

【AI简报第20230210期】 ChatGPT爆火背后、为AIoT和边缘侧AI喂算力的RISC-V
描述
1. ChatGPT爆火背后:AI芯片迎接算力新挑战
原文:
https://www.163.com/dy/article/HT7BHN3C05199NPP.html
ChatGPT的出圈走红为AIGC打开全新市场增量,催生了更高的算力需求。
作为人工智能三大核心要素之一,算力也被誉为人工智能“发动机”。华泰证券研报显示,根据OpenAI测算,自2012年以来,全球头部AI模型训练算力需求3-4个月翻一番,每年头部训练模型所需算力增长幅度高达10倍。AI深度学习正在逼近现有芯片的算力极限,也对芯片设计厂商提出了更高要求。
由此可见,AIGC未来进一步的应用和普及离不开算力的强劲支撑。受下游算力需求高涨消息影响,2月9日,半导体及元件板块再度转头向上,整体上涨4.58%。截至当日收盘,半导体及元件板块近一周涨幅2.53%。
板块走势的分化也体现出市场对AI芯片的态度。近日,在接受21世纪经济报道记者采访时,多家AI芯片厂商表示,AIGC等相关业务需要结合下游最终端应用的实际情况考虑。
“大模型动辄千万美元起步的基础设施建设投入和海量的训练数据需求,也注定了它极高的研发门槛。”百度昆仑芯方面向21世纪经济报道记者指出,“(大模型)对计算的要求主要体现在三个方面,一是算力,二是互联,三是通用性,对于昆仑芯来说,场景需求一直是架构研发、产品迭代的最重要的‘指南针’。”
科技新赛道
AIGC(Artificial Intelligence Generated Content)指的是人工智能系统生成的内容,是继 UGC、PGC 之后的新型内容创作方式,包括文字、图像、音频或视频等。AIGC可以通过自然语言处理、机器学习和计算机视觉等技术帮助AI系统识别理解输入内容,并生成“创作”全新的内容。
目前,AIGC已在多应用领域实现落地,2022年更是被AI业内人士称作AIGC“元年”。2022年8月,文本生成图像模型Stable Diffusion火爆出圈,催生了AI作画的热潮;12月,OpenAI推出的人工智能聊天机器人模型 ChatGPT ,可以使用大量训练数据模拟人类语言行为,通过语义分析生成文本从而与用户进行自然交互,在全球范围内掀起AIGC的热潮。
随着人工智能应用向纵深发展,对AI模型训练所需要的算力支持提出了更高要求。
作为算力的硬件基石,AI芯片是针对人工智能算法做了特殊加速设计的芯片。信达证券发布研究报告称,在技术架构层面,AI芯片可以分为 GPU(图形处理器)、FPGA(现场可编程门阵列)、ASIC(专用集成电路)和类脑芯片,同时CPU也可用以执行通用AI计算。
在应用层面,AI芯片又可以划分为云端、边缘端和终端三个类型,不同场景对芯片的算力和功耗的要求不同,单一芯片难以满足实际应用的需求。
在云端层面,由于大多数AI训练和推理工作负载都在此进行,需要运算巨量、复杂的数据信息,因此对于 AI 芯片的性能和算力要求最高;边缘端是指处理云端和终端之间的传输网络,承担着汇集、分析处理和通信传输数据的功能,一定程度上分担云端的压力,降低成本、提升效率。
终端AI芯片由于直面下游产品,大多以实际需求为导向,主要应用于消费电子、智能驾驶、智能家居和智慧安防等领域,终端产品类型和出货量的增加,也相应刺激了对芯片的需求。
信达证券研究团队总结称,AIGC 推动 AI 产业化由软件向硬件切换,半导体+AI 生态逐渐清晰,AI芯片产品将实现大规模落地。据前瞻产业研究院的数据,我国人工智能芯片的市场规模增速惊人,到2024 年,将达到785 亿元。
2. 不出所料,自动驾驶向ChatGPT下手了!
原文:
https://mp.weixin.qq.com/s/a5A2mfG8WQElIuo5vT2s7w
ChatGPT 的技术思路与自动驾驶能碰撞出什么样的火花呢?
