

NerfingMVS:引导优化神经辐射场实现室内多视角三维重建
描述
本文是对我们ICCV 2021被接收的文章NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo 的介绍。在这个工作中,我们通过对神经辐射场(NeRF)进行引导优化,实现了室内的多视角三维重建(multi-view stereo)。很荣幸地,我们的文章被接收为ICCV 2021的Oral论文,目前项目代码已开源,欢迎大家试用和star~


效果展示
arXiv:https://arxiv.org/abs/2109.01129
主页:https://weiyithu.github.io/NerfingMVS/
Code:https://github.com/weiyithu/NerfingMVS
概述
熟悉3D视觉领域的朋友们都知道,近一年来NeRF大火。NeRF概括来说是一个用MLP学习得到的神经辐射场。它的训练数据是多视角的RGB图片。学得的神经辐射场可以表示场景的三维结构,从而实现新视角的视图合成。对NeRF更加具体的介绍,请大家参考林天威:https://zhuanlan.zhihu.com/p/360365941
既然Nerf可以表示场景的三维信息,一个自然的想法是能不能将NeRF应用到室内场景三维重建任务中呢。NeRF有着一些优势:相较于传统的MVS,SfM算法,NeRF蕴含了整个场景的信息,所以有潜力重建出低纹理区域的三维结构;而相较于另一个在线优化的深度估计算法CVD ,NeRF不需要显示地对不同视角的像素进行匹配,这一点在室内场景是很难做到的。但可惜的是,原生NeRF在室内场景中存在形状辐射歧义(shape-radiance ambiguity)的问题。这个问题的大致意思是NeRF可以合成出高质量的新视角的RGB图片,但它却没有学会场景的三维结构。
为了解决这个问题,我们提出了NerfingMVS。我们方法的核心是用网络预测出来的深度先验去引导神经辐射场的优化过程。我们首先用SfM得到的稀疏深度训练一个专属于当前场景的单目深度网络。之后用这个单目深度网络预测的深度图来指导NeRF的学习。最后我们根据视角合成的结果利用滤波器去进一步提升深度图的质量。在ScanNet上的实验结果表明,我们的方法超过了当前最好方法的性能,并且我们还提升了新视角RGB图片的质量以及缩短了三倍的NeRF训练时间。
方法
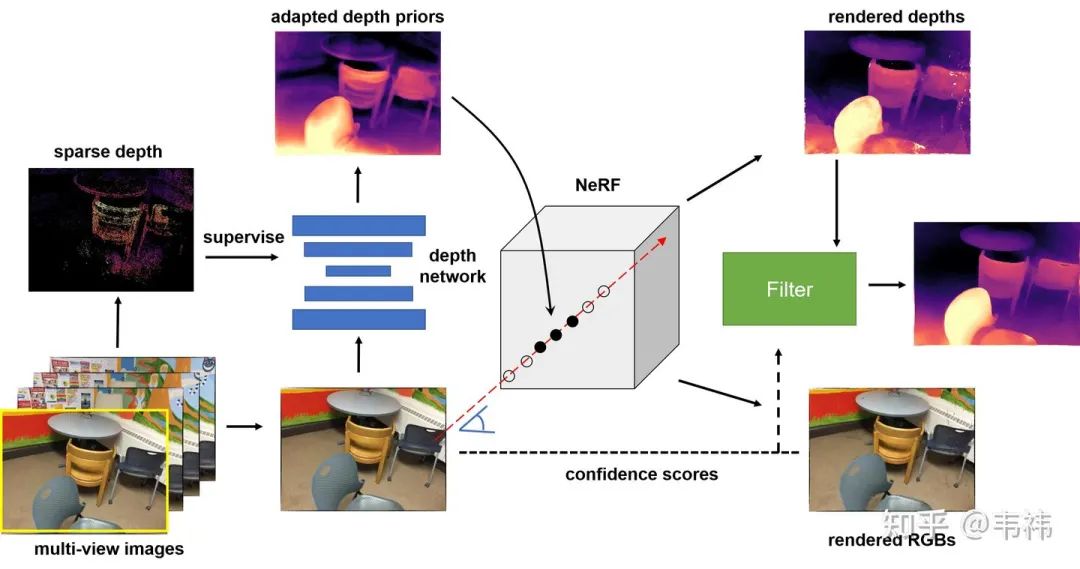
