

嵌入式系统中函数如何调用
电子说
描述
1 程序的内存分布
嵌入式系统中,一个函数调用时,它的内部机理是什么,执行了哪些步骤?如图1所示,先看 看 一个程序在运行时,它的内存分布状况。
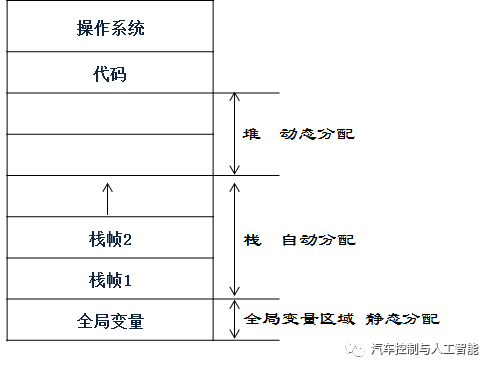
*** 图1 系统中的内存分布***
当程序运行时,它的代码会被装入内存,保存在代码区,包括主函数和其他函数。主要有三块内存区域用来存放数据:
第一块是全局变量区域,存放了程序当中的所有全局变量。由于全局变量的个数和大小是已知的,所以这一块区域所占用的内存大小在开始就确定下来,它们被称为是静态分配。位于此区域内的变量,它们在程序的整个运行过程当中,都一直存在,只有当整个程序运行结束了, 这一块内存区域才会被释放。
第二块区域是栈(stack)区域,它包含了所有的栈帧。所谓的栈帧( stack frame),就是在调用函数时,系统自动地为该函数分配一块内存区域,用来保存它的运行上下文、形参和局部变量等信息,这样的一块内存区域,就叫做一个栈帧。栈帧是在函数调用时分配,当函数调用结束,相应的栈帧则被释放。所以,对于一个函数的局部变量来说,只有当函数调用发生时,系统才会给这个函数的形参和局部变量分配存储空间;当函数调用结束后,这些局部变量就被释放掉了。另外,栈区是由系统自动分配,用户不需要关心,所以也称为是自动分配。
第三块区域是堆(heap) 区域,它主要是用作动态分配的内存。
举个例子对应起来看,直观一些。

*** 图2 内存分布示例***
如图2所示,程序开始运行,demudashu()这个函数会被装入到内存。它的代码存放在内存的代码区域。由于在这段程序中定义了一个全局变量z,所以内存的全局变量区域分配了一个存储单元给它。
接下来,系统调用函数运行,当这个函数调用发生,系统就会在栈中给它分配一块内存空间,即一个栈帧,用来存放函数当中所定义的局部变量,即x和y。
随后,程序计数器PC就跳转到函数的第一条语句,开始执行。
当函数执行结束,首先要把它所占用的栈帧释放掉。对于任何一次函数调用而言,在函数调用结束后,都要把相应的栈帧释放掉,所以x和y这两个局部变量所占用的存储空间就被释放掉了。
当一次函数调用发生时,它的执行过程可以归纳为以下5个步骤:
- 在内存的栈空间当中为其分配一个栈帧,用来存放该函数的形参变量和局部变量。
