

基于4.9内核的PMU的基本操作及编程
嵌入式技术
描述
1. 垫话
本文标题叫“硬件 PMU”操作,而不是“PMU 硬件”操作,是为了有意强调上一篇文章所申明的概念:PMU 只是一种抽象,其可以是纯软件实现的,也可以是硬件实现的。所以本文分析“硬件 PMU”,是有其推广意义的:“硬件 PMU”是 PMU 的一个特殊解,清楚了“硬件 PMU”的抽象及操作,基本也就清楚了 perf 框架对其他 PMU(软件 PMU、trace point PMU)的抽象及操作。 软件架构的设计无非就是前后端的双向打通,前端是面向用户的 user friendly 接口,考验的是程序员对业务的理解与设计;后端是实现功能所依赖的基础能力,考验的是程序员对底层技术的掌握与应用;而前后端的打通,考验的是程序员的能力、经验与审美。 上一篇文章介绍的是 perf 的前端,本文介绍的是 perf 的后端,也就是硬件事件监控功能所仰仗的底层能力。
2. 综述
本文乃内核 perf 框架解构系列文章第二篇。 PMU 的底层操作是很枯燥(architectural specific)的,但却是绕不过去的一个话题,因为对 PMU 的抽象及操作,皆是 perf 框架设计的一部分。如果不弄清楚底层,代码解构起来会非常吃力。 对硬件 PMU 的解构,我们进一步细分为若干文章,本文介绍硬件 PMU 的基本概念,后续文章会介绍具体的代码编程,故本文是后续文章的前导。 本文所涉及 PMU 相关知识的细节,可参阅本号《Intel SDM 之 Performance Monitoring》,或 Intel SDM。 本文中的 “PMU” 皆指代硬件实现的 PMU,“事件”皆指代硬件事件。 本文代码基于 4.9 内核。
3. 基本概念
3.1 PMU 是什么
所谓 PMU,就是 performance monitoring unit,顾名思义,其功能就是做性能(CPU 指标)的监控。PMU 是实现在 CPU 中的硬件,通过 MSR 接口操作。 PMU 可以监控 CPU core 上的性能数据,比如 instructions、cycles 等,还可以监控 CPU 与 uncore 之间交互的性能数据(如 L3 读写 miss)。所谓 uncore,就是 CPU package 中 CPU core 之外的部分,也就是 off-core sub-system,uncore 被一个 package 中的多个 core 所共享,典型如 L3 cache、Intel QuickPath Interconnect link logic 以及 integrated memory controller 等。
3.2 PMU 与 PMC
