

一种使用2D激光雷达在室内场景下估计机器人姿态的方法
描述
摘要
确定移动机器人的状态是机器人导航系统中重要的组成部分。在本文中,我们提出了一种使用2D激光雷达在室内场景下估计机器人姿态的方法,并探讨了如何将新型的场景表示模型整合到标准蒙特卡罗定位(MCL)系统中。在计算机视觉领域,神经辐射场 (Neural Radiance Fields, NeRF)是用一个隐式函数来表示环境。我们将NeRF这样的隐式环境表示扩展到移动机器人二维室内定位任务中,提出了一种神经占据场,使用神经网络来隐式的表示用于替代机器人定位任务中的二维地图。
通过预训练的神经网络,我们可以渲染合成当前场景下任意机器人姿态所对应的的2D 激光扫描。基于该隐式地图,我们提出了一个观测模型来计算渲染和真实扫描之间的相似性,并将其集成到MCL系统中进行准确的定位。我们在一组自己收集的数据集和三个公开可用的数据集上进行评估。实验结果证明我们的方法可以准确高效地估计机器人的姿态,并在定位性能优于现有的方法。实验表明,所提出的隐式地图模型能够更准确的表示场景,从而提升了MCL系统中观测模型的性能。
主要贡献
我们提出了神经占据场,一种隐式场景表示模型,在该模型之上提出了一个高性能的观测模型,并整合到基于2D 激光的全局定位系统之中; 我们通过多个数据集的实验评估,实验结果证明,与使用传统场景表示模型(例如:占据栅格地图,希尔伯特地图)相比,我们的方法在机器人全局定位方面具有竞争力的性能,且能快速收敛,并实时运行。
主要方法
隐式场景表示