- 把实参变量的值复制到相应的形参变量中。
- 控制流转移到该函数的起始位置。
- 该函数开始执行。
- 当这个函数执行完以后,控制流和返回值返回到函数调用点。
下面用一个例子来总结下变量的存储与作用域。
/* 全局变量,固定地址,其他源文件可见*/
int demu_global_static;
/* 静态全局变量,固定地址,但只在本文件可见*/
static int demu_static;
/* 函数参数:位于栈帧中,动态创建,动态释放*/
int foo(int auto_parameter)
{
/* 静态局部变量 ,固定地址,只在本函数中可见*/
static int func_static;
/* 普通局部变量,位于栈帧中,只在本函数中可见*/
int auto_i,auto_a[10];
/* 动态申请的内存空间,位于堆中*/
double *auto_d = malloc(sizeof (double)*2020);
return auto_i;
}
2 函数的调用
有了上面的内存分配理解再来看看函数的调用。
函数调用过程分五个步骤:
①程序先执行函数调用之前的语句;
②流程的控制转移到被调用函数入口处,同时进行参数传递;
③执行被调用函数中函数体的语句;
④流程返回调用函数的下一条指令处,将函数返回值带回;
⑤接着执行主调函数未执行的语句。
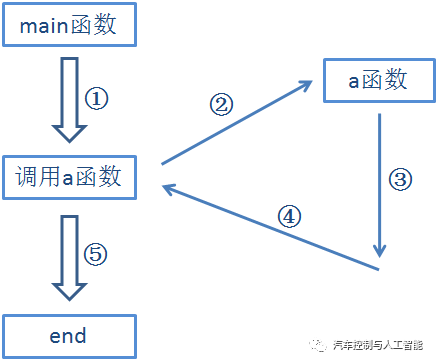
*** 图3 函数调用过程***
这样就要求在转到被调用函数之前,要记下当时执行的指令的地址,还要 “保护现场” (记下当时有关的信息),方便在函数调用之后继续执行。在函数调用之后,流程返回到先前记下的地址处,并且根据记下的信息 “恢复现场” ,然后继续执行。这些过程都会花费一定的时间。如果有的函数需要频繁的使用,则所用时间会很长,从而降低程序的执行效率。有些实用程序对效率是有要求的,要求系统的响应世间短,这就需要尽量压缩调用过程的时间。
2.1 内置函数
C语言提供了一种提高函数调用效率的方法,即在编译时将所调用的代码直接嵌入到主调函数中,而不是将流程转出去。这种嵌入到主调函数中的函数称为 内置函数 (inline function),又称内嵌函数。有些人把它称为内联函数。
用法:在函数首行的左端加一个关键字inline即可。