去年底,ChatGPT 横空出世。真实自然的人机对话、比拟专家的回答以及一本正经的胡说八道,使它迅速走红,风靡全世界。
不像之前那些换脸、捏脸、诗歌绘画生成等红极一时又很快热度退散的 AIGC 应用,ChatGPT 不仅保持了热度,而且还有全面爆发的趋势。现如今,谷歌、百度的 AI 聊天机器人已经在路上。

比尔盖茨如此盛赞:「ChatGPT 的意义不亚于 PC 和互联网诞生。
为什么呢?
首先,人机对话实在是刚需。人工智能技术鼻祖的图灵所设计的「图灵测试」,就是试图通过人机对话的方式来检验人工智能是否已经骗过人类。能从人机问题中就能获得准确答案,这可比搜索引擎给到一大堆推荐网页和答案更贴心了。要知道懒惰乃人类进步的原动力。
其次,ChatGPT 实在是太能打了。不仅在日常语言当中,ChatGPT 能够像人类一样进行聊天对话,还能生成各种新闻、邮件、论文,甚至进行计算和编写代码,这简直就像小朋友抓到一只「哆啦 A 梦」—— 有求必应了。
除了看看热闹,我们也可以弱弱地问一句:ChatGPT 为啥这么能打呢?希望大家可以在原文中找到答案。
3. 为AIoT和边缘侧AI喂算力的RISC-V
原文:
https://mp.weixin.qq.com/s/qQWahKqVkkS7bToN7-eHQQ
在去年底由晶心科技举办的RISC-V CON上,英特尔RISC-V投资部门的总经理Vijay Krishnan阐述了自己的Pathfinder for RISC-V计划。通过搭建这个平台,英特尔将助力解决RISC-V软件开发生态上的挑战,并表示首先侧重于AIoT和边缘端市场。
但我们也都知道这一计划持续不到半年就被砍了,可即便如此,RISC-V在AIoT领域的探索也早早就已经处于进行时了。针对AIoT和边缘侧AI开发的RISC-V芯片、开发板也都纷纷上市,为RISC-V抢占这一市场的份额添砖加瓦。
GreenWave-GAP9
法国公司GreenWave作为一家面向电池供电IoT设备市场的厂商,主要产品就是超低功耗的RISC-V应用处理器,GAP系列。他们率先推出的GAP8就是一个用于大规模智能边缘设备部署的IoT应用处理器,但由于算力并不高,所以只能负责一些占用管理、人脸识别、关键词识别之类的简单任务。
而他们的第二代产品GAP9则是一款为TWS降噪耳机设计的RISC-V芯片,做到超低延迟的同时,使用神经网络来完成声学场景检测、降噪、3D环绕和ASRC等功能。其实用于高端TWS耳机主动降噪的低延迟RISC-V早已面世并大规模出货了,即中科蓝讯的蓝讯迅龙系列。而GreenWave的GAP9为了进一步增加算力,则在其架构中塞入了1个RISC-V控制器核心,9个RISC-V计算核心和AI加速器。

嘉楠-勘智K510
嘉楠的勘智K210作为2019年发布的一款RISC-V芯片,采用了双核64位CPU的算力,在300mW的功耗下即实现了1TOPS的算力。而且在神经网络加速器KPU的助力下,该芯片可以直接在本地处理人脸识别、图像识别等机器视觉任务,可广泛应用于门禁、智能水电表等应用中,陆吾智能甚至将其用于XGOmini这样的四足机器狗中。
