

性别偏见探索和缓解的中文数据集-CORGI-PM
描述
介绍
大规模语言模型(LMs)已经成为了现在自然语言处理的关键技术,但由于训练语料中常带有主观的性别偏见、歧视等,在大模型的使用过程中,它们时常会被放大,因此探测和缓解数据中的性别偏见变得越来越重要。
部分研究通过性别交换等自动标注方法,缓解性别偏见的语料库;也有一些人工标注的性别偏见语料库,但主要集中在单词层面或语法层面的偏见,或只关注与性别歧视相关的话题,并主要以英文为主。因此,该论文提出了第一个用于性别偏见探测和缓解的句子级中文语料库,采用一种自动方法(如图1所示,对含有性别偏见得分高的词的样本进行召回,然后根据其句子级性别偏见概率对样本进行重新排序和过滤),从现有的大规模中文语料库中构建可能存在性别偏见的句子集,再通过精心设计的标注方案,对候选数据集进行进一步的标注,构建可以用于性别偏见检测、分类和缓解三种任务的数据集。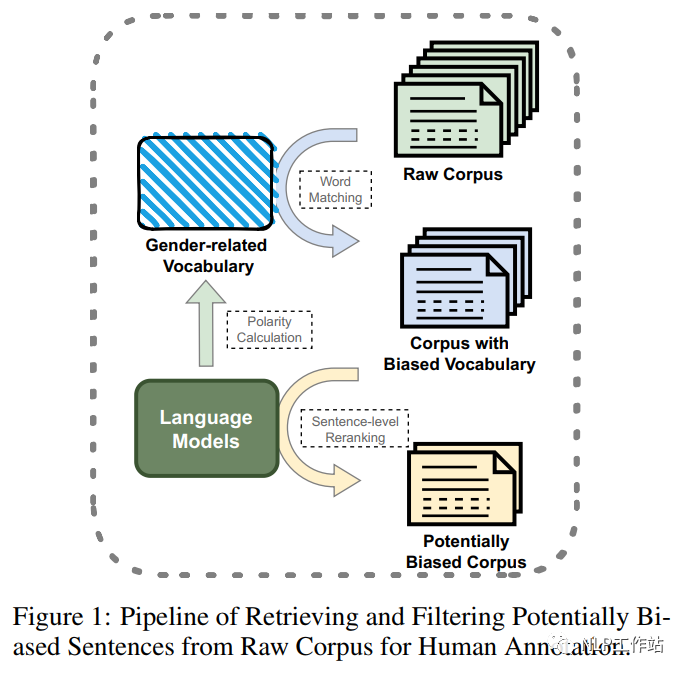
数据构建
样本过滤
如图1所示,该研究通过单词级到句子级的两阶段过滤,从原始语料库中召回、排序和过滤待标注候选数据。对于词级别过滤,通过计算目标词与种子方向之间得分,构建一个高偏见分数的词表,并从原始语料库中匹配包含这些词语的句子,为初步候选集合。其中得分计算如下: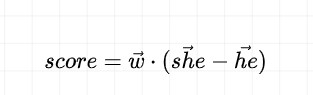
正值表示该词语更适合女性,负值表示该词语更适合男性,性别偏见得分绝对值越高,说明该词语的偏见程度越高。过滤得到的词汇绘制的词云如图5所示,
对于句子级别过滤,计算句子的性别偏见得分,并根据获得性别偏见关键词进行分组,然后根据特定的全局阈值性别偏见得分和组内阈值排名选择待标注的最终句子集合。
标注规则
标注方案为标注人员对一个句子进行判断,判断是否存在性别偏见;如果存在,则需要给出偏见具体类型,并为了缓解性别偏见,还需要对有偏见的句子进行纠正,给出无偏见句子。为保证标注质量,6名标注人员均具有学士学位,并且男女比例相同。
「偏见类别」共包含3种:
AC:性别刻板的活动和职业选择;
DI:性别刻板的描述和概况;
ANB:表达性别刻板的态度、规范和信仰。
缓解性别偏见主要是在保留原始语义信息的同时,减轻所选句子的性别偏见,并要求标注者进行使句子的表达式多样化,主要修改规则如下:
用中性代词取代性别代词;
用语义定义相近的中性描述替换性别特定的形容词;
对不能直接减轻的句子,添加额外的解释进行中和。
标注过程分为两个阶段:第一阶段,各标注者进行标注,并要求不要输入不确定样本;第二阶段,标注者之间进行交叉标注。
语料分析
CORGI-PM数据统计如表1所示,共包含32.9k数据,并考虑数据分布,划分了训练集、验证集及测试集。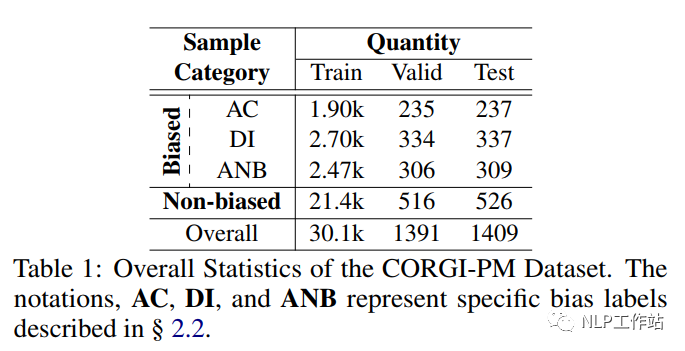
如表2所示,发现偏见句子相较于无偏见句子来说,句子更长,包含词汇更少;但由于去偏句子需要在保持原意图语义不变、句子连贯、减轻偏见,因此去偏样本与原样本相比表达更长、更多样化。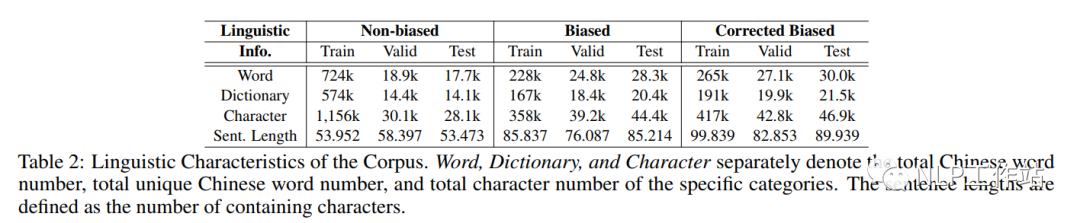