还是举个例子来看,明晰一些。
int main()
{ int i = 3, j = 5, k =8, m;
m = max(i, j, k);
cout << "max=" << m = endl;
return 0;
}
inline int max(int a, int b, int c);//定义max为内置函数
{
if (b > a)
a = b;
if (c > a)
a = c;
return a;
}
由于定义函数时指定它为内置函数,因此编译系统在遇到函数调用“max(i,j,k)”时,就用max函数体的代码代替“max(i,j,k)”,同时将实参代替形参。在声明函数和定义函数时可以同时写inline,也可以只在其中一处声明inline,效果相同,都能按内置函数处理。
使用内置函数可以节省运行时间,但却增加了目标程序的长度。假设要调用10次max函数,则编译时先后10次将max代码复制并插入main函数,这就增加了目标文件main函数的长度。因此一般只将规模很小而使用频繁的函数(如定时采集数据的函数声明为内置函数)。在函数规模很小的情况下,函数调用的时间可能相当于甚至超过执行函数本身的时间,把它定义为内置函数,可大大减少程序的运行时间。
内置函数中不能包括复杂的控制语句,如循环语句和switch语句。
对函数做inline声明,只是程序设计者对编译系统提出的一个建议,是建议性的,而不是指令性的。并非指定为inline,编译系统必须这样做。它是根据具体情况决定的。例如对前面提到的包含循环语句和switch语句的函数或一个递归函数是无法进行代码置换的,又如一个上万行的函数,也不太可能在调用点展开。此时编译系统就会忽略inline声明,而按普通函数处理。
所以,只有规模较小而又频繁调用的简单函数,才适合于声明为inline函数。
2.2 函数调用过程
前文,如图3,已经描述到,当执行到某一个函数时,系统就会跳转过去执行该函数,执行完毕后接着再去执行下一条指令。在执行调用函数的过程中,系统还要根据函数完成一些工作,这些操作通过形成一个栈帧来完成。栈帧是编译器用来实现函数调用过程的一种数据结构。C语言中,每个栈帧对应着一个未运行完的函数。
下面通过debug,看看Add()函数的执行过程。
int Add(int a, int b)
{
int z = 0;
