

利用视觉+语言数据增强视觉特征
描述
研究动机
传统的多模态预训练方法通常需要"大数据"+"大模型"的组合来同时学习视觉+语言的联合特征。但是关注如何利用视觉+语言数据提升视觉任务(多模态->单模态)上性能的工作并不多。本文旨在针对上述问题提出一种简单高效的方法。
在这篇文章中,以医疗影像上的特征学习为例,我们提出对图像+文本同时进行掩码建模(即Masked Record Modeling,Record={Image,Text})可以更好地学习视觉特征。该方法具有以下优点:
简单。仅通过特征相加就可以实现多模态信息的融合。此处亦可进一步挖掘,比如引入更高效的融合策略或者扩展到其它领域。
高效。在近30w的数据集上,在4张NVIDIA 3080Ti上完成预训练仅需要1天半左右的时间。
性能强。在微调阶段,在特定数据集上,使用1%的标记数据可以接近100%标记数据的性能。
方法(一句话总结)
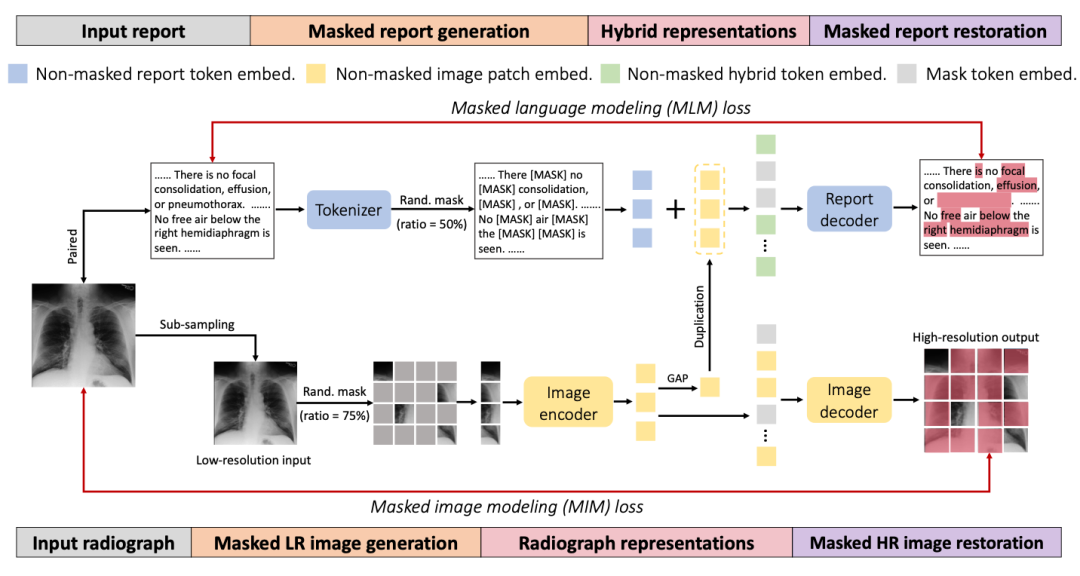
如上图所示,我们提出的训练策略是比较直观的,主要包含三步:
随机Mask一部分输入的图像和文本
使用加法融合过后的图像+文本的特征重建文本
使用图像的特征重建图像。
性能
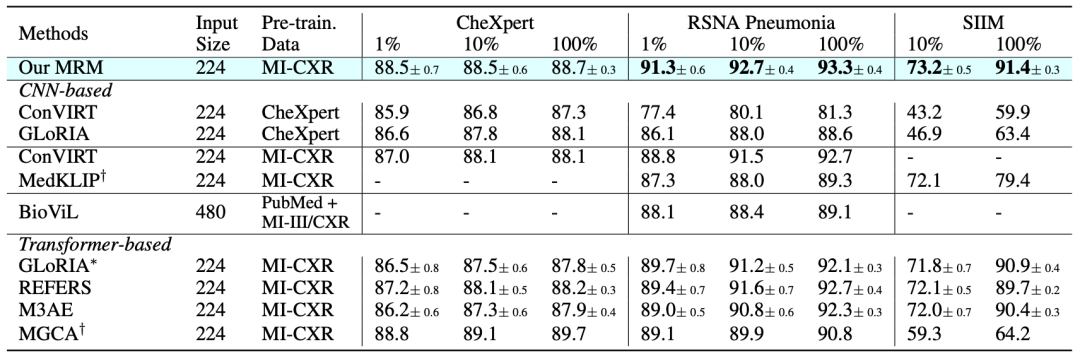
如上图所示,我们全面对比了现有的相关方法和模型在各类微调任务上的性能。
在CheXpert上,我们以1%的有标记数据接近使用100%有标记数据的性能。
在RSNA Pneumonia和SIIM (分割)上,我们以较大幅度超过了之前最先进的方法。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
利用视觉助手生成图像采集、处理、提取特征VI2012-11-30 15353
-
机器视觉算法与应用(双语版)2016-06-29 3920
-
鲁班,视觉生成引擎的应用2018-04-28 3480
-
光学视觉对中系统2018-09-03 2777
-
基于视觉特征的网页正文提取方法研究2010-11-09 716
-
结合高层对象特征和低层像素特征的视觉注意方法2017-12-09 950
-
视觉传感器必须具备的五大特征_视觉传感器应用2018-03-01 12218
-
桥接视觉与语言的研究综述2019-08-09 3585
-
利用视觉语言模型对检测器进行预训练2022-08-08 2440
-
视觉-语言预训练入门指南2023-02-06 1873
-
如何利用Transformers了解视觉语言模型2023-03-03 1808
-
机器视觉与生物特征识别的关系2023-08-09 1614
-
OpenVINO赋能BLIP实现视觉语言AI边缘部署2023-09-01 3148
-
OpenVINO™ 赋能 BLIP 实现视觉语言 AI 边缘部署2023-09-04 1699
-
VLM(视觉语言模型)详细解析2025-03-17 9994
全部0条评论

快来发表一下你的评论吧 !