一个 HT(hyper threading)通常包含一个 PMU,而一个 PMU 中包含多个 PMC,所谓 PMC,就是 performance monitoring counter,一个 PMC 经过编程(MSR 接口)后,可以对一个指定的事件进行监控。换句话说,同一时刻,PMU 可以同时对多个事件进行监控。若要获取性能数据,读取指定 PMC 的计数即可(实际上 PMC 有计数和中断两种工作模式,但本文只讨论简单的计数模式)。 受限于硬件设计,一个 PMU 中 PMC 数量是有限的,在笔者的机器上,一个 HT(hyper threading)中只有 7 个 PMC。
3.3 PMC 使用范式
类似《浅度剖析内核 RDT 框架》一文 3.1.1 节中探讨的 RDT 硬件使用范式,PMU 的常见用法亦有如下三种:
per-cpu 的性能监控
监控指定 CPU 的指定事件,该用法比较简单。底层实现原理是,在指定 CPU 运行期间,无论其上运行的是什么 task,始终保持其某 PMC 被编程为监控指定事件即可。前后两次读取指定事件的计数值,即可得出这两次采样之间指定 CPU 指定事件的计数。
per-task 的性能监控
监控指定 task 的指定事件,该用法需要 OS 的支持。底层实现原理是,在指定 task 被调度到 CPU 上运行时(sched_in),将 PMC 编程为指定事件,在 task 被调度出 CPU 时(sched_out),disable 此 PMC,并将 PMC 的计数值保存到事件中。前后两次读取指定事件的计数值,即可得出这两次采样之间指定 task 指定事件的计数。
per-cgroup 的性能监控
监控指定 cgroup 的指定事件,该用法需要 OS 的支持。实现原理同 per-task,不赘述。
3.4 perf 框架对 PMC 使用范式的增强
前文 4.2 节中提到,perf 框架允许用户指定一次性监控一个事件组。 所谓事件组,就是一组事件,用户通过 perf 前端接口指定组的 leader(group leader,本质上就是 perf_event_open 打开事件后返回的一个 fd),并通过前端接口向这个组内添加成员。一个组内的所有事件,必须被同时“调度”到 CPU 上,这里事件的“调度”,就是为事件分配、使能相应的 PMC;并且在读 group leader 时,会将整组事件的计数同时读出。 前一篇文章有粗略提过,但又言之未尽。perf 前端允许对指定 cpu 的指定事件(组)、指定 task 的指定事件(组)、指定 cgroup 的指定事件(组)进行监控。不同的前端接口调用者(应用),其监控需求不尽相同,而 perf 框架通过其设计与实现,兼容了不同应用的不同需求。
3.5 PMU version
本文主要基于 Intel x86 架构的 PMU 操作展开。Intel 的 PMU 架构,随着 PMU version 的演进,又有着不同的 feature 增强,与本文强相关是 version 2 相对 version 1 引入的 fixed-function PMC,本文称其为 fixed PMC。 因为本人机器的 PMU version 是 4,所以其必然是支持 fixed PMC feature 的。非 fixed PMC 本文称之为 generic PMC。
3.6 fixed 与 generic PMC