z = a + b;
return z;
}
int main()
{
int a = 10;
int b = 20;
int ret;
ret = Add(a, b);
printf("%d", ret);
system("pause");
return 0;
}
以下调试过程大家定性看一下调用过程,实际过程和嵌入式系统略有差异。
调用main函数之前在VC6.0编辑器可以看到main函数在_tmainCRTStartup 函数中调用的,而 _tmainCRTStartup 函数是在 mainCRTStartup 被调用的。这个过程要为函数开辟栈空间, 这块栈空间我们称之为函数栈帧。
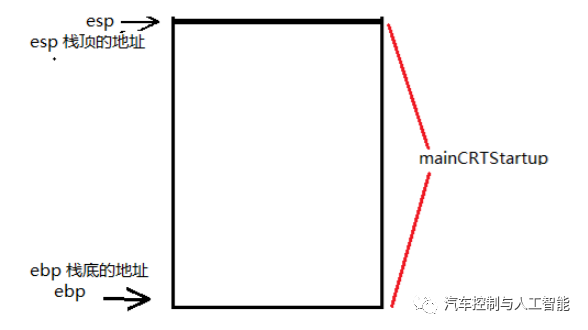
栈帧的需要ebp和esp两个寄存器。在函数调用的过程中这两个寄存器存放了维护这个栈的栈底和栈顶指针 。ebp指向当前位于系统栈最上边一个栈帧的底部,而不是系统栈的底部。严格说来,“栈帧底部”和“栈底”是不同的概念;ESP所指的栈帧顶部和系统栈的顶部是同一个位置。
开始调用main函数
展开main函数的调用就得为main函数创建栈帧,可以看到过程:
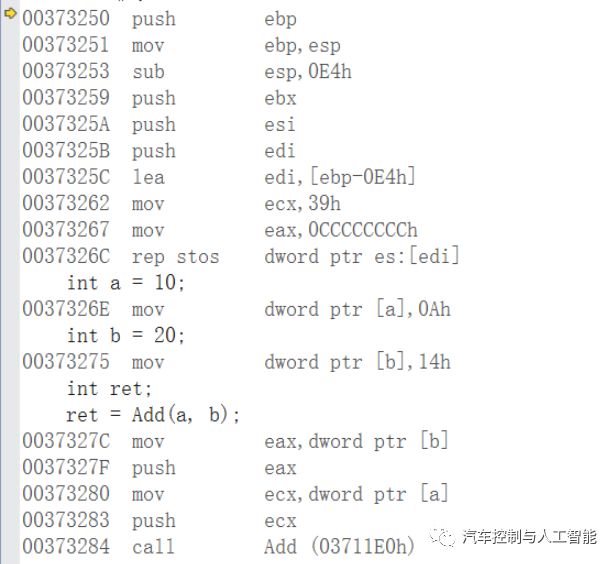
执行上图第一条指令:
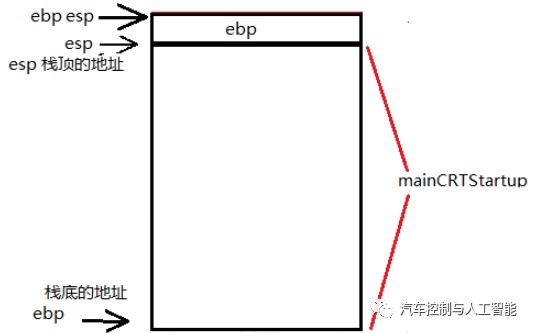
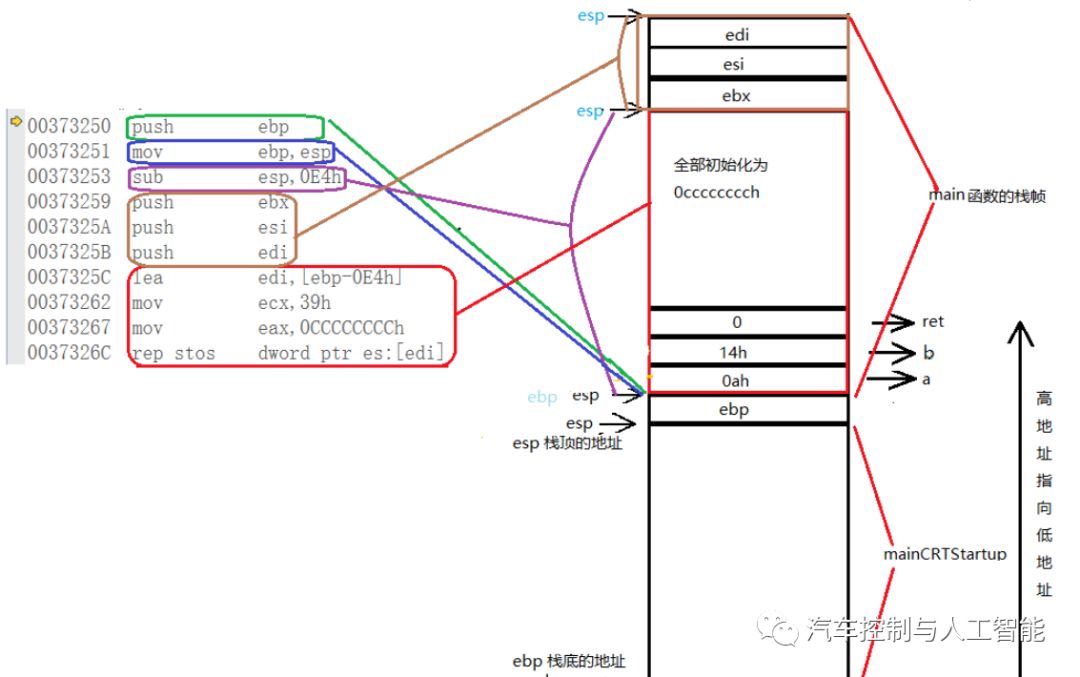
1.压栈,把ebp放入栈顶,而esp始终指向栈顶
2.将esp值传给ebp,也就是让esp,ebp移在一起
3.sub为减的意思,即将esp-0E4h赋给esp,且函数调用分配由高地址向低地址增长,因此esp向上移动,即开辟了新空间,也就是为main函数开辟空间
4.三个push压榨分别将ebx,esi,edi按顺序压入栈顶,而esp也会指向栈顶
5.lea指令,加载有效地址;将ebp-0E4h的地址放入edi中,也就是edi指向ebp-0E4h,把39h放到ecx中,把0cccccccch放到eax中,从edi所指向的地址开始向高地址进行拷贝,拷贝的次数为ecx内容,拷贝的内容为eax内。
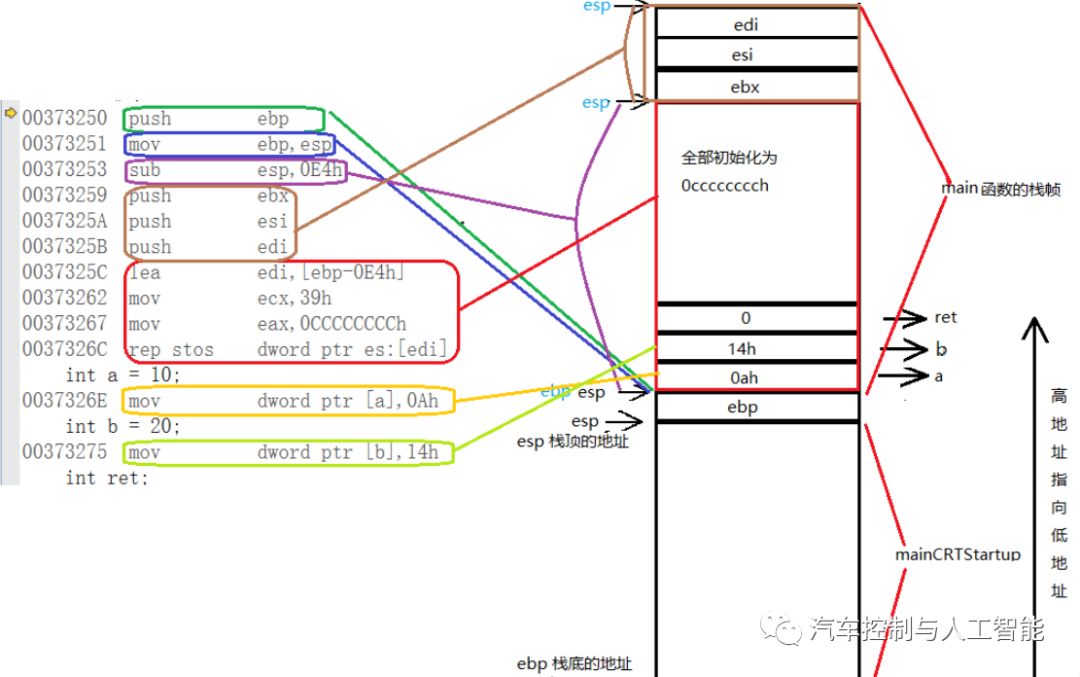
6.创建变量a与b并初始化10和20.