我们的方法分为三个步骤:场景敏感的深度先验,神经辐射场的引导优化,基于合成视图的深度图滤波。
场景敏感的深度先验:与CVD类似,我们同样利用了神经网络预测出来的深度先验。但不同的是,为了进一步提升深度先验在当前场景的精度,我们利用SfM重建出的稀疏深度对单目深度网络进行了微调(finetune)。这一步的目的其实是让这个深度网络过拟合在当前场景上。具体来说,我们使用了COLMAP算法得到了多视角融合的点云,并将点云投影到各个视角下得到每个视角的稀疏深度。由于多视角融合的点云是经过了几何一致性校验的,因此虽然深度是稀疏的,但也是相对准确的。此外,由于尺度歧义的问题,我们使用了尺度不变的损失函数:
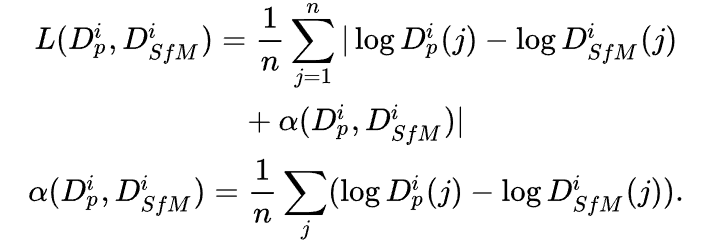
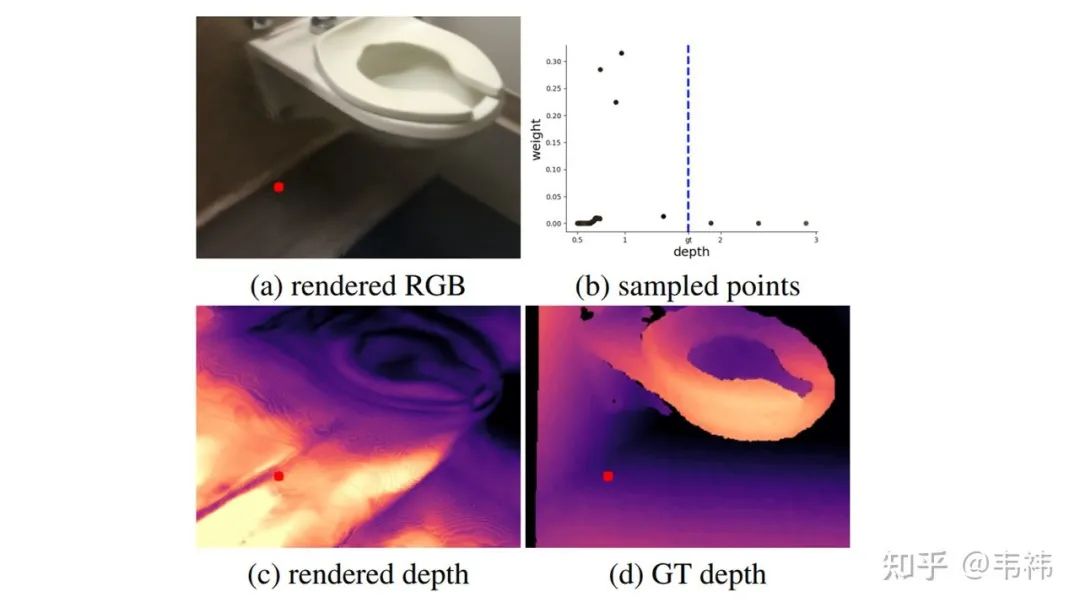
神经辐射场的引导优化:我们发现如果简单地在室内场景应用NeRF无法得到正确的三维重建结果。这其实就是所谓的形状辐射歧义现象,换句话说,NeRF可以很好地拟合出训练视角的RGB图片(图(a)),但却没有学到正确的场景3D结构(图(c))。造成这个问题的本质原因是对于同一组RGB图片,会有多个神经辐射场与之对应。此外,现实室内场景的RGB图片会比较模糊并且图片之间的位姿变换也会比较大,这导致了网络的学习能力下降,加剧了这个问题。
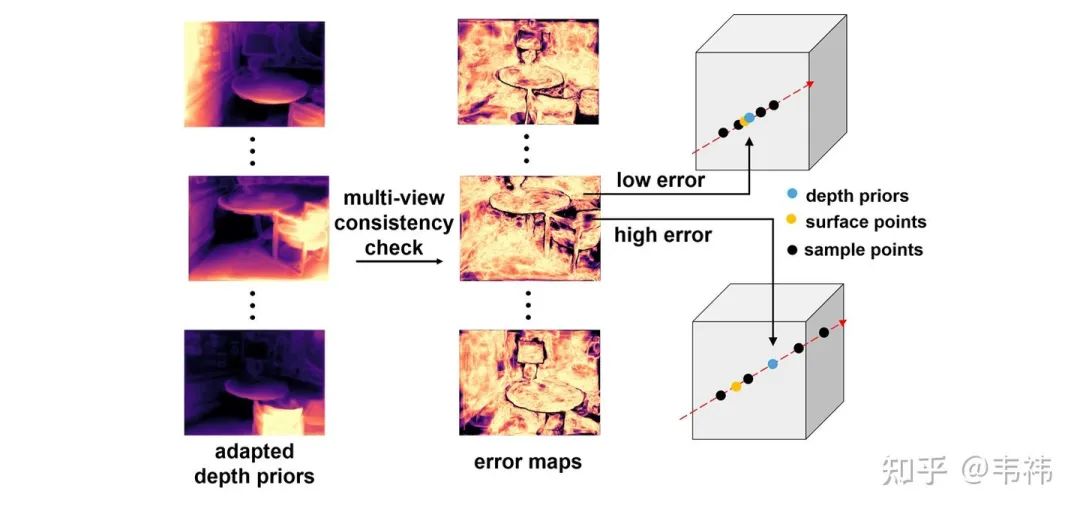
为了解决这个问题,我们利用深度先验去指导NeRF的采样过程。我们首先根据几何一致性校验计算得到每个视角深度先验的误差图。具体来讲,我们将每个视角的深度投影到其它视角下并与其它视角的深度计算相对误差。NeRF中每个视角下每条ray的采样中心点为对应位置处的深度先验,采样范围由误差图决定。误差越小,深度先验的置信度越高,那么采样范围就越小;反之,误差越大,深度先验的置信度越低,那么采样范围就越大。
基于合成视图的深度图滤波:为了进一步提升深度图的质量,我们最后进行了一步滤波。这步操作是基于一个假设:如果渲染出的RGB都不对,那么对应位置处算出来的深度也往往是错的。因此我们可以根据渲染得到的RGB与真实RGB之间的误差计算逐像素的置信度图:
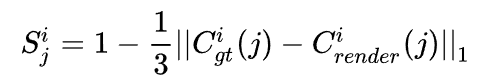
这个置信度图可以被用来滤波,我们这里使用的是平面双边滤波器(plane bilateral filtering)。
实验结果
与SOTA方法对比:

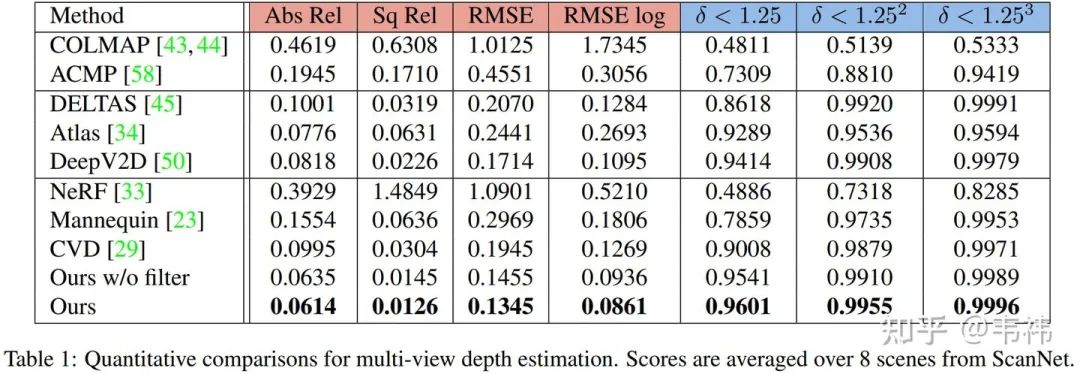
无论是从定量还是定性的结果来看,我们的方法都达到了当前最好性能,甚至超过了一些有监督的方法:DELTAS,Atlas,DeepV2D。
视图合成结果:

前两行是训练视角,后两行是新视角。尽管视图合成不是我们的主要任务,我们的方法仍显著地提升了NeRF视图合成的结果。训练视角的提升也说明了我们的方法可以帮助NeRF聚焦在更重要的区域并提升网络的性能。此外,我们将NeRF的训练时间缩短至三分之一。
In-the-wild结果展示:
我们用手持相机在家拍摄了一些demo。


总结与讨论
在这个工作中,我们将传统SfM算法与NeRF结合解决室内多视角重建问题。我们方法的核心是将深度先验引入NeRF中指导它的采样过程。在真实室内场景数据集ScanNet上的实验结果表明,NerfingMVS取得了很好的效果。当然我们的方法现在也存在一些limitations:1. 尽管我们大大加速了NeRF的训练过程,但现在仍无法达到实时。2. 我们需要SfM提供位姿和稀疏深度,因此比较依赖COLMAP的重建结果。
审核编辑 :李倩
-
怎样去设计一种基于RGB-D相机的三维重建无序抓取系统?2021-07-02 2130
-
如何去开发一款基于RGB-D相机与机械臂的三维重建无序抓取系统2021-09-08 2264
-
无人机三维建模的信息2021-09-16 2239
-
基于纹理映射的医学图像三维重建2008-12-14 1155
-
基于FPGA的医学图像三维重建系统设计与实现2011-03-15 1343
-
为什么说三维重建才是计算机视觉的灵魂?2019-07-02 32177
-
透明物体的三维重建研究综述2021-04-21 1294
-
基于分布式传感的实时三维重建系统2021-06-25 1032
-
NVIDIA Omniverse平台助力三维重建服务协同发展2022-10-13 2620
-
深度学习背景下的图像三维重建技术进展综述2023-01-09 4361
-
从多视角图像做三维场景重建 (CVPR'22 Oral)2023-02-20 4414
-
三维重建:从入门到入土2023-03-03 2455
-
如何实现整个三维重建过程2023-09-01 2917
-
基于光学成像的物体三维重建技术研究2023-09-15 2070
-
航天宏图全栈式3DGS实景三维重建系统解决方案2025-06-27 2330
全部0条评论

快来发表一下你的评论吧 !
