传感器的变化和异构带来的各种各样的融合感知算法的开发问题。
04
BEV还有什么新的玩法吗?
当 BEV 感知技术成为主流,而且被多数厂商采用的时候,有些企业就开始对其进行改造了。
在今年 Create AI 开发者大会上,百度就在 BEV 感知基础上,提出了一个叫做「车路一体 BEV」的感知方案,取名叫 UniBEV,有点像「联合 BEV」。
简单点理解就是,UniBEV 不但会将车端的感知数据拿过来做融合,也会将路端的感知数据也放进来,放到同一个坐标系下。BEV 本来就是个上帝视角了,这里再加上路端的超视距感知数据,那简直是开挂一般的存在。但什么时候能在车端量产应用现在还不太清楚。
具体来看看 UniBEV 的框架。
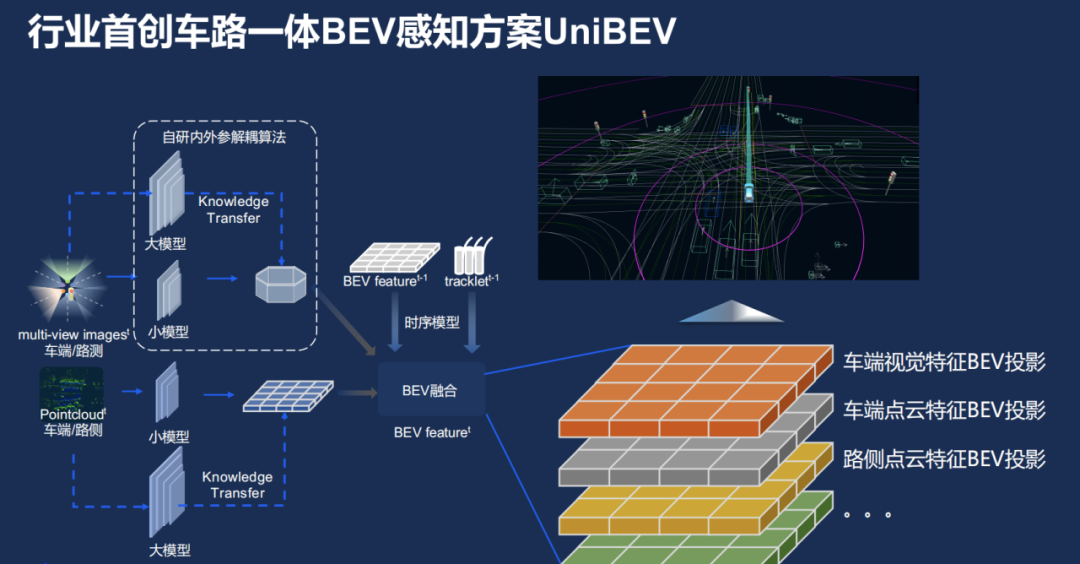
框架中的虚线框里有一个自研的内外参解耦算法,这里的内外参指的是传感器的内外参数,比如相机内参数,指的是与相机自身特性相关的参数,比如焦距、像素大小等;而相机外参数则是相机在真实世界坐标系中的参数,比如相机的安装位置、旋转方向等。
那为何要把内外参解耦呢?百度说他们作为智驾方案商,需要把方案供应给不同的车厂,不同车厂车型会有不一样的传感器配置,比如供给集度的和供给比亚迪的传感器方案就会不一样。
有了这个解耦算法,可以把不同相机解耦开,让每个相机独立,这样不管传感器的相对位置如何变,研发团队都可以将其投影到一个统一的 BEV 空间下。
框架中另一部分是车端和路侧的点云,而且路侧也会装一些摄像头,这些数据的特征到最后都会投影到一个统一的 BEV 空间下,便能把可能的信息都融合起来。
最终,在 UniBEV 加持下,百度的智驾系统在车端、路侧的动静态感知任务上都有不错的表现。
当然,也不是谁家都能搞这样的车路一体 BEV 感知的,因为这也需要有大量的路段感知设备传回的数据,这是需要路侧基建的。目前国内,百度是为数不多有车路协同路端基建业务的智驾供应商,这一点也强化了 UniBEV 的独特性。
当然,我们也期待其他厂商,基于 BEV 感知技术再研究出更加突破性的技术,助力自动驾驶技术在感知领域的大跃进。
-
请问手头上有NI9232、NI9068,还有电流传感器日置CT6841,请问能有什么玩法呢?2017-08-09 2975
-
Huawei Share的最全玩法2019-08-27 10357
-
手机AI有诸多新奇玩法2019-08-29 3715
-
改善BEV的新兴技术是什么?2020-07-16 1139
-
BEV和PHEV数据2021-02-01 3470
-
电视还有新玩法?海尔电视四大场景一屏多体验2021-10-11 954
-
BEVSegFormer创造了新的BEV分割SOTA2022-04-27 3814
-
BEV+Transformer对智能驾驶硬件系统有着什么样的影响?2023-02-16 3613
-
BEV人工智能transformer2023-08-22 1454
-
CVPR上的新顶流:BEV自动驾驶感知新范式2023-08-23 1647
-
BEV感知中的Transformer算法介绍2023-09-04 2595
-
利用Transformer BEV解决自动驾驶Corner Case的技术原理2023-10-11 1800
-
BEV感知的二维特征点2023-11-14 1260
-
自动驾驶领域中,什么是BEV?什么是Occupancy?2024-01-13 4283
-
BEV和Occupancy自动驾驶的作用2024-01-17 1343
全部0条评论

快来发表一下你的评论吧 !