Add函数的调用
1.把b放入eax中,然后对eax压栈(形参a)
2.把a放入ecx中,然后对ecx压栈(形参b)
3.call作用:将下一条指令地址压栈,然后进入add函数里面
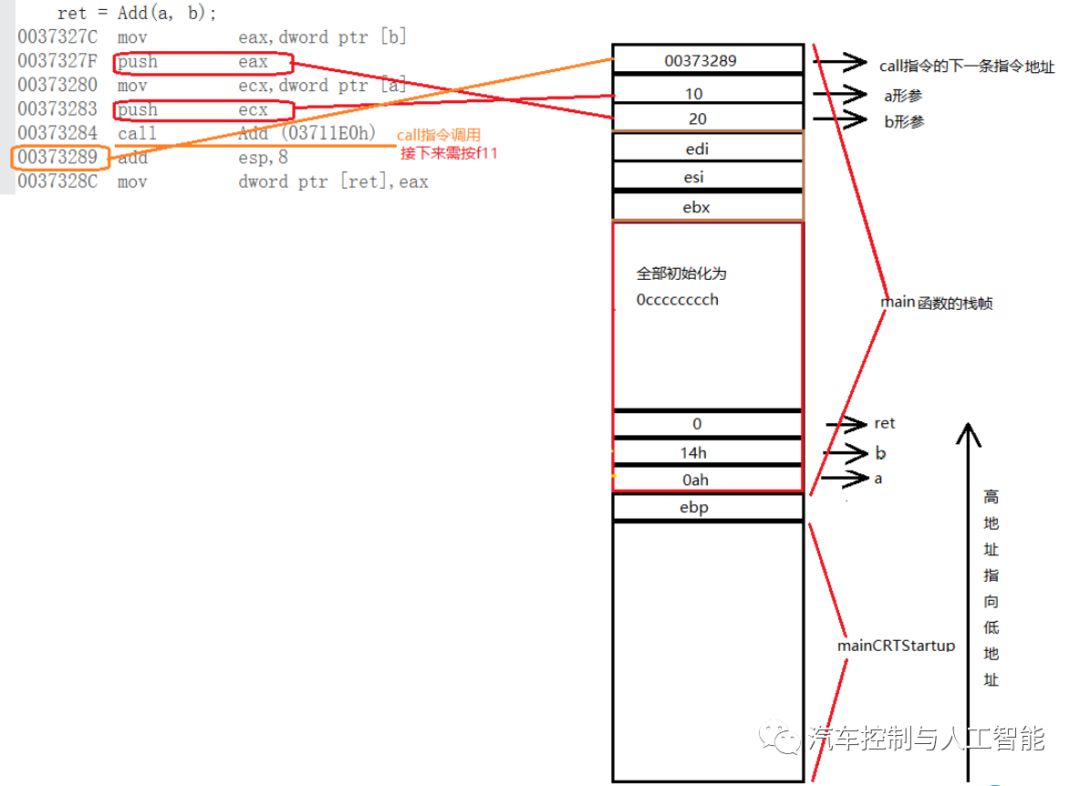
注意:call语句push的是下一条指令的地址,为了函数返回时知道从哪儿接着执行
接下来进入add函数:
A. 先把main函数ebp压栈,保存指向main()函数栈帧底部的ebp的地址,目的是当返回时能找到main函数栈底,此时esp指向新的栈顶位置。将main函数的ebp压栈,也是为了返回时找到main函数栈底。
B. 将esp的值赋给ebp,产生新的ebp,即Add()函数栈帧的ebp;
C. 给esp减去一个16进制数0CCh(为Add()函数预开辟空间);
D. push ebx、esi、edi;
E. lea指令,加载有效地址;
F. 初始化预开辟的空间为0xcccccccc;
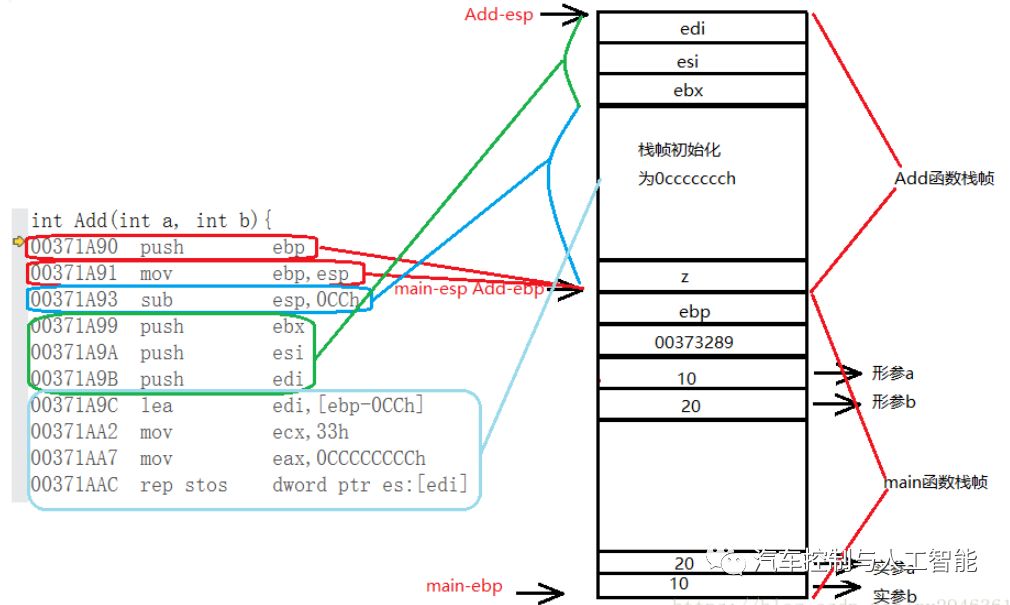
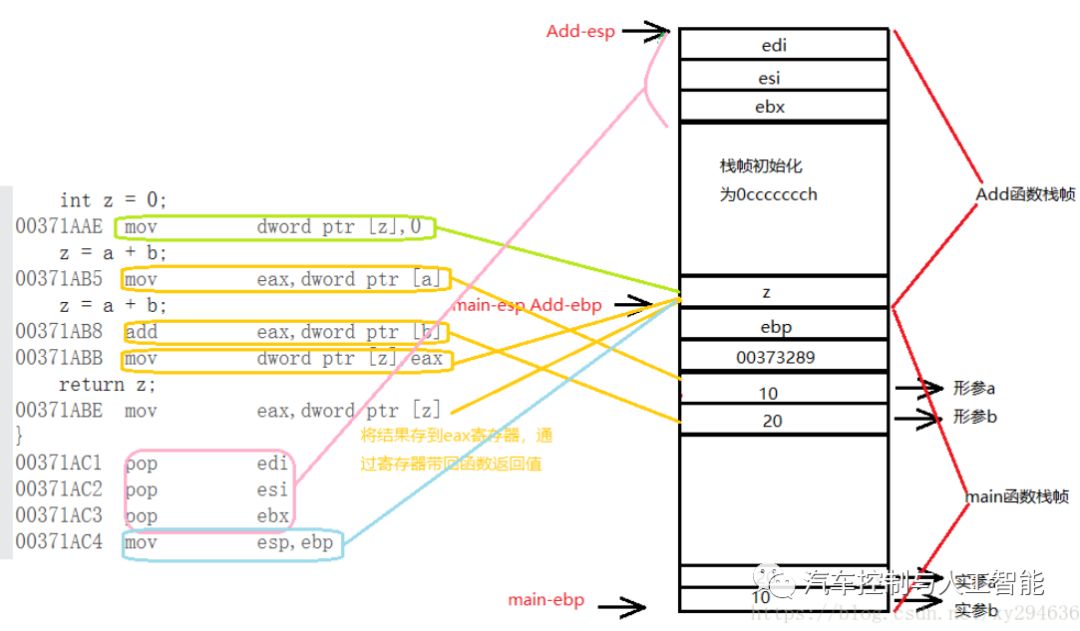
G. 创建变量z并为其赋值;
H. 把形参a放到eax,即把10,放入eax把形参b加到eax中,即把20加到eax中再把eax放到z的位置,即把两数之和放到z中;
I. 把z的值放到寄存器eax中返回,因为z为函数临时开辟的变量空间等函数执行完会销毁,因此放寄存器中返回;