我们利用一组已知准确姿态的2D激光数据作为训练样本。如下图所示,首先根据每一个样本的姿态和2D激光雷达的内参设置计算得到激光雷达每一条射线的方向,接着在每一条射线上均匀采样N个空间点。之后,神经网络将采样得到的每一个空间点p作为输入,并输出该空间点所对应的占据概率pocc。
最后,对于每一条射线,利用光线投射(ray-casting)算法根据采样点的深度m及其占据概率pocc进行渲染得到射线所对应的深度值: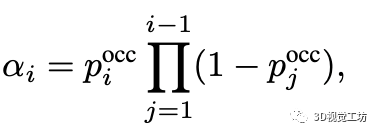
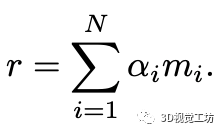
最终,估计出当前机器人姿态下可能会观测到的2D激光扫描。接下来,我们通过计算几何损失以及对预测的占据概率添加正则化来优化神经网络的参数。
几何损失是2D激光扫描的估计值和观测值之间的 L1损失: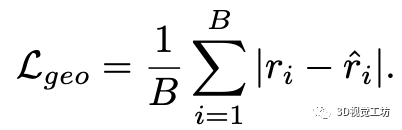
占据概率的正则化通过计算一个负对数似然来约束占据概率的预测值接近于1(被占据)或0(不被占据):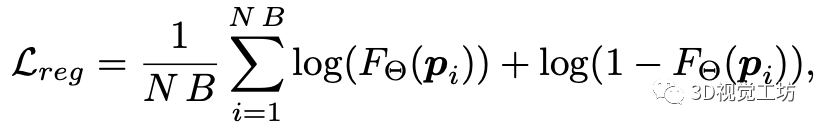
最终,用与优化神经网络参数的损失函数为: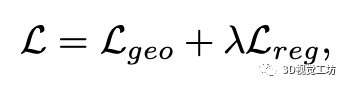
全局定位系统
当神经网络训练完成后,我们可以通过预测环境中任意机器人姿态所对应的2D激光观测。因此,我们将其整合到MCL系统之中,作为一个MCL系统的观测模型。MCL系统如下图所示,为了确定机器人当前的姿态,我们首先在当前场景下采样一定数量的机器人姿态,称之为“粒子”,如图中蓝色圆环所示。
