

一文浅谈Graph Transformer领域近期研究进展
描述
在图表示学习中,Graph Transformer 通过位置编码对图结构信息进行编码,相比 GNN,可以捕获长距离依赖,减轻过平滑现象。本文介绍 Graph Transformer 的两篇近期工作。
SAT

论文标题:Structure-Aware Transformer for Graph Representation Learning收录会议:ICML 2022
论文链接:
https://arxiv.org/abs/2202.03036
代码链接:
https://github.com/BorgwardtLab/SAT
本文分析了 Transformer 的位置编码,认为使用位置编码的 Transformer 生成的节点表示不一定捕获它们之间的结构相似性。为了解决这个问题,提出了结构感知 Transformer,通过设计新的自注意机制,使其能够捕获到结构信息。新的注意力机制通过在计算注意力得分之前,提取每个节点的子图表示,并将结构信息合并到原始的自注意机制中。
本文提出了几种自动生成子图表示的方法,并从理论上表明,生成的表示至少与子图表示具有相同的表达能力。该方法在五个图预测基准上达到了最先进的性能,可以利用任何现有的 GNN 来提取子图表示。它系统地提高了相对于基本 GNN 模型的性能,成功地结合了 GNN 和 Transformer。
1.1 方法
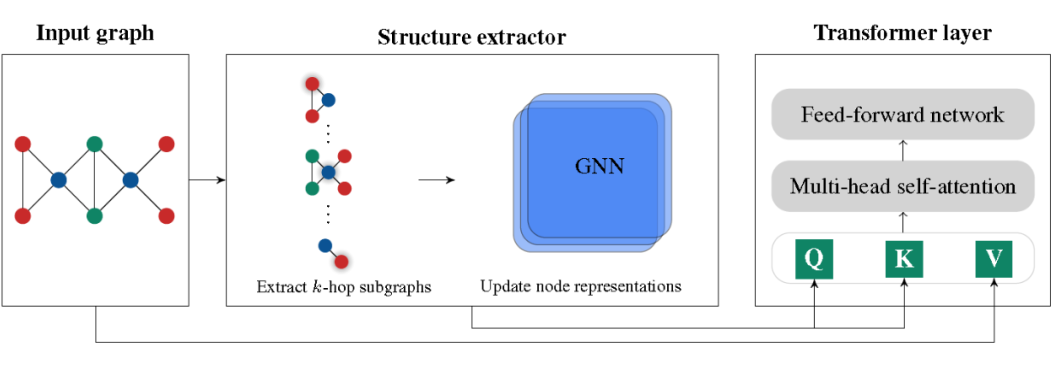
本文提出了一个将图结构编码到注意力机制中的模型。首先,通过 Structure extractor 抽取节点的子图结构,进行子图结构的注意力计算。其次,遵循 Transformer 的结构进行计算。
Structure-Aware Self-Attention
Transformer 原始结构的注意力机制可以被重写为一个核平滑器:
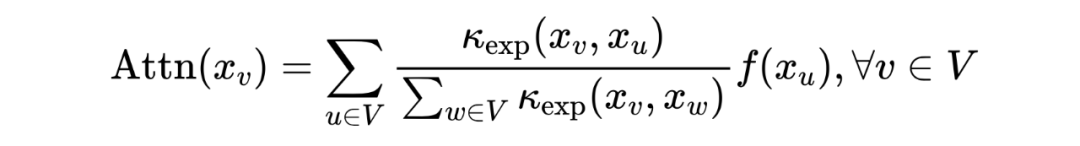
其中, 是一个线性函数。 是 空间中,由 和 参数化的(非对称)指数核:
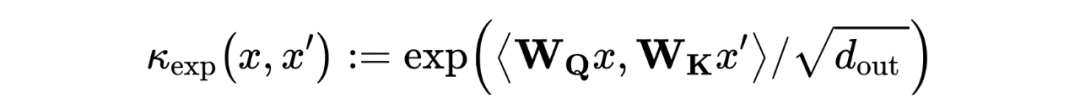
是定义在节点特征上的可训练指数核函数,这就带来了一个问题:当节点特征相似时,结构信息无法被识别并编码。为了同时考虑节点之间的结构相似性,我们考虑了一个更一般化的核函数,额外考虑了每个节点周围的局部子结构。通过引入以每个节点为中心的一组子图,定义结构感知注意力如下:
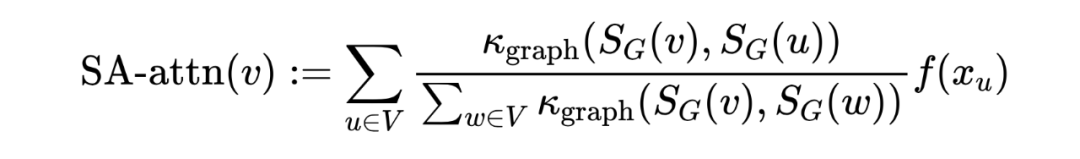
其中, 是节点 在图 中的子图,与节点特征 相关, 是可以是任意比较一对子图的核函数。该自注意函数不仅考虑了节点特征的相似度,而且考虑了子图之间的结构相似度。因此,它生成了比原始的自我关注更有表现力的节点表示。定义如下形式的 :
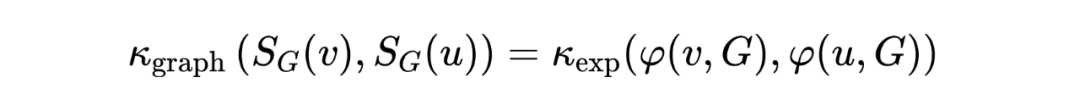
其中 是一个结构提取器,它提取以 为中心、具有节点特征 的子图的向量表示。结构感知自我注意力十分灵活,可以与任何生成子图表示的模型结合,包括 GNN 和图核函数。在自注意计算中并不考虑边缘属性,而是将其合并到结构感知节点表示中。文章提出两种生成子图的方法:k-subtree GNN extractor 和 k-subgraph GNN extractor,并进行相关实验。
1.2 实验
下图是模型在图回归和图分类任务上的效果。
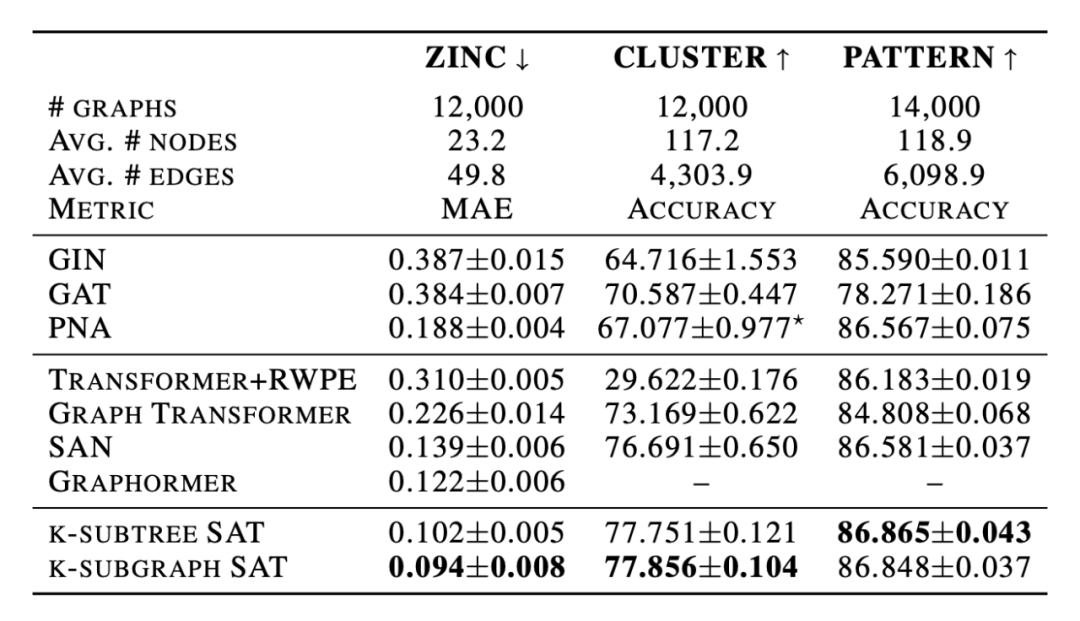
使用 GNN 抽取结构信息后,再用 Transformer 学习特征,由下图可以看出,Transformer 可以增强 GNN 的性能。
GraphGPS

论文标题:Recipe for a General, Powerful, Scalable Graph Transformer收录会议:NeurIPS 2022