偏见数据格式样例:
{
'train':{
# 原始句子
'ori_sentence': [
sent_0,
sent_1,
...,
],
# 偏见类型
'bias_labels': [
[0 1 0],
[0 1 0],
[0 1 0],
...,
],
# 人工去偏句子
'edit_sentence': [
edited_sent_0,
edited_sent_1,
...,
],
},
'valid':{
... # 与训练集一致
},
'test':{
... # 与训练集一致
}
}
无偏见数据格式样例:
{
'train':{
# 原始句子
'text': [
sent_0,
sent_1,
...,
],
},
'valid':{
... # 与训练集一致
},
'test':{
... # 与训练集一致
}
}
实验结果
针对性别偏见检测及分类任务,以Precision、Recall和F1作为评价指标,采用BERT、Electra和XLNet模型进行微调进行实验对比,并采用GPT-3 Curie模型进行zero-shot实验,结果如表3所示。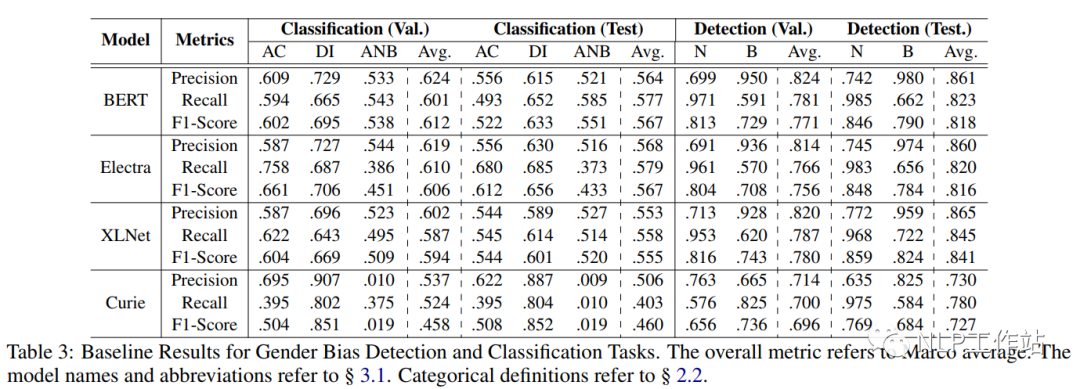
针对性别缓解任务,采用GPT-3 Ada(350M)、Babbage(1.3B)和Curie(6.7B)进行微调, 并采用Davinci(175B)进行zero-shot实验,结果如表4所示。
总结
中文首个性别偏见探索和缓解数据集,开源不易,且用且珍惜。
审核编辑:刘清
-
Spectre和Meltdown的利用漏洞的软件影响和缓解措施2023-08-25 557
-
芯驰科技对打破创投圈性别偏见的看法2022-03-11 2931
-
Google遵循AI原则减少机器翻译的性别偏见2021-08-24 3932
-
AI可能带有性别偏见?Salesforce提出了减轻AI性别偏见的方法2020-07-05 3184
-
Cloud AI提供免费消除性别偏见 将不再标识性别2020-03-20 1066
-
创新工具和开源软件如何帮助测量和缓解RF问题2019-07-23 3138
-
IBM打造百万人脸数据 意图减少AI偏见与歧视问题2019-02-13 671
-
请问tm4c123gh6pm有中文数据手册吗?2018-08-14 3010
-
本应公平公正的 AI,却从数据中学会了人类的偏见2018-06-02 3607
-
人工智能遭遇的偏见 算法偏见带来的问题2018-02-06 13636
-
基于情绪特征用户性别识别2017-11-25 614
-
TM4C1233H6PM数据手册中文版2017-10-31 2642
-
那个涉嫌性别歧视被开除的谷歌工程师,到底吐槽了些什么?2017-08-15 3996
全部0条评论

快来发表一下你的评论吧 !