所谓 fixed PMC,是指这类 PMC 只能监控其对应的特定事件。如 图 1:
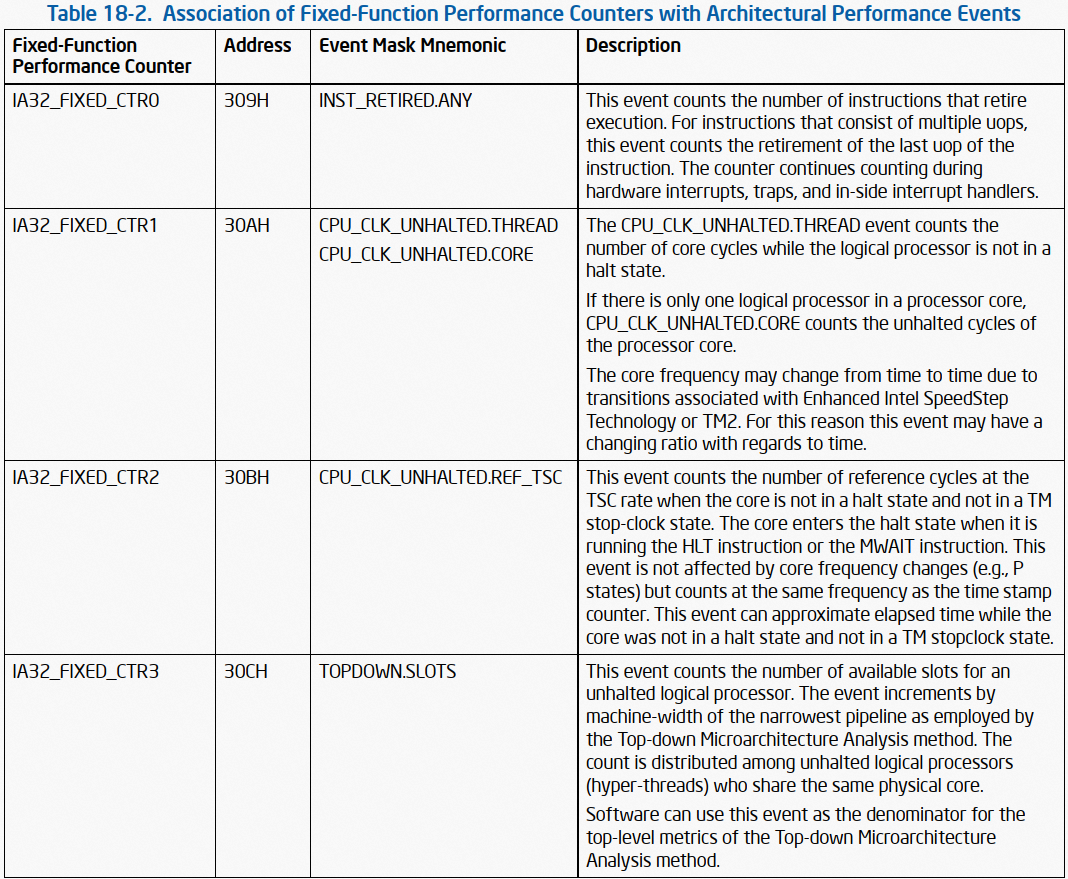
图 1 图 1 蕴含的信息有:
version 2 定义了 4 个 fixed PMC(机器上实际 fixed PMC 个数取决于具体实现,在我的机器上是 3 个,后面会介绍如何获取这些信息),分别为 IA32_FIXED_CTR[0-3]。
IA32_FIXED_CTR0,也即 0 号 fixed PMC,其地址为 309H,其可以且只可以监控 INST_RETIRED.ANY 事件。其他 PMC 类推。
具体 INST_RETIRED.ANY 事件:
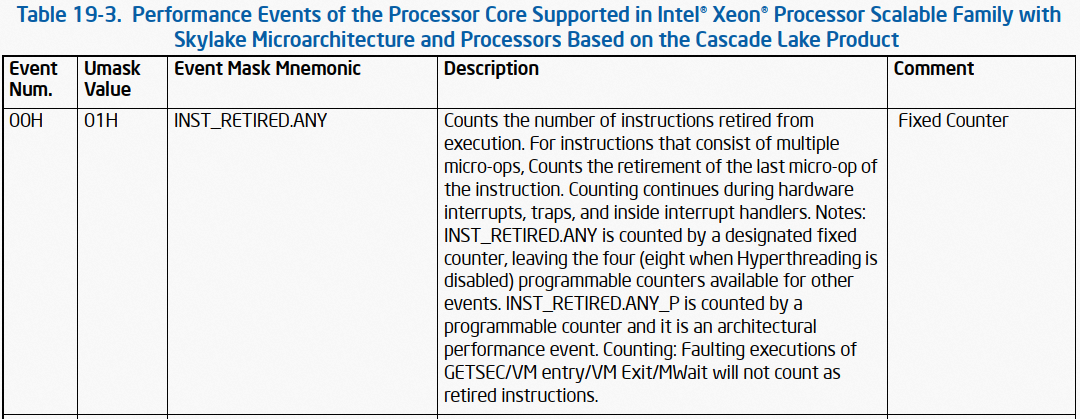
图 2 而 generic PMC,其可以通过编程(也即指定 umask、event)监控 CPU 手册中所规定的任意事件,也包括 fixed PMC 所能监控的事件。
4. 基本操作及编程
4.1 PMU 信息获取
PMU 信息包括但不限于 version、generic PMC 数量、fixed PMC 数量、PMC 寄存器的数据长度等。 通过 CPUID.0AH 获取。具体代码没有贴的意义,后续文章会有,一看就明白。
4.2 事件(PMC)的配置及读取
4.2.1 generic PMC
1. 配置
通过 IA32_PERFEVTSELx 寄存器(event select 寄存器)对 generic PMC 进行设置,x 为 PMC 的编号。 IA32_PERFEVTSELx 寄存器的基地址为 186H(内核代码:MSR_ARCH_PERFMON_EVENTSEL0),编号为 x 的 PMC,其 event select 寄存器地址为 MSR_ARCH_PERFMON_EVENTSEL0 + x。 IA32_PERFEVTSELx 格式如下:
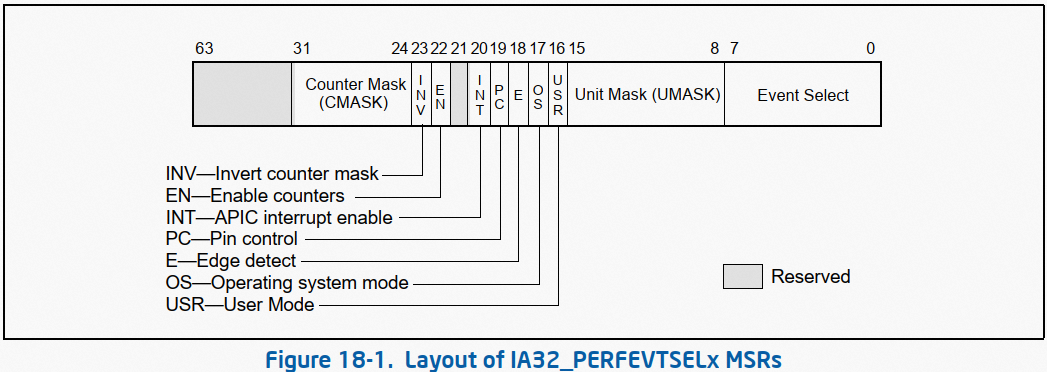
图 3
通过 umask + event select 域指定所要监控的事件。
USR、OS 位,分别表示是否使能处理器用户模式及内核模式下的监控。perf 框架下,是否使能此二者 bit,取决于前端(perf_event_open 接口)传入 perf_event_attr 的 exclude_user、exclude_kernel 参数。
EN 位,表示是否使能此 PMC。
其他位,参考 SDM Section 18.2.1.1。
generic PMC 配置及使能代码,参考内核 x86_pmu_hw_config、__x86_pmu_enable_event、x86_pmu_disable_event(不看亦无妨,后续会有代码实现的文章)。
2. 读取
