

英伟达耗费64个A100训练StyleGAN-T!
描述
扩散模型在文本到图像生成方面是最好的吗?不见得,英伟达等机构推出的新款 StyleGAN-T,结果表明 GAN 仍具有竞争力。
文本合成图像任务是指,基于文本内容生成图像内容。当下这项任务取得的巨大进展得益于两项重要的突破:其一,使用大的预训练语言模型作为文本的编码器,让使用通用语言理解实现生成模型成为可能。其二,使用由数亿的图像 - 文本对组成的大规模训练数据,只要你想到的,模型都可以合成。
训练数据集的大小和覆盖范围持续飞速扩大。因此,文本生成图像任务的模型必须扩展成为大容量模型,以适应训练数据的增加。最近在大规模文本到图像生成方面,扩散模型(DM)和自回归模型(ARM)催生出了巨大的进展,这些模型似乎内置了处理大规模数据的属性,同时还能处理高度多模态数据的能力。
有趣的是,2014 年,由 Goodfellow 等人提出的生成对抗网络(GAN),在生成任务中并没有大放异彩,正当大家以为 GAN 在生成方面已经不行的时候,来自英伟达等机构的研究者却试图表明 GAN 仍然具有竞争力,提出 StyleGAN-T 模型。

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
论文地址:https://arxiv.org/abs/2301.09515
论文主页:https://sites.google.com/view/stylegan-t/
StyleGAN-T 只需 0.1 秒即可生成 512×512 分辨率图像:

StyleGAN-T 生成宇航员图像:

值得一提的是,谷歌大脑研究科学家 Ben Poole 表示:StyleGAN-T 在低分辨率 (64x64) 时生成的样本比扩散模型更快更好,但在高分辨率 (256x256) 时表现不佳。
研究者们表示,他们在 64 台 NVIDIA A100 上进行了 4 周的训练。有人给这项研究算了一笔账,表示:StyleGAN-T 在 64 块 A100 GPU 上训练 28 天,根据定价约为 473000 美元,这大约是典型扩散模型成本的四分之一……
GAN 提供的主要好处在于推理速度以及可以通过隐空间控制合成的结果。StyleGAN 的特别之处在于,其具有一个精心设计的隐空间,能从根本上把控生成的图像结果。而对于扩散模型来说,尽管有些工作在其加速方面取得了显著进展,但速度仍然远远落后于仅需要一次前向传播的 GAN。
本文从观察到 GAN 在 ImageNet 合成中同样落后于扩散模型中得到启发,接着受益于 StyleGAN-XL 对判别器的架构进行了重构,使得 GAN 和扩散模型的差距逐渐缩小。在原文的第 3 节中,考虑到大规模文本生成图像任务的特定要求:数量多、类别多的数据集、强大的文本对齐以及需要在变化与文本对齐间进行权衡,研究者以 StyleGAN-XL 作为开始,重新审视了生成器和判别器的架构。
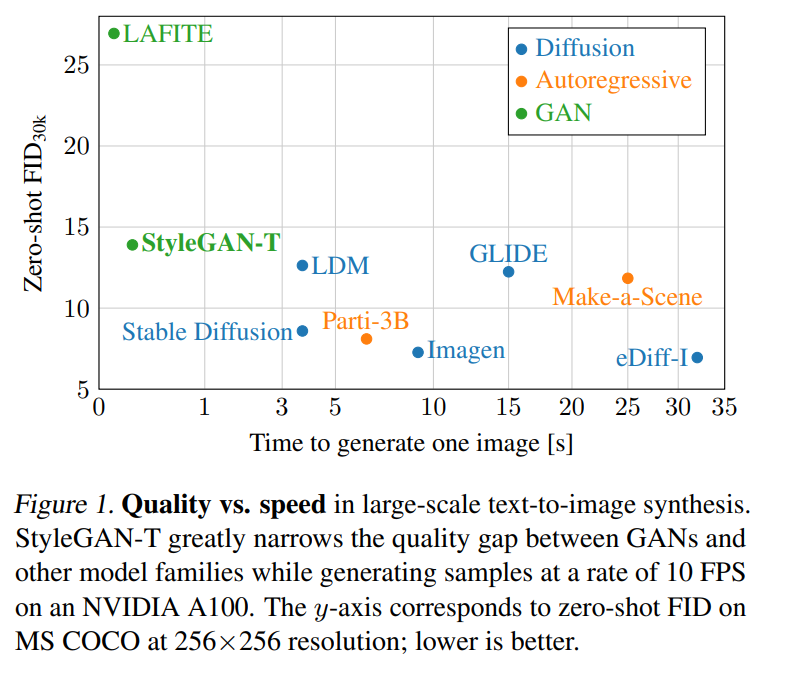
在 MS COCO 上的零样本任务中,StyleGAN-T 以 64×64 的分辨率实现了比当前 SOTA 扩散模型更高的 FID 分数。在 256×256 分辨率下,StyleGAN-T 更是达到之前由 GAN 实现的零样本 FID 分数的一半,不过还是落后于 SOTA 的扩散模型。StyleGAN-T 的主要优点包括其快速的推理速度和在文本合成图像任务的上下文中进行隐空间平滑插值,分别如图 1 和图 2 所示。