K .接下来执行pop出栈操作,edi esi ebx依次从上向下出栈,esp 会向下移动,栈的特点:先进后出,后进先出;
L. 将ebp值赋给esp,也就是esp向下移动指向ebp位置,此时add开辟的栈空间已经销毁;
M. pop将栈顶的元素弹出放到ebp中,也就是说将main函数的ebp放入ebp中,即ebp现在指向main函数ebp;
N. 在执行ret后,会把之前push的地址弹出去,这时就要返回main函数,这也就是为什么之前要push这个地址,这样call指令就完成了,接下来从那个call指令继续执行;
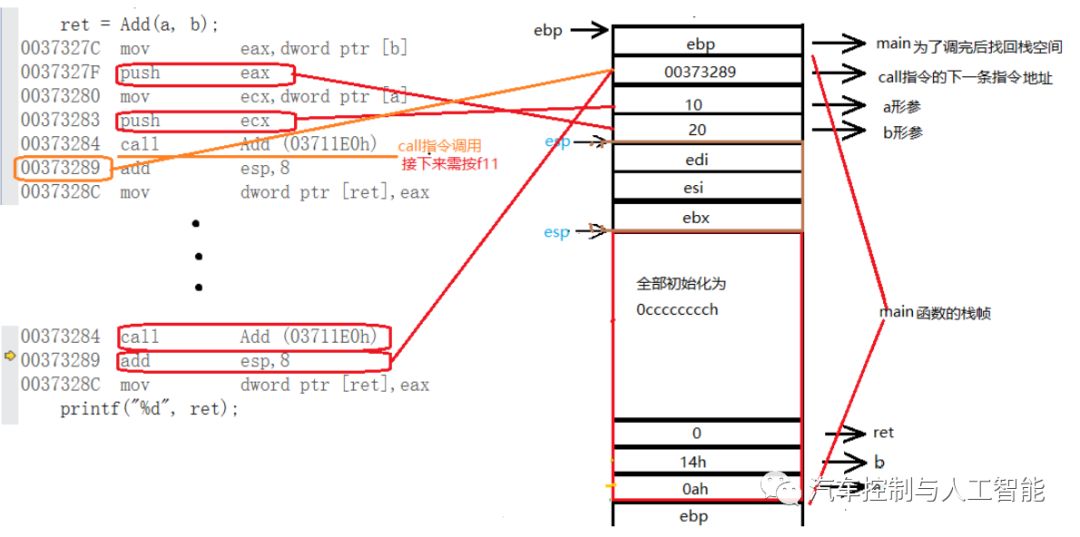
O. 把esp+8,即esp向下移,把形参销毁;
最后就是对main函数栈帧的销毁,方法类似。
栈帧的总结:
1.堆栈是C语言程序运行时必须的一个记录调用路径和参数的空间:
- 函数调用框架;
- 传递参数;
- 保存返回地址;
- 提供局部变量空间;
- 堆栈寄存器和堆栈操作
堆栈相关的寄存器
- esp,堆栈指针(stack pointer)
- ebp,基址指针(base pointer)
堆栈操作
- push 栈顶地址减少4个字节(32位)
- pop 栈顶地址增加4个字节
- ebp在C语言中用作记录当前函数调用基址
3 AUTOSAR中Runnable