而嘉楠科技于2021年发布的勘智K510,则是一款定位中高端边缘AI推理的芯片,将其神经网络加速器KPU升级到了2.0版本,不仅降低了芯片功耗,还将算力提升了3倍,单芯片算力高达2.5TFLOPS,支持INT8和BF16两种精度,也支持TensorFlow、PyTorch等主流框架。

可以说,K510的出现,进一步增加了在AIoT和边缘侧AI上的算力和精度。而且由于K510还搭载了3D ISP,可以进行图像降噪、畸变矫正等处理任务,对于AIoT和边缘侧AI常见的低照度环境和广角镜头来说起到了决定性的作用。像上面提到的机器狗应用,也可以因为这庞大的算力来完成更复杂的手势识别、人体姿态识别等工作。
小结
从RISC-V在AIoT目前的布局情况来看,产品主要面向TWS、音频/图像检测与识别、智能抄表和智能家居等对AI算量不高的应用,但它们仍在继续推进更高的算力和更多的深度学习框架支持。相信在优秀RISC-V IP核、低功耗、可编程和向量扩展等优势的吸引下,未来我们能在该领域看到更多的RISC-V产品。
固然RISC-V在AIoT这个市场已经取得了不小的进展,也有了与主流的Arm生态一战之力,但后者的智能生态依然是全方位的。在超低功耗的IoT设备和传感器应用上,RISC-V至少在性能上已经不输于人了。但到了智能设备、智能网关、本地服务器乃至云端,需要的AI算力是成倍提升的,虽然不少RISC-V IP厂商都已经开始主推AI核心了,但我们仍然需要更多落地的RISC-V AI处理器。
4. 强化学习中的Transformer发展到哪一步了?清华、北大等联合发布TransformRL综述
原文:
https://mp.weixin.qq.com/s/v7QJIAy7xctByJZ9lz9viQ
论文地址:
https://arxiv.org/pdf/2301.03044.pdf
强化学习(RL)为顺序决策提供了一种数学形式,深度强化学习(DRL)近年来也取得巨大进展。然而,样本效率问题阻碍了在现实世界中广泛应用深度强化学习方法。为了解决这个问题,一种有效的机制是在 DRL 框架中引入归纳偏置。
在深度强化学习中,函数逼近器是非常重要的。然而,与监督学习(SL)中的架构设计相比,DRL 中的架构设计问题仍然很少被研究。大多数关于 RL 架构的现有工作都是由监督学习 / 半监督学习社区推动的。例如,在 DRL 中处理基于高维图像的输入,常见的做法是引入卷积神经网络(CNN)[LeCun et al., 1998; Mnih et al., 2015];处理部分可观测性(partial observability)图像的常见做法则是引入递归神经网络(RNN) [Hochreiter and Schmidhuber, 1997; Hausknecht and Stone, 2015]。
近年来,Transformer 架构 [Vaswani et al., 2017] 展现出优于 CNN 和 RNN 的性能,成为越来越多 SL 任务中的学习范式 [Devlin et al., 2018; Dosovitskiy et al., 2020; Dong et al., 2018]。Transformer 架构支持对长程(long-range)依赖关系进行建模,并具有优异的可扩展性 [Khan et al., 2022]。受 SL 成功的启发,人们对将 Transformer 应用于强化学习产生了浓厚的兴趣,希望将 Transformer 的优势应用于 RL 领域。