每一个粒子包含了一个假设的机器人姿态和一个权重。当机器人在环境中运行时,基于隐式表示的观测模型将每一个粒子的姿态作为输入,预测其在该姿态下的2D激光扫描,通过和真实的观测值进行比对来更新粒子的权重,并在每一迭代中移除低权重的粒子,保留高权重的粒子。重复该过程,粒子最终会收敛到真实姿态周围的一个小区域。我们最终通过对收敛后的粒子姿态进行加权平均后得到估计的机器人姿态。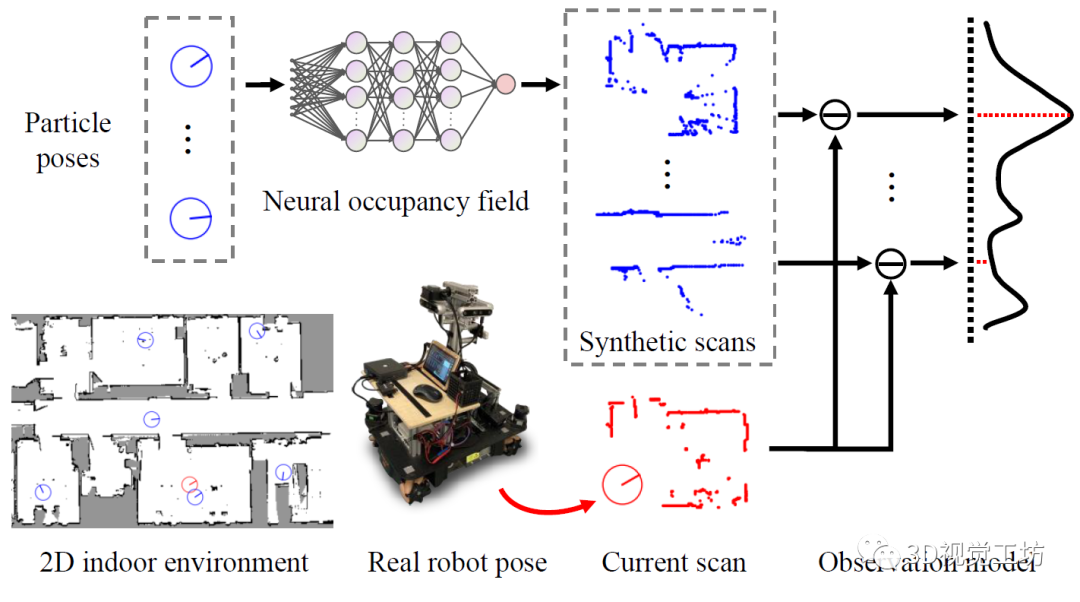
主要结果
室内全局定位
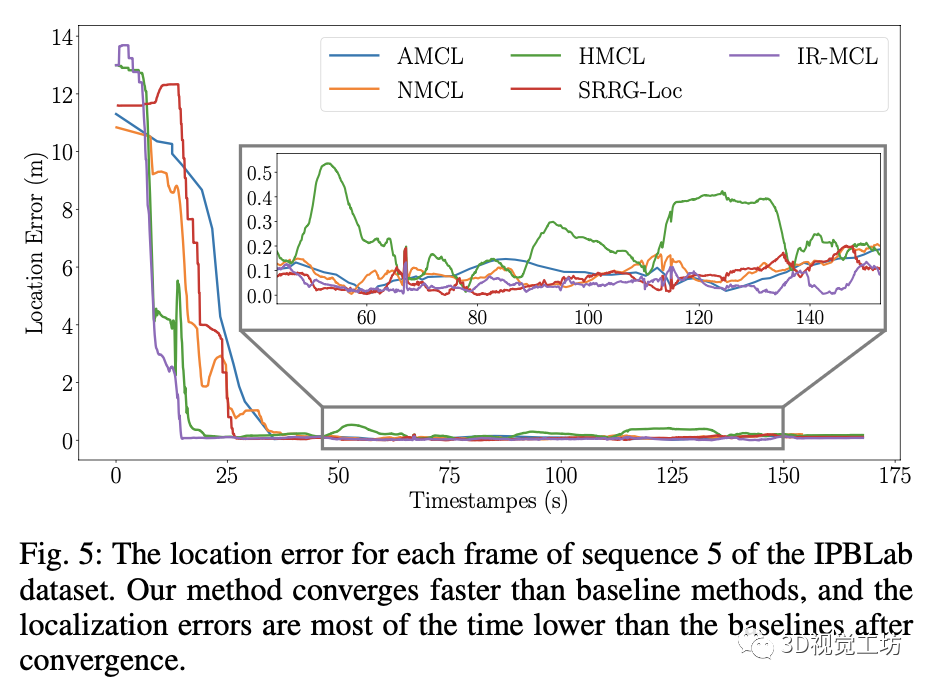
我们将现有的蒙特卡洛定位算法作为基线,在我们收集的数据集上对比了全局定位的精度,实验结果如下所示。实验结果证明,对比于现有的室内定位算法,我们的方法在定位精度上达到了SOTA。此外,相比于之前的方法,我们的算法能更快的收敛。我们还补充了一个姿态追踪实验,用于证明我们的算法在不同量级的粒子数目下依然能表现出精确的定位能力。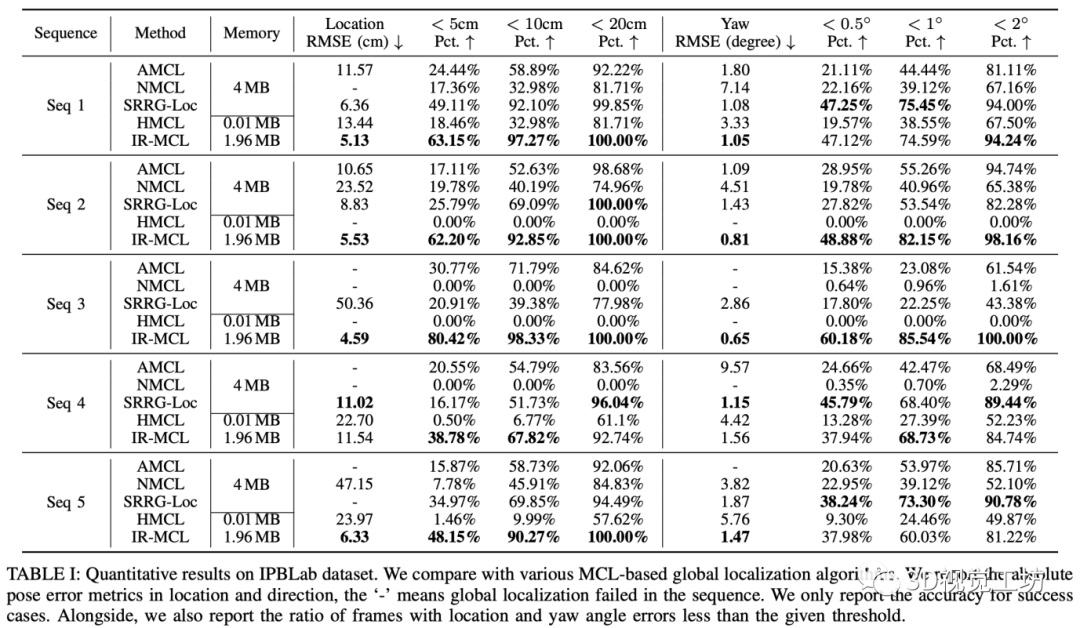
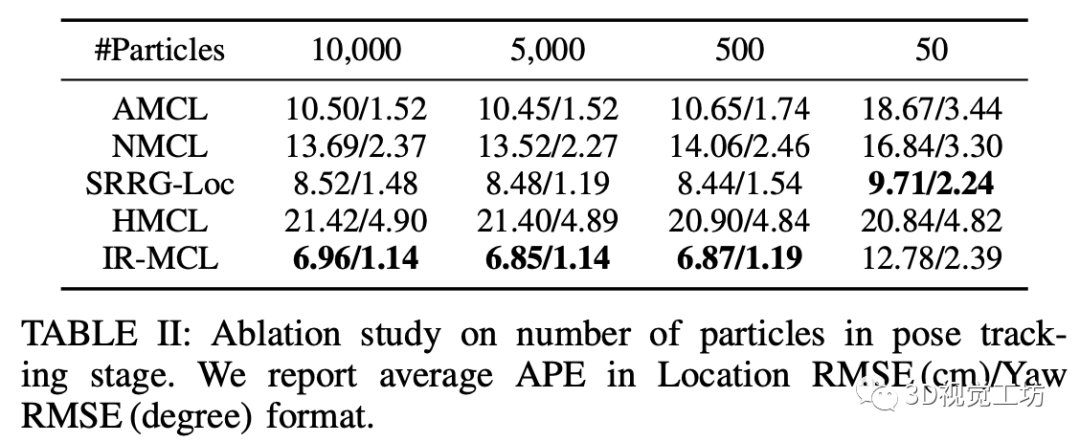
观测模型
我们在三个经典的室内数据集(Freiburg Building 079, Intel Lab, MIT CSAIL)对我们的观测模型进行了评估。通过与基于栅格地图的观测模型进行对比,证明了隐式场景表示是一种更准确的地图表示方法。