Runnable(可运行实体)就是SWC中的函数,而在AUTOSAR架构中,使用工具生成时,Runnable是空函数,需要手动添加代码来实现它的实际功能。Runnable可以被触发,比如被定时器触发、被操作调用触发或者被接受数据触发等。
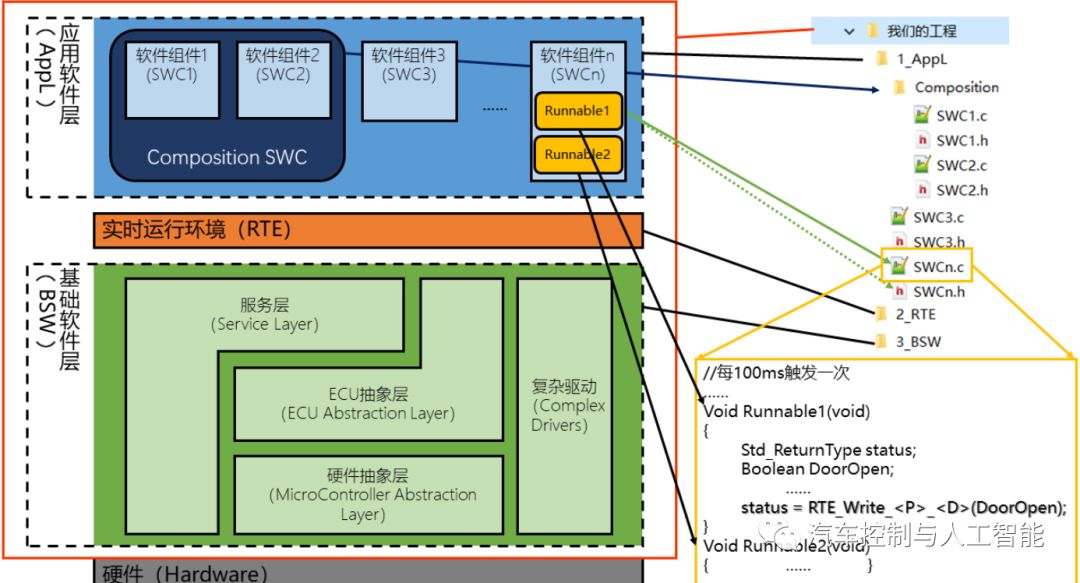
这里的函数就是Send接口,发送的数据由RTE进行管理。然而,由于这个SWCn.c文件中并未包含BSW中的.h文件,通过这个方式将AppL和BSW隔离开。所以如果假如必要的.h文件,其实也可以调用BSW中的函数,但是不建议这么做,该过程 应由RTE来完成触发和调度。
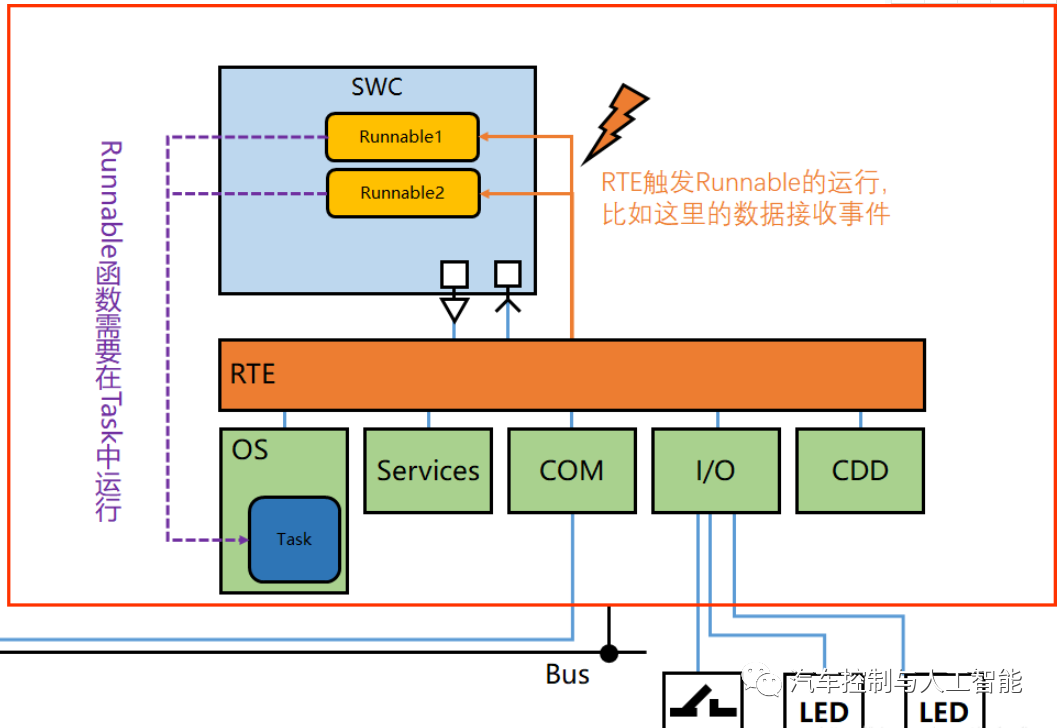
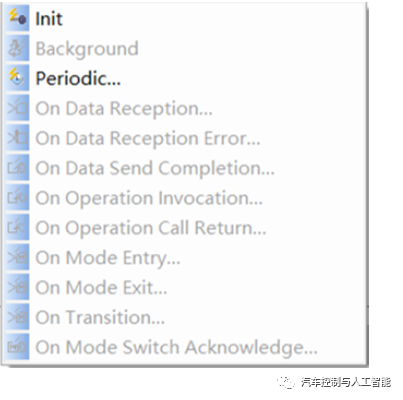
RTE给runnables提供触发条件,也就是runnable在设计的时候,需要有触发条件,不然无法运行,也就没有意义了。触发条件就是一些特定的事件,AUTOSAR中主要规定了以下一些触发条件:
- 初始化事件:初始化自动触发
- 定时器事件:给一个周期定时器,时间到了就触发
- 接收数据事件(S/R):Receiver Port 一旦收到数据触发
- 接收数据错误事件(S/R)
- 数据发送完成事件(S/R):Send Port 发送完成触发
- 操作调用事件(C/S):当调用到了该函数时触发