根据 SDM Section 18.2.1.1,通过 generic PMC 对应的 IA32_PMCx 寄存器来获取 PMC 的计数值,x 为 generic PMC 的编号,这组寄存器基地址为 0C1H(内核代码:MSR_ARCH_PERFMON_PERFCTR0)。 内核中对 PMC 的读取不是通过 IA32_PMCx 寄存器实现,而是通过 rdpmc 指令,rdpmc 的入参是 PMC 的编号,如果是读 0 号 generic PMC,则传入 0 即可。 generic PMC 的读取代码,参考内核 x86_assign_hw_event、x86_perf_event_update。
4.2.2 fixed PMC
1. 配置
通过 IA32_FIXED_CTR_CTRL 寄存器,该寄存器地址为 38DH(内核代码:MSR_ARCH_PERFMON_FIXED_CTR_CTRL)。 不同于 generic PMC 的编程,每个 generic PMC 都有一个各自对应的 event select 寄存器。而所有 fixed PMC 皆通过 IA32_FIXED_CTR_CTRL 寄存器完成:
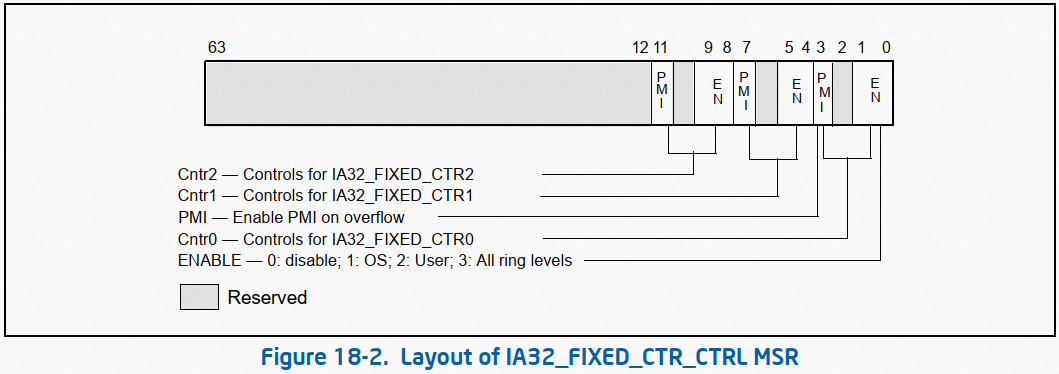
图 4 可以看到,从 bit 0 到 bit 12,每 4 个 bit 控制一个 fixed PMC,编号为 x 的 fixed PMC,其在 IA32_FIXED_CTR_CTRL 中配置 bit 的偏移为 1 << (x * 4)。 你可能会问,该寄存器为啥没有类似 generic PMC event select 寄存器的 umask 和 event select?因为它们是 fixed 的,fixed PMC 的编号与事件的对应关系见 图 1。 fixed PMC 配置及使能代码,参考内核 x86_pmu_hw_config、intel_pmu_enable_fixed、intel_pmu_disable_fixed。
2. 读取
根据 SDM Section 18.2.2,通过 fixed PMC 对应的 IA32_FIXED_CTRx 寄存器来获取 PMC 的计数值,x 为 PMC 的编号。如 图 1,这组寄存器基地址为 309H(内核代码:MSR_ARCH_PERFMON_FIXED_CTR0)。 内核中对 PMC 的读取不是通过 IA32_FIXED_CTRx 寄存器实现,而是通过 rdpmc 指令,rdpmc 的入参是 (x - INTEL_PMC_IDX_FIXED) | 1<<30,其中 x 为 fixed PMC 的编号,INTEL_PMC_IDX_FIXED 为 32。 fixed PMC 的读取,同 generic PMC,参考内核 x86_assign_hw_event、x86_perf_event_update。
4.3 PMU 的配置及使能
所谓使能/禁能 PMU,其本质是一次性使能/禁能 PMU 的所有 PMC。一个自然而然的想法是对上述提到的所有寄存器分别进行相应使能/禁能配置。 但 Intel 提供了更方便的总控寄存器 IA32_PERF_GLOBAL_CTRL(内核代码:MSR_CORE_PERF_GLOBAL_CTRL):