Transformer 在 RL 中的使用可以追溯到 Zambaldi 等人 2018 年的一项研究,其中自注意力(self-attention)机制被用于结构化状态表征的关系推理。随后,许多研究人员寻求将自注意力应用于表征学习,以提取实体之间的关系,从而更好地进行策略学习 [Vinyals et al., 2019; Baker et al., 2019]。
除了利用 Transformer 进行表征学习,之前的工作还使用 Transformer 捕获多时序依赖,以处理部分可观测性问题 [Parisotto et al., 2020; Parisotto and Salakhutdinov, 2021]。离线 RL [Levine et al., 2020] 因其使用离线大规模数据集的能力而受到关注。受离线 RL 的启发,最近的研究表明,Transformer 结构可以直接作为顺序决策的模型 [Chen et al., 2021; Janner et al., 2021] ,并推广到多个任务和领域 [Lee et al., 2022; Carroll et al., 2022]。
实际上,在强化学习中使用 Transformer 做函数逼近器面临一些特殊的挑战,包括:
强化学习智能体(agent)的训练数据通常是当前策略的函数,这在学习 Transformer 的时候会导致不平稳性(non-stationarity);
现有的 RL 算法通常对训练过程中的设计选择高度敏感,包括模型架构和模型容量 [Henderson et al., 2018];
基于 Transformer 的架构经常受制于高性能计算和内存成本,这使得 RL 学习过程中的训练和推理都很昂贵。
例如,在用于视频游戏的 AI 中,样本生成的效率(在很大程度上影响训练性能)取决于 RL 策略网络和估值网络(value network)的计算成本 [Ye et al., 2020a; Berner et al., 2019]。
为了更好地推动强化学习领域发展,来自清华大学、北京大学、智源人工智能研究院和腾讯公司的研究者联合发表了一篇关于强化学习中 Transformer(即 TransformRL)的综述论文,归纳总结了当前的已有方法和面临的挑战,并讨论了未来的发展方向,作者认为 TransformRL 将在激发强化学习潜力方面发挥重要作用。

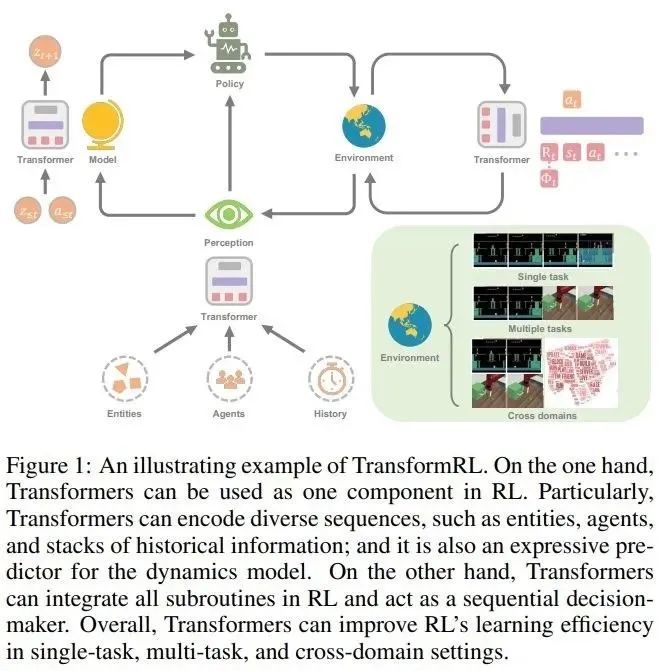
论文的总体结构如下:
第 2 章介绍了 RL 和 Transformer 的背景知识,然后简要介绍了这两者是如何结合在一起的;
第 3 章描述了 RL 中网络架构的演变,以及长期以来 RL 中阻碍广泛探索 Transformer 架构的挑战;
第 4 章论文作者对 RL 中的 Transformer 进行了分类,并讨论了目前具有代表性的方法;
第 5 章总结并指出了未来潜在的研究方向。
5. 首个快速知识蒸馏的视觉框架:ResNet50 80.1%精度,训练加速30%
原文:
https://mp.weixin.qq.com/s/HWVpVOsYTOH98aU0tC_LzA
论文和项目网址:
http://zhiqiangshen.com/projects/FKD/index.html
代码:
https://github.com/szq0214/FKD

知识蒸馏(KD)自从 2015 年由 Geoffrey Hinton 等人提出之后,在模型压缩,视觉分类检测等领域产生了巨大影响,后续产生了无数相关变种和扩展版本,但是大体上可以分为以下几类:vanilla KD,online KD,teacher-free KD 等。最近不少研究表明,一个最简单、朴素的知识蒸馏策略就可以获得巨大的性能提升,精度甚至高于很多复杂的 KD 算法。但是 vanilla KD 有一个不可避免的缺点:每次 iteration 都需要把训练样本输入 teacher 前向传播产生软标签 (soft label),这样就导致很大一部分计算开销花费在了遍历 teacher 模型上面,然而 teacher 的规模通常会比 student 大很多,同时 teacher 的权重在训练过程中都是固定的,这样就导致整个知识蒸馏框架学习效率很低。
针对这个问题,本文首先分析了为何没法直接为每张输入图片产生单个软标签向量然后在不同 iterations 训练过程中复用这个标签,其根本原因在于视觉领域模型训练过程数据增强的使用,尤其是 random-resize-cropping 这个图像增强策略,导致不同 iteration 产生的输入样本即使来源于同一张图片也可能来自不同区域的采样,导致该样本跟单个软标签向量在不同 iterations 没法很好的匹配。本文基于此,提出了一个快速知识蒸馏的设计,通过特定的编码方式来处理需要的参数,继而进一步存储复用软标签(soft label),与此同时,使用分配区域坐标的策略来训练目标网络。通过这种策略,整个训练过程可以做到显式的 teacher-free,该方法的特点是既快(16%/30% 以上训练加速,对于集群上数据读取缓慢的缺点尤其友好),又好(使用 ResNet-50 在 ImageNet-1K 上不使用额外数据增强可以达到 80.1% 的精度)。
首先我们来回顾一下普通的知识蒸馏结构是如何工作的,如下图所示:
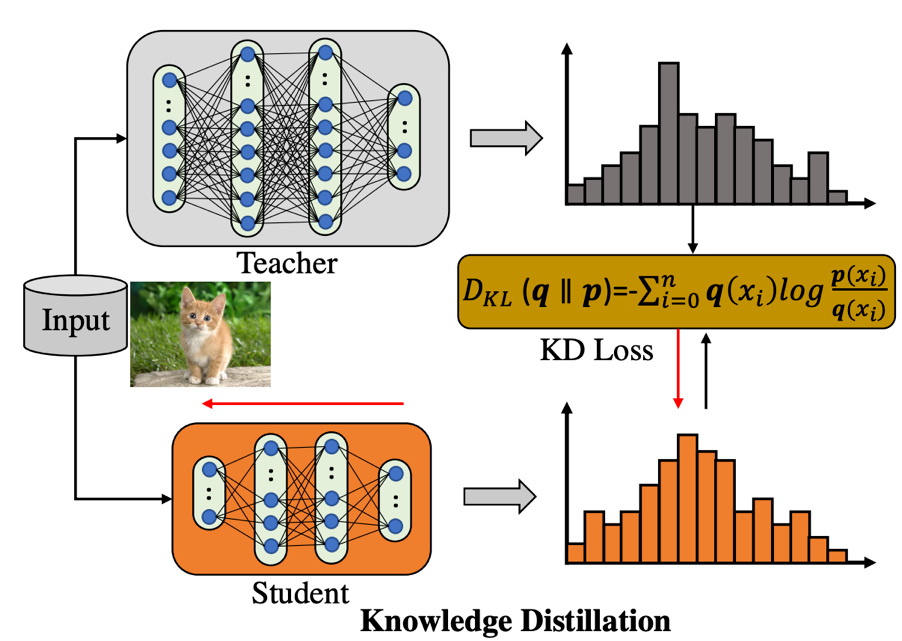
知识蒸馏框架包含了一个预训练好的 teacher 模型(蒸馏过程权重固定),和一个待学习的 student 模型, teacher 用来产生 soft 的 label 用于监督 student 的学习。可以看到,这个框架存在一个比较明显的缺点:当 teacher 结构大于 student 的时候,训练图像前馈产生的计算开销已经超过 student,然而 teacher 权重并不是我们学习的目标,导致这种计算开销本质上是 “无用的”。本文的动机正是在研究如何在知识蒸馏训练过程中避免或者说重复利用这种额外的计算结果,该文章的解决策略是提前保存每张图片不同区域的软监督信号(regional soft label)在硬盘上,训练 student 过程同时读取训练图片和标签文件,从而达到复用标签的效果。所以问题就变成了:soft label 怎么来组织和存储最为有效?请从原文中找到答案。