StyleGAN-T 架构概览
该研究选择 StyleGAN-XL 作为基线架构,因为 StyleGAN-XL 在以类别为条件的 ImageNet 合成任务中表现出色。然后该研究依次从生成器、判别器和变长与文本对齐的权衡机制的角度修改 StyleGAN-XL。
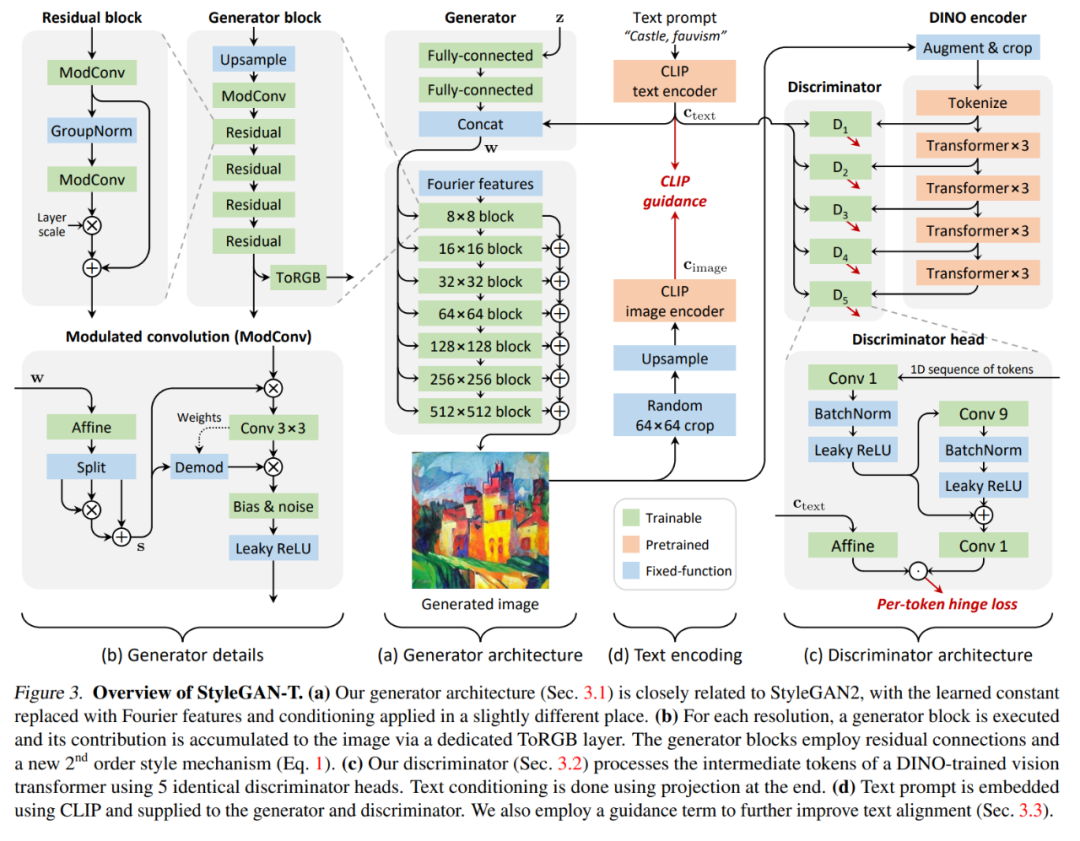
在整个重新设计过程中,作者使用零样本 MS COCO 来衡量改动的效果。出于实际原因,与原文第 4 节中的大规模实验相比,测试步骤的计算资源预算有限,该研究使用了更小模型和更小的数据集;详见原文附录 A。除此以外,该研究使用 FID 分数来量化样本质量,并使用 CLIP 评分来量化文本对齐质量。
为了在基线模型中将以类别为引导条件更改为以文本为引导条件,作者使用预训练的 CLIP ViT-L/14 文本编码器来嵌入文本提示,以此来代替类别嵌入。接着,作者删除了用于引导生成的分类器。这种简单的引导机制与早期的文本到图像模型相匹配。