- 异步服务返回事件(C/S):C/S可以在异步下运行,即当异步调用一个Server函数,那么该被调函数作为一个线程和当前的运行程序并行运行,当被调函数运行结束返回(Return)时,这时触发异步服务返回事件。
- 模式切换事件
- 模式切换应答事件
-
汽车电子嵌入式软件接口库设计2011-01-23 820
-
嵌入式系统中的代码优化与压缩技术2025-02-26 1432
-
嵌入式系统U盘实时启动技术2011-09-05 3075
-
嵌入式开发的优缺点是什么?2021-11-08 1712
-
开发基本的嵌入式应用程序2008-12-25 1797
-
基于Chirp函数的Nios Ⅱ嵌入式实现2011-06-15 1794
-
如何在嵌入式FreeRTOS系统接口调用API?2018-08-04 6446
-
为什么中断处理函数不能直接调用不可重入函数2021-02-17 7212
-
嵌入式开发概述(20190325小结)2021-11-02 944
-
嵌入式软件中的延时函数2021-11-24 939
-
函数调在嵌入式应用设计中如何实现2022-11-28 1346
-
嵌入式软件架构设计之函数调用2023-02-15 1946
-
嵌入式open函数的使用2024-01-04 1784
-
嵌入式系统中堆栈监控的作用2024-01-05 1497
-
嵌入式开发常用函数速查表2026-01-19 658
全部0条评论

快来发表一下你的评论吧 !
