

JVM入门之垃圾回收算法
电子说
描述
现有的垃圾回收算法
分类
根据如何判定对象是垃圾,垃圾回收算法分为两类:1、 「引用计数式垃圾收集」 (判定垃圾是通过引用计数器)别名:直接垃圾收集 2、 「追踪式垃圾收集」 (判定垃圾是通过GC Roots)别名:间接垃圾收集
主流虚拟机采用的是第二种追踪式垃圾收集,所以本文讲解第二种垃圾收集的算法
垃圾收集器的设计原则
根据两个分代假说:
1.绝大部分对象是熬不过第一次垃圾回收的 2.熬过多次垃圾回收的对象是难以被标记为垃圾的。
垃圾收集器将堆中的内存划分为了不同的区域,根据对象分代年龄(熬过多少次垃圾回收)来分配到不同的区域中:
比如对象分代年龄小的,第一种对象就应该 「标记存活对象」 即可,而不需要标记那些垃圾对象,因为这部分对象大部分都是很快用完就不用的垃圾对象。
而第二种对象分代年龄大的,则应该标记的是垃圾对象,因为根据第二个假说这部分对象中垃圾对象的占比很少,所以垃圾回收的频率也可以降低。
「将堆划分为不同的区域后,垃圾回收器可以只回收其中一部分区域,针对每一部分区域也可以采用不同的算法来进行回收垃圾。」
一般来说堆中至少会被划分为“新生代”和“老年代”两个区域。新生代存储第一种假说类型的对象,老年代存放第二种假说类型的对象。
「注意」 :这种设计看起来是完美的,但是如果 「老年代中的对象引用了新生代中的对象」 这个时候年轻代发生垃圾回收时,除了需要遍历GC Roots外,还需要 「遍历整个老年代」 才会确保年轻代中的对象真正没有对象引用。显然这种遍历整个老年代效率肯定会很低,所以采用了一种解决方案:读者有兴趣可以看看: 在这篇博客的末尾
标记-清除算法
最早出现的垃圾回收算法,之后出现的算法都是根据其缺点来进行演进的。
两个阶段:1. 「标记」 2.「清除」「标记需要回收的对象完成后进行统一回收所有被标记的对象, 也可以标记存活的对象统一回收没有被标记的对象。」
「一,标记」 :如何判定对象是否是垃圾的过程在上一篇 博客 中已经讲解过,接着 「标记」 这些垃圾对象。
「二,清除」 :进行统一回收掉标记的对象。
缺点
1.当堆中的对象大部分是垃圾时, 「标记和清除的效率会变低」 ,而且会随着内存中垃圾对象的增长,导致效率越来越低。
- 「内存碎片化」 :因为内存分配不是连续的,所以当清除后,内存中会存在大量内存碎片。当遇到大对象分配内存找不到足够的连续的内存来存放时会提前触发GC。