6. Google Brain提出基于Diffusion的新全景分割算法
原文:
https://mp.weixin.qq.com/s/CXMzZd0JP0XBJzEPhPmLvA
A Generalist Framework for Panoptic Segmentation of Images and Videos
标题:
A Generalist Framework for Panoptic Segmentation of Images and Videos
作者:
Ting Chen, Lala Li, Saurabh Saxena, Geoffrey Hinton, David J. Fleet
原文链接:
https://arxiv.org/pdf/2210.06366.pdf
引言
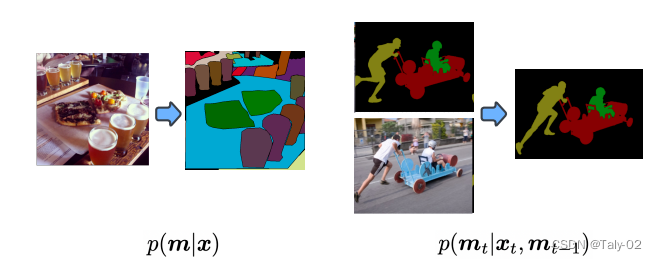
首先回顾一下全景分割的设定。全景分割(PS,Panoptic Segmentation)的task format不同于经典的语义分割,它要求每个像素点都必须被分配给一个语义标签(stuff、things中的各个语义)和一个实例id。具有相同标签和id的像素点属于同一目标;对于stuff标签,不需要实例id。与实例分割相比,目标的分割必须是非重叠的(non-overlapping),因此对那些每个目标单独标注一个区域是不同的。虽然语义标签的类类别是先验固定的,但分配给图像中对象的实例 ID 可以在不影响识别的实例的情况下进行排列。因此,经过训练以预测实例 ID 的神经网络应该能够学习一对多映射,从单个图像到多个实例 ID 分配。一对多映射的学习具有挑战性,传统方法通常利用涉及对象检测、分割、合并多个预测的多个阶段的管道这有效地将一对多映射转换为基于识别匹配的一对一映射。这篇论文的作者将全景分割任务制定为条件离散数据生成问题,如下图所示。本文是大名鼎鼎的Hinton参与的工作,非常有意思,又是基于diffusion model模式的生成模型来完成全景分割,将mask其视为一组离散标记,以输入图像为条件,预测得到完整的分割信息。
全景分割的生成式建模非常具有挑战性,因为全景掩码是离散的,或者说是有类别的,并且模型可能非常大。例如,要生成 512×1024 的全景掩码,模型必须生成超过 1M 的离散标记(语义标签和实例标签)。这对于自回归模型来说计算开销是比较大的,因为 token 本质上是顺序的,很难随着输入数据的规模变化而变化。扩散模型更擅长处理高维数据,但它们最常应用于连续域而不是离散域。通过用模拟位表示离散数据,本文作者表明可以直接在大型全景分割上完成diffusion的训练,而不需要在latent space进行学习。这样就使得模型 这对于自回归模型来说是昂贵的,因为它们本质上是顺序的,随着数据输入的大小缩放不佳。diffusion model很擅长处理高维数据,但它们最常应用于连续而非离散域。通过用模拟位表示离散数据,论文表明可以直接在大型全景掩模上训练扩散模型,而无需学习中间潜在空间。接下来,我们来介绍本文提出的基于扩散的全景分割模型,描述其对图像和视频数据集的广泛实验。在这样做的过程中,论文证明了所提出的方法在类似设置中与最先进的方法相比具有竞争力,证明了一种新的、通用的全景分割方法。