当训练数据较少时(如MIT CSAIL数据集),在预测没有包含在训练集中的区域时,隐式地图展现出来更好的泛化能力。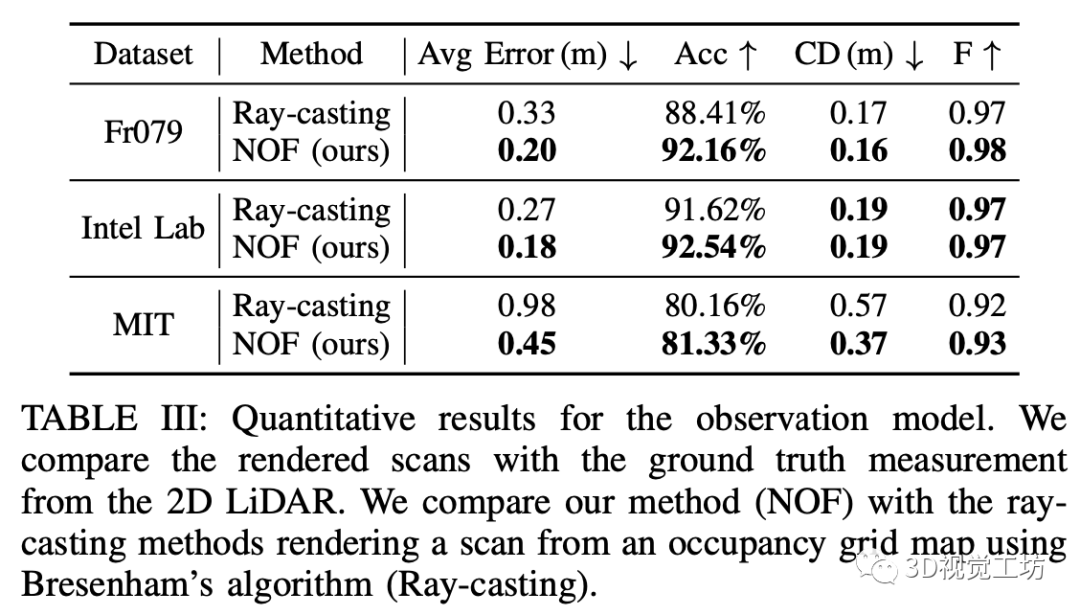
审核编辑:刘清
-
激光导航AGV底盘定制 巡检机器人,服务机器人,智慧物流搬运AGV2017-06-10 8365
-
激光雷达分类以及应用2017-09-19 8923
-
常见激光雷达种类2017-09-25 14027
-
激光雷达除了可以激光测距外,还可以怎么应用?2018-05-11 6124
-
让机器人在陌生环境里穿梭自如的激光雷达2018-09-10 3956
-
除了机器人行业,激光雷达还能应用于哪些领域?2018-12-10 4925
-
机器人和激光雷达都不可或缺2019-02-15 6239
-
TOF激光雷达2019-06-07 9316
-
用于机器人避障的激光雷达避障传感器安装方式详解2020-05-12 7217
-
小米2D激光雷达拆解图讲解2023-09-22 1499
-
激光雷达的分类及其在机器人中的应用2017-10-16 2211
-
傲视智绘单线2D扫描激光雷达介绍2021-01-27 5587
-
小米2D激光雷达拆解资源下载2021-04-06 4407
-
基于激光雷达和视觉融合的机器人SLAM应用研究2022-09-20 5675
-
一径科技NZ系列广角全场景3D激光雷达全面赋能商用清洁机器人2026-03-27 1494
全部0条评论

快来发表一下你的评论吧 !