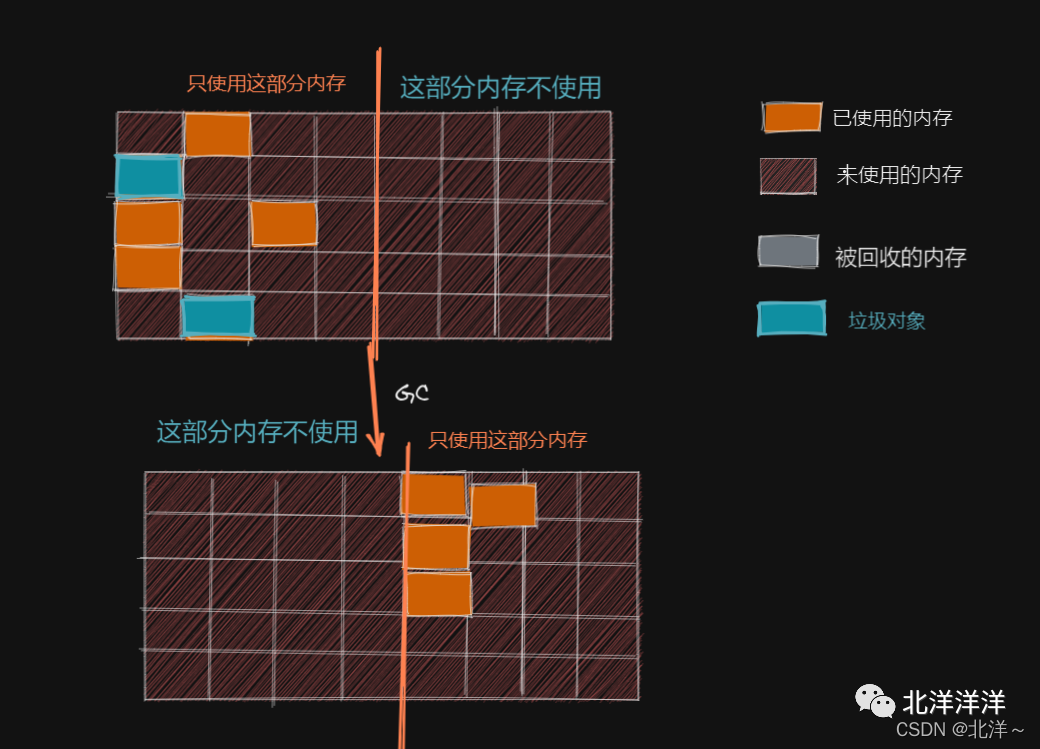
标记-复制算法
采用的是“半区复制”的算法来实现的,即每次只使用其中的一部分内存,当这部分内存用完后将存活着的对象复制到另外一块内存上,接着清空刚才使用的那部分内存,当另一部分内存满了的时候再用上一次清空后的那块内存往复。
解决了标记-清除的内存碎片化问题,因为当发生GC时会进行全部清空,只将存活对象复制到另外一块内存中。
在这里插入图片描述
“Apple回收策略”
Andrew Appel针对刚刚分代假说中的第一条,提出了“Appel式回收策略”。
一般情况下百分之九十八的对象在经历第一次gc时就会被清除。因此做出优化将年轻代分为了 「一块eden空间和两块Survival空间」 。enen和Survival内存占比为 「8:1」 ,即每次使用百分之九十的内存, 「只有百分之十的内存会被浪费」 ,因为对象大部分都会死去所以没有必要分配一半的空间来存放存活对象。
但是如果使用百分之十的内存来存放存活对象,当存活对象在Survival空间存放不下时,这个时候就需要用老年代担保,因此当存不下时会存放到老年代中。
缺点
1.当内存中的对象存活率较高时,复制大量存活对象会使得效率变低。2.如果不想造成严重的内存浪费,就需要有额外的空间进行分配。
标记-整理算法
上面所说的标记-复制算法针对与新生代中进行的回收算法,并不适用与老年代,原因:老年代中存活率较高,存放不下时需要额外的内存空间担保。
因此出现了标记-整理算法, 和标记-复制算法相同的是: 「标记的都是存活对象」 ;和标记-复制算法不同的是: 「复制算法将存活对象复制到另外一块内存上然后清除之前使用的内存,而整理算法是移动存活的对象到一端,然后清除边界以外的内存」 。
缺点
「移动存活对象」 :对于老年代中GC之后大部分都为存活对象,将这些对象都进行移动并且更新引用这些对象的地方是一个比较耗时的操作。而且更新引用需要暂停用户线程来保证用户线程访问对象不会出错,简称STW,"Stop the Word"。
其实不止整理算法里面移动对象更新引用需要STW,清除算法和复制算法中的标记清除都需要STW,只不过时间短

在这里插入图片描述
总结
采用标记-整理算法意味着GC的时候要移动对象更新对象的引用,也就是说 「内存回收的时候会更复杂」 。
采用标记-清除算法意味着 「内存碎片化」 。
采用标记-复制算法意味着 「内存可用度不高」 。
“吞吐量”:赋值器(使用垃圾回收器的线程也就是用户线程)与垃圾回收器的效率总和。
因为 「内存分配和访问(内存碎片化导致过多的分配和访问)比垃圾回收器回收的频率(回收时需要STW,而且比较耗时)要高」 ,因此整理这种方式其实吞吐量要比清除要好。
对于关注吞吐量的收集器Parallel Scabenge基于标记-整理算法, 对于关注STW的收集器CMS来说采用的是标记-清除算法。其实CMS是一种将两种算法混合起来的收集器,大部分时间采用清除算法,只有当分配内存不足(碎片化特别严重)时用整理算法进行一次收集。
-
从原理聊JVM(一):染色标记和垃圾回收算法2024-08-20 1063
-
jvm参数的设置和jvm调优2023-12-05 3103
-
垃圾收集器的JVM参数配置2023-10-09 1428
-
详细解析JVM中的垃圾回收机制2023-06-06 3026
-
JVM入门之关于GC的扩展知识12023-02-10 1139
-
详解JVM的垃圾回收算法和垃圾回收器2022-03-29 2269
-
带颜色的JVM垃圾回收三色标记法2021-10-20 2588
-
如何解决JVM中一个极小概率发生的bug2021-08-23 4382
-
基于页合并更新的NAND Flash垃圾回收算法研究2021-07-30 924
-
垃圾回收算法——标记清除算法2020-04-29 2181
-
Jvm垃圾回收机制及性能调优实战2018-04-03 904
-
基于逻辑区间热度的垃圾回收算法2017-12-05 820
-
固态硬盘垃圾回收方法2017-12-03 1930
全部0条评论

快来发表一下你的评论吧 !