论文链接:
https://arxiv.org/abs/2205.12454
代码链接:
https://github.com/rampasek/GraphGPS 本文首先总结了不同类型的编码,并对其进行了更清晰的定义,将其分为局部编码、全局编码和相对编码。其次,提出了模块化框架 GraphGPS,支持多种类型的编码,在小图和大图中提供效率和可伸缩性。框架由位置/结构编码、局部消息传递机制、全局注意机制三个部分组成。该架构在所有基准测试中显示了极具竞争力的结果,展示了模块化和不同策略组合所获得的经验好处。
2.1 方法
在相关工作中,位置/结构编码是影响 Graph Transformer 性能的最重要因素之一。因此,更好地理解和组织位置/结构编码将有助于构建更加模块化的体系结构,并指导未来的研究。本文将位置/结构编码分成三类:局部编码、全局编码和相对编码。各类编码的含义和示例如下表所示。 现有的 MPNN + Transformer 混合模型往往是 MPNN 层和 Transformer 层逐层堆叠,由于 MPNN 固有结构带来的过平滑问题,导致这样的混合模型的性能也会受到影响。因此,本文提出新的混合架构,使 MPNN 和 Transformer 的计算相互独立,获得更好的性能。具体框架如图所示。
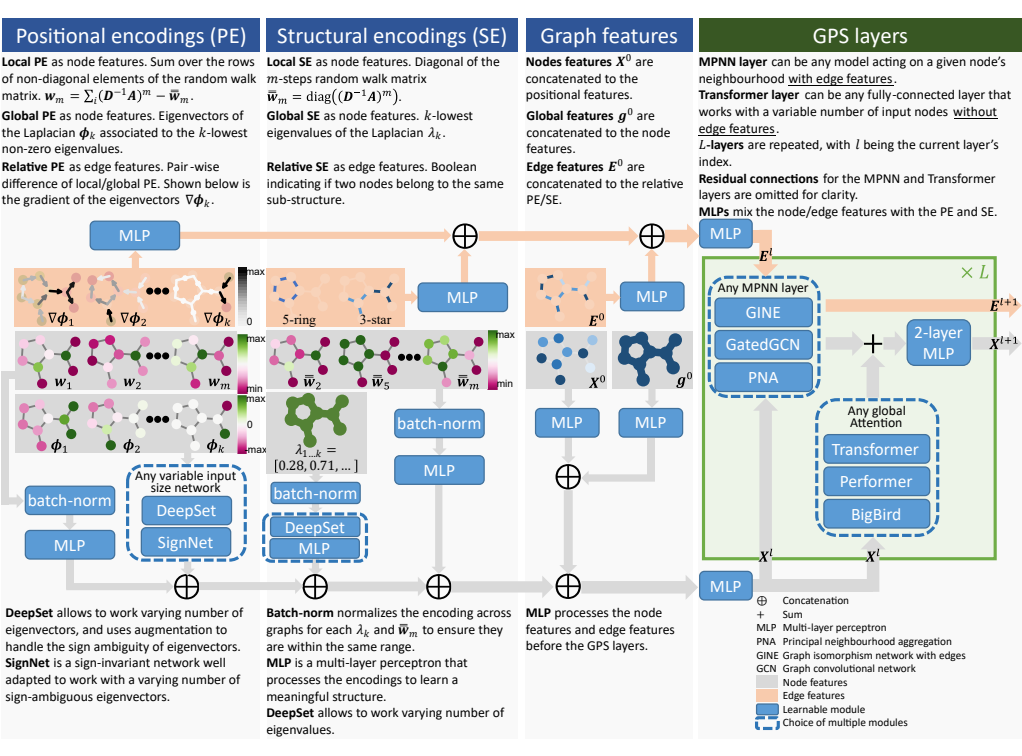
框架主要由位置/结构编码、局部消息传递机制(MPNN)、全局注意机制(Self Attention)三部分组成。根据不同的需求设计位置/结构编码,与输入特征相加,然后分别输入到 MPNN 和 Transformer 模型中进行训练,再对两个模型的结果相加,最后经过一个 2 层 MLP 将输出结果更好的融合,得到最终的输出。更新公式如下:
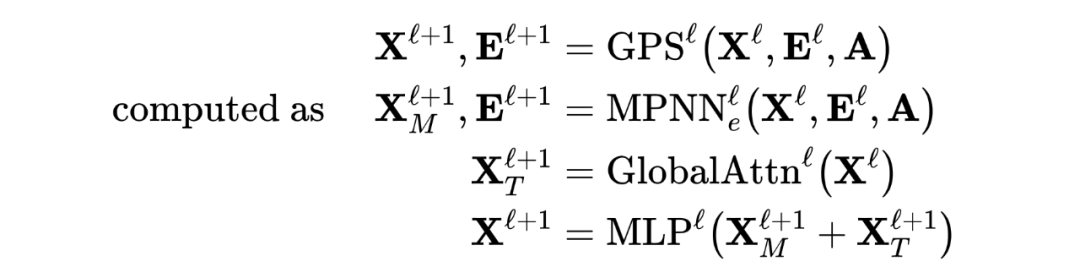
2.2 实验
在图级别的任务上,效果超越主流方法:
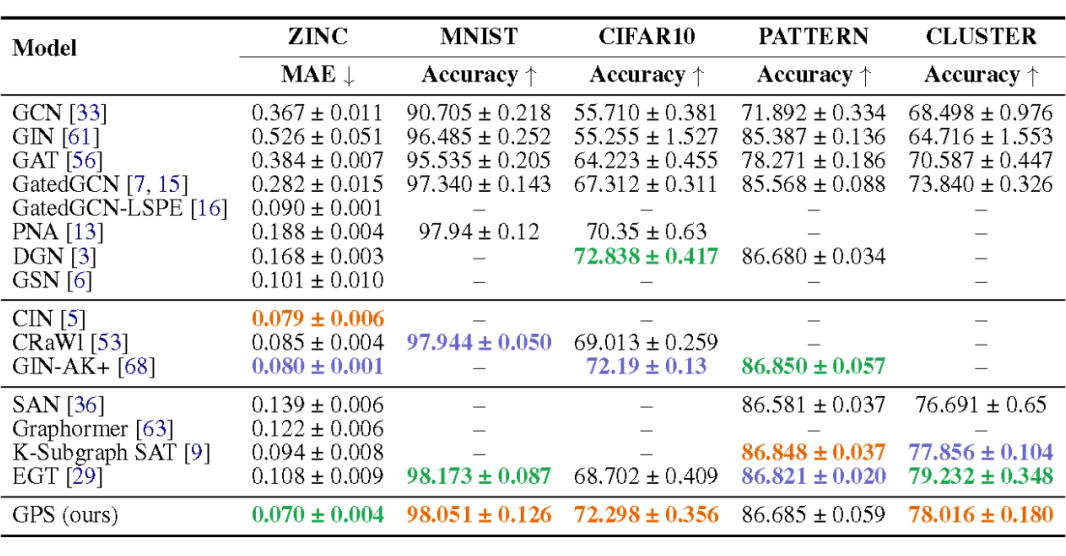
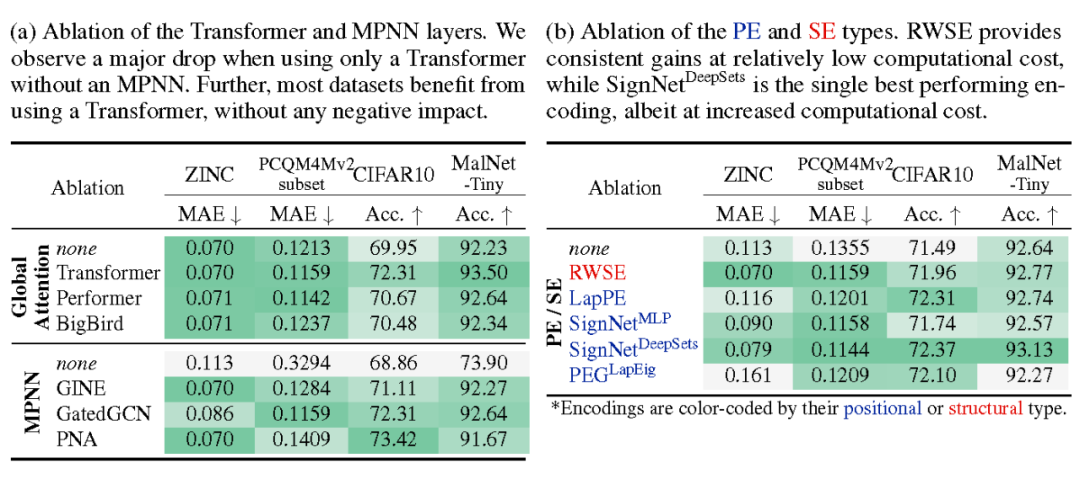
通过消融实验,研究框架中各个结构的作用,可以看到,MPNN 和位置/结构编码模块对 Transformer 的效果均有提升作用。
总结
两篇文章都有一个共同特点,就是采用了 GNN + Transformer 混合的模型设计,结合二者的优势,以不同的方式对两种模型进行融合,GNN 学习到图结构信息,然后在 Transformer 的计算中起到提供结构信息的作用。在未来的研究工作中,如何设计更加合理的模型,也是一个值得探讨的问题。
审核编辑 :李倩
-
新型铜互连方法—电化学机械抛光技术研究进展2009-10-06 7419
-
室内颗粒物的来源、健康效应及分布运动研究进展2010-03-18 3619
-
薄膜锂电池的研究进展2011-03-11 3129
-
太赫兹量子级联激光器等THz源的工作原理及其研究进展2019-05-28 2597
-
一维光子晶体研究进展2009-03-11 1063
-
铜电车线材料的研究进展2009-07-06 553
-
声频定向扬声器的研究进展2010-01-08 917
-
锂离子电池合金负极材料的研究进展2009-10-28 4966
-
CMOS_Gilbert混频器的设计及研究进展2015-12-21 926
-
移动互联网QoS机制的研究进展述评2016-01-04 789
-
物联网隐私保护研究进展2016-03-24 721
-
共振式无线电能传输技术的研究进展与应用综述2017-01-05 1138
-
无人车领域的主要研究进展分析2018-10-28 9731
-
AI指数报告 看几大国AI领域的研究进展和趋势大比拼2019-03-01 1060
-
农业机械自动导航技术研究进展2021-03-16 1327
全部0条评论

快来发表一下你的评论吧 !