方法
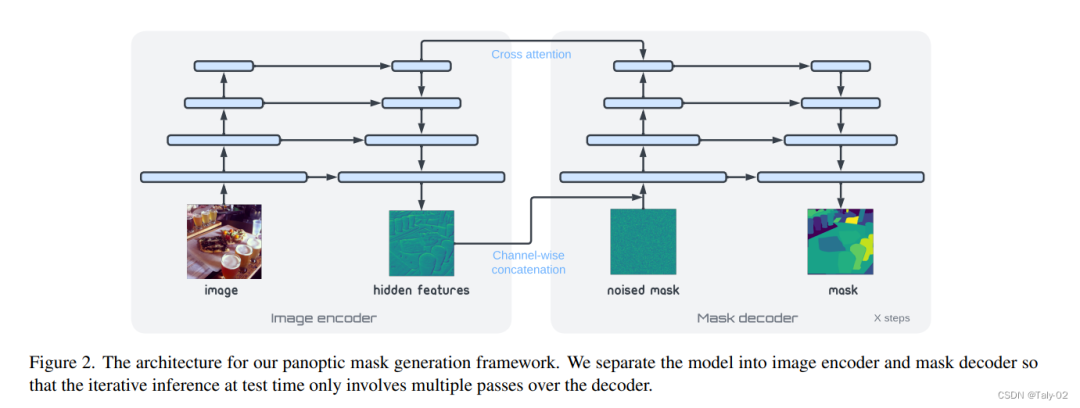
扩散模型采样是迭代的,因此在推理过程中必须多次运行网络的前向传递。因此,如上图,论文的结构主要分为两个部分:1)图像编码器;2)mask的解码器。前者将原始像素数据映射到高级表示向量,然后掩模解码器迭代地读出全景掩模。
实验
来看实验结果:
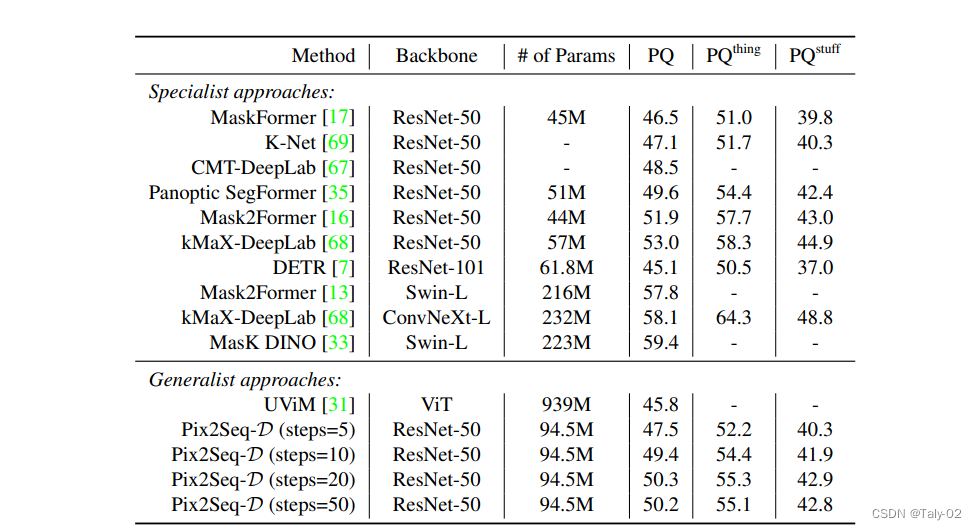
在 MS-COCO 数据集上,Pix2Seq-D 在基于 ResNet-50 的主干上的泛化质量(PQ)与最先进的方法相比有一定的竞争力。与最近的其他通用模型如 UViM 相比,本文的模型表现明显更好,同时效率更高。
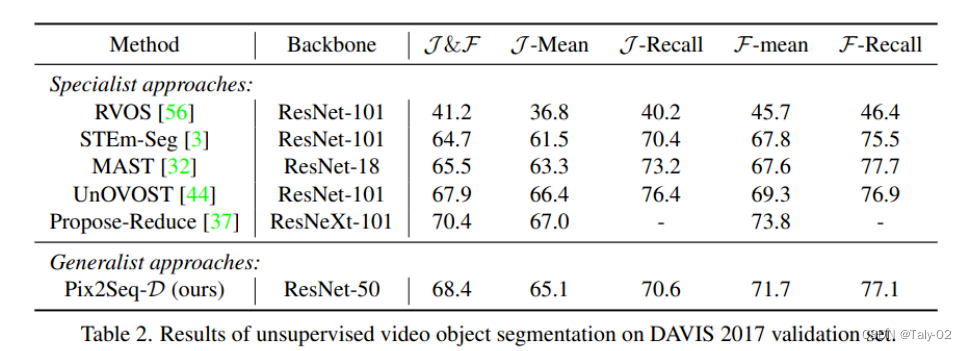
而在无监督数据集DAVIS上,也有更优的表现。
结论
本文基于离散全景蒙版的条件生成模型,提出了一种用于图像和视频全景分割的新型通用框架。通过利用强大的Bit Diffusion 模型,我们能够对大量离散token建模,这对于现有的通用模型来说是困难的。
———————End———————
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!

爱我就给我点在看
点击阅读原文进入官网
原文标题:【AI简报第20230210期】 ChatGPT爆火背后、为AIoT和边缘侧AI喂算力的RISC-V
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- RT-Thread
-
直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨2026-05-15 132
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 973
-
OrangePi RV2 深度技术评测:RISC-V AI融合架构的先行者2026-03-03 11507
-
借势 RISC-V与 AI 浪潮,元石智算打造算力新范式2025-07-25 915
-
RISC-V,即将进入应用的爆发期2024-10-31 621
-
risc-v多核芯片在AI方面的应用2024-04-28 1001
-
RISC-V mcu何时进军AI2023-11-04 1306
-
阿里平头哥发布首个 RISC-V AI 软硬全栈平台2023-08-26 842
-
ChatGPT大火!庞大的AI算力需求面临巨大挑战2023-02-15 764
-
为AIoT和边缘侧AI喂算力的RISC-V2023-02-06 3401
-
嘉楠科技发布的端侧RISC-V AIoT芯片K2302022-11-30 3106
-
RISC-V生态逐渐成型,华秋助推嘉楠旗下首款基于Linux的Risc-V内核高精度AI 处理器2022-11-18 11741
-
千芯科技推出了针对芯来RISC-V平台的AI部署工具包(tinyAI SDK)2020-11-21 2507
全部0条评论

快来发表一下你的评论吧 !