图 5 参考内核 __intel_pmu_enable_all、__intel_pmu_disable_all。 值得注意的是:IA32_PERF_GLOBAL_CTRL 寄存器中,为 fixed PMC 预留的偏移是从 32 开始的,换句话说,至少从目前的 Intel CPU 设计来说,其为 generic PMC 预留的数量为 32。这也是 4.2.2 中提到的,内核 INTEL_PMC_IDX_FIXED 宏为 32 的原因。
5. 伏笔
上一章就 PMU 的最基本操作进行了阐述,实际上 perf 框架中对 PMU 的管理、操作远超这些范畴。 本章意在抛出问题,为后续文章埋个伏笔:
PMC 的分时复用问题:如你所知,PMC 的数量有限,如果要监控的事件数超出 PMC 数(具体来说,对某个 CPU 有多个监控事件组,所有事件组的事件数总和完全有可能超过 PMC 总数),必然要求 perf 框架有 PMC 分时复用的机制。
事件的 PMC 分配问题:当用户指定要监控某个事件时,到底应该为其分配哪个 PMC?如果是 fixed 事件,是否要倾向于优先为其分配 fixed PMC?
事件的 PMC 寄存器配置生成问题:拿 generic PMC 来说,其 event select 寄存器的配置,是如何从前端接口的参数配置生成出来的(以在合适的时机写入硬件寄存器)?尤其是 hardware、hw_cache 这类采用通用 ID(前文 3.2 节)的事件,是如何转成底层的 umask 和 event select 的?
6. 总结
本文探讨了 PMU 的基本概念,并讨论了 PMU 的基本操作及编程,文章的最后抛出了 perf 框架实现中所面临的若干实际问题。 编辑:黄飞
-
Cortex-A55 PMU使用案例应用说明2023-08-11 956
-
ARM Neoverse N2 PMU指南2023-08-09 765
-
内核perf框架解构系列:PMU硬件架构相关的概念及编程2023-03-28 3095
-
一文浅析AMU和PMU的区别2023-02-15 3384
-
那么AMU和PMU有什么不同呢?2023-02-03 2489
-
AI引擎内核编程设计进程2022-10-11 2179
-
UG-752:操作ADP5080高效6通道PMU评估板2021-05-13 736
-
脉冲发生器PMU可以做什么?2021-04-09 1819
-
如何使用WEBENCH PMU优化电源设计?2018-08-20 4589
-
PMU基本介绍2017-01-22 2025
-
MAX9979引脚电子IC中的PMU模式操作2010-12-25 1461
-
Linux0.01内核分析与操作系统设计2010-08-13 880
-
什么是操作系统内核2009-06-17 10995
-
MAX9979管脚电子IC中PMU模式操作2009-03-31 1961
全部0条评论

快来发表一下你的评论吧 !