如表 1 所示,该基线方法在轻量级训练配置中达到了 51.88 的零样本 FID 和 5.58 的 CLIP 分数。值得注意的是,作者使用不同的 CLIP 模型来调节生成器和计算 CLIP 分数,这降低了人为夸大结果的风险。
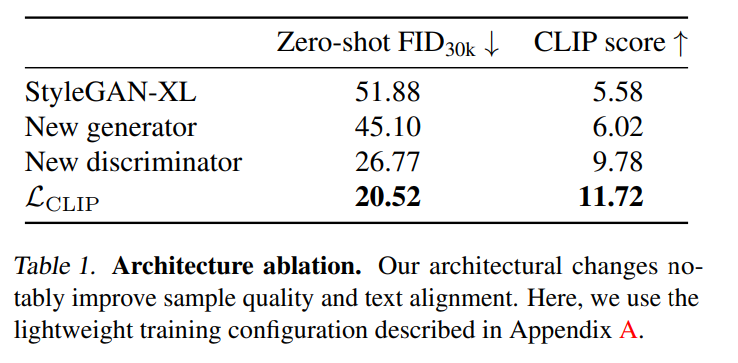
实验结果
该研究使用零样本 MS COCO 在表 2 中的 64×64 像素输出分辨率和表 3 中的 256×256 像素输出分辨率下定量比较 StyleGAN-T 的性能与 SOTA 方法的性能。
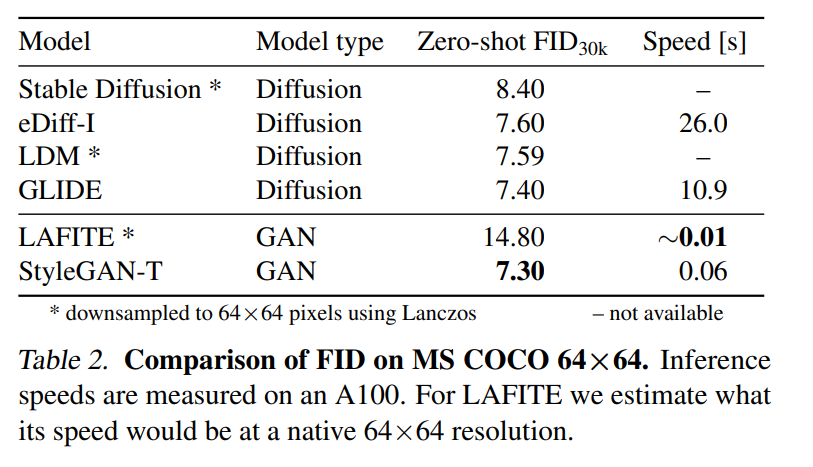
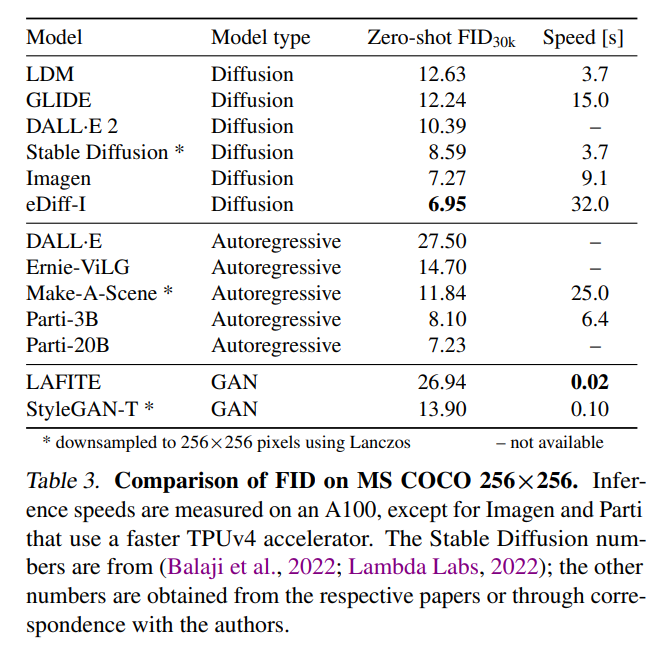
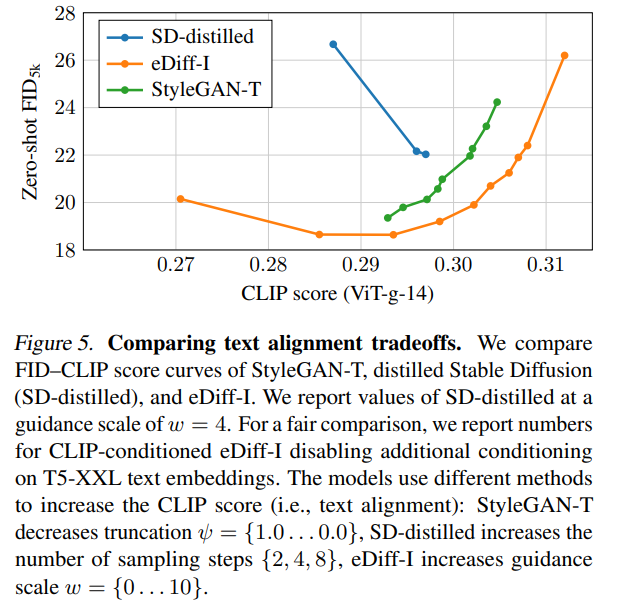
图 5 展示了 FID-CLIP 评分曲线:
为了隔离文本编码器训练过程产生的影响,该研究评估了图 6 中的 FID–CLIP 得分曲线。
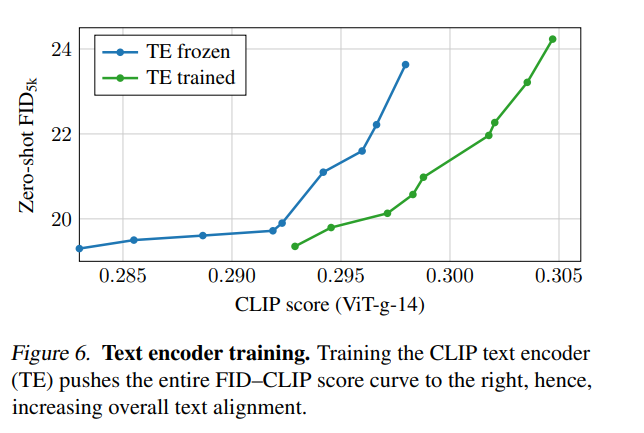
图 2 显示了 StyleGAN-T 生成的示例图像,以及它们之间的插值。
在不同的文本提示之间进行插值非常简单。对于由中间变量 w_0 = [f (z), c_text0] 生成的图像,该研究用新的文本条件 c_text1 替换文本条件 c_text0。然后将 w_0 插入到新的隐变量 w_1 = [f (z), c_text1] 中,如图 7 所示。

通过向文本提示附加不同的样式,StyleGAN-T 可以生成多种样式,如图 8 所示。

审核编辑 :李倩
-
英伟达H200和A100的差异2024-03-07 7262
-
英伟达v100与A100的差距有哪些?2023-08-22 27990
-
英伟达a100和h100哪个强?英伟达A100和H100的区别2023-08-09 52210
-
英伟达A100和V100参数对比2023-08-08 18086
-
英伟达a100和h100哪个强?2023-08-07 18164
全部0条评论

快来发表一下你的评论吧 !
