

如何训练ChatGPT?中国版ChatGPT下月面世
描述
中国版ChatGPT下月面世
美国人工智能公司OpenAI的大语言模型ChatGPT在推出约两个月后,1月已达到1亿月活跃用户,成为历史上增长最快的消费者应用程序,更是掀起了新一轮人工智能浪潮。
北京时间2月8日凌晨,微软推出由ChatGPT支持的最新版本必应搜索引擎和Edge浏览器,宣布要“重塑搜索”。微软旗下Office、Azure云服务等所有产品都将全线整合ChatGPT。
更有甚者,中国百度公司2月7日表示,将在今年3月完成类似ChatGPT的项目“文心一言”(ERNIE Bot)的内部测试,加入这场全球竞赛。
百度公司表示,文心一言(其英文名Ernie为“通过知识整合增强表征”的英文缩写)是一种大型人工智能赋能的语言模式,于2019年启动。该公司还说,它已经逐渐发展到能够完成语言理解、语言生成和文本生成图像等任务。
百度称,该公司在人工智能四层架构中拥有全栈布局。“文心一言”位于模型层。基于公司在人工智能领域深耕数十年,拥有产业级知识增强文心大模型ERNIE,具备跨模态、跨语言的深度语义理解与生成能力。
如何训练ChatGPT
ChatGPT现在支持GPT-3.5系列机型,比 GPT3更强大。 这些模型在 Microsoft 的Azure AI超级计算基础设施上使用文本和代码数据进行训练。
具体来说,ChatGPT是在开源数据集上训练的,训练参数比上一代GPT3提升了10倍以上,并且人工标注数据和强化学习,相当于拿回了被GPT3去掉的微调步骤,实现了在与人类互动时从反馈中强化学习。
当我们想要构建一个AI模型时,最重要的步骤总结下来就是:定义架构、训练、调试以及测试。记者询问ChatGPT,你是如何训练的,它的回复是:1. 选择大规模语料库,构建训练集。2. 定义模型架构,通常使用Transformer模型。3. 选择优化算法并设置超参数。4. 训练模型,根据训练损失下降情况和验证集结果决定是否需要调整超参数。5. 使用测试集评估模型性能。6. 如果需要,对模型进行微调,以提高性能。
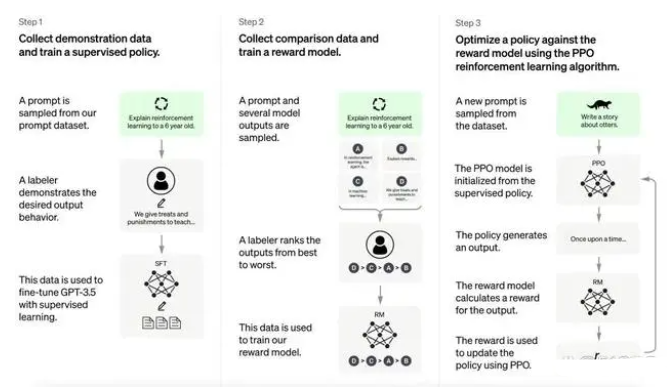
当决定要训练一个语言类AI模型时,第一件事就要明确训练AI的语料库。语料库的选择十分重要,为了让语言模型学到足够多的语言信息,需要选择尽量规模大的文本语料库。以ChatGPT为例,训练类似AI模型时,就需要准备各类网站的百科文章、网络回答、专业论文等。据了解,一款通用AI算法所使用的预训练语料库大小为1-10GB之间,而用于训练ChatGPT的前身——GPT-3的语料库达到了45TB。
训练AI执行语言任务还绕不开Transformer模型。Transformer模型(变换器)是一种采用自注意力机制的深度学习模型,自注意力的意思即可以按照输入数据各部分重要性的不同而分配不同的权重。它通过计算词与词之间的相对位置关系来确定注意力的权值,最终生成语句的语义表示。Transformer的优势在于其可以并行计算,速度快,精度高,是目前自然语言处理中最常使用的模型之一。
文章综合与非网、参考消息网、新华社
-
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢2024-03-28 48761
-
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 42024-02-14 51575
-
ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介2023-12-06 2597
-
chatgpt是什么原理2023-06-27 722
-
ChatGPT是什么?ChatGPT写代码的原理你知道吗2023-06-04 4356
-
ChatGPT对话语音识别YS YYDS 2023-05-30
-
万物皆可ChatGPT ChatGPT的iPhone时刻已到 ChatGPT概念厂商概述2023-03-27 1330
-
ChatGPT是什么?普通人应该如何去使用ChatGPT2023-03-17 4591
-
如何打造中国版的ChatGPT2023-03-03 967
-
让chatGPT帮我写硬件代码,是懂行的,好助手!#chatgpt #物联网开发 #python开发板苏州煜瑛微电子科技有限公司 2023-02-17
-
ChatGPT介绍和代码智能2023-02-14 855
-
ChatGPT使用初探2023-02-13 2220
-
ChatGPT入门指南2023-02-10 3036
全部0条评论

快来发表一下你的评论吧 !
