

ChatGPT背后的原理简析
描述
ChatGPT 是 OpenAI 发布的最新语言模型,比其前身 GPT-3 有显著提升。与许多大型语言模型类似,ChatGPT 能以不同样式、不同目的生成文本,并且在准确度、叙述细节和上下文连贯性上具有更优的表现。它代表了 OpenAI 最新一代的大型语言模型,并且在设计上非常注重交互性。
从官网介绍可以看到,ChatGPT与InstructGPT是同源的模型。
chatGPT是一种基于转移学 习的大型语言模型,它使用GPT-2 (Generative PretrainedTransformer2)模型的技术,并进行了进一步的训练和优化。
GPT-2模型是一种基于注意力机制的神经网络模型,它能够处理序列建横问题,如自然语言处理中的语言建模和机器翻译。它使用了一种叫做transformer的架构, 它能够通过自注意力机制来学习语言的结构和语义。GPT-2模型预先训练了一个大型语料库上,以便在实际应用中能够更好地表现。
chatGPT是在GPT-2模型的基础上进一步训练和优化而得到的。 它使用了更多的语料库,并且进行了专门的训练来提高在对话系统中的表现。这使得chatGPT能够在对话中白然地回应用户的输入,并且能够生成流畅、连贯、通顺的文本。
那么接下来我们来看下什么是InstructGPT。从字面上来看,顾名思义,它就是指令式的GPT,“which is trained to follow an instruction in a prompt and provide a detailed response”。接下来我们来看下InstructGPT论文中的主要原理:
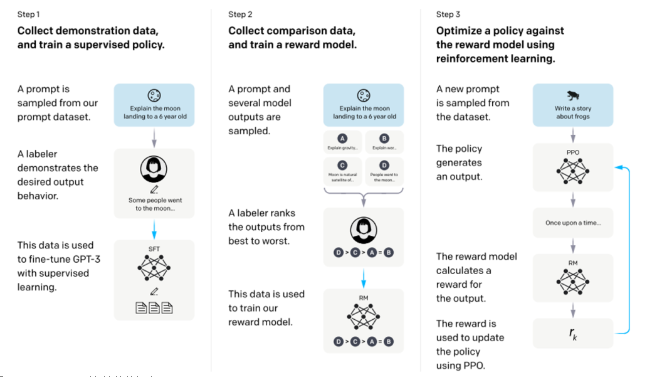
InstructGPT整体训练流程
从该图可以看出,InstructGPT是基于GPT-3模型训练出来的,具体步骤如下:
步骤1.)从GPT-3的输入语句数据集中采样部分输入,基于这些输入,采用人工标注完成希望得到输出结果与行为,然后利用这些标注数据进行GPT-3有监督的训练。该模型即作为指令式GPT的冷启动模型。
步骤2.)在采样的输入语句中,进行前向推理获得多个模型输出结果,通过人工标注进行这些输出结果的排序打标。最终这些标注数据用来训练reward反馈模型。
步骤3.)采样新的输入语句,policy策略网络生成输出结果,然后通过reward反馈模型计算反馈,该反馈回过头来作用于policy策略网络。以此反复,这里就是标准的reinforcement learning强化学习的训练框架了。
所以总结起来ChatGPT(对话GPT)其实就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通过人工标注方式训练出强化学习的冷启动模型与reward反馈模型,最后通过强化学习的方式学习出对话友好型的ChatGPT模型。
InstructGPT的训练实际上是分为三个阶段的,第一阶段就是我们上文所述,利用人工标注的数据微调GPT3;第二阶段,需要训练一个评价模型即Reward Model,该模型需学习人类对于模型回复的评价方式,对于给定的上文与生成回复给出分数;第三阶段,利用训练好的Reward Model作为反馈信号,去指导GPT进一步进行微调,将目标设定为Reward分数最大化,从而使模型产生更加符合人类偏好的回复。
文章综合CSDN、赛尔实验室、 IT架构师联盟
-
LLM风口背后,ChatGPT的成本问题2023-02-15 5934
-
ChatGPT成功背后的技术原因2023-02-21 1482
-
chatgpt是什么意思 ChatGPT背后的技术原理2023-07-18 942
全部0条评论

快来发表一下你的评论吧 !
