

ChatGPT实现原理
描述
ChatGPT实现原理
用自然语言与计算机进行通信,ChatGPT实现了,那么ChatGPT实现原理是什么?
ChatGPT(Generative Pre-train Transformer)是由OpenAI发明的一种自然语言处理技术。它是一种预训练的深度学习模型,可以用来生成文本,识别语义,做文本分类等任务。
ChatGPT实现原理
火爆的ChatGPT,得益于AIGC 背后的关键技术NLP(Natural LanguageProcessing,自然语言处理)得到突破。自然语言处理应用在过去十年呈爆炸式增长,NLP技术是一种自然语言处理技术,用于计算机中模拟人类的对话和文本理解。主要源于AI大模型化的NLP技术突破是将深度学习技术与传统的NLP方法结合在一起,从而更好地提高NLP技术的准确性和效率。大模型化的NLP技术能够更好地支持企业进行大规模的语料内容分析,并为企业更好地进行文本分析提供帮助。
NLP类模型要理解单词的含义,还要理解如何造句和给出上下文有意义的回答,甚至使用合适的俚语和专业词汇。
我们看到ChatGPT的回答是这样的:
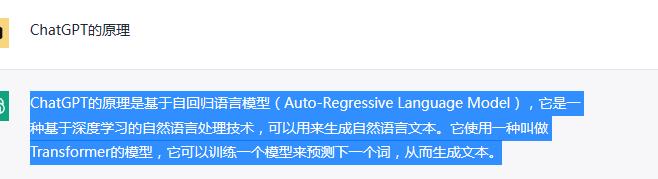
ChatGPT的原理是基于自回归语言模型(Auto-Regressive Language Model),它是一种基于深度学习的自然语言处理技术,可以用来生成自然语言文本。它使用一种叫做Transformer的模型,它可以训练一个模型来预测下一个词,从而生成文本。
人类反馈强化学习
同时OpenAI采用了 RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习) 技术对 ChatGPT 进行了训练,而加入了更多人工监督进行微调。所以我们可以看到,一些错误的信息会逐步被更正。而且在很多用户的测试中可以发现,若用户指出其错误,模型会听取意见并优化答案。
InstructGPT/GPT3.5(ChatGPT的前身)与GPT-3的主要区别在于,新加入了被称为RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。
InstructGPT的目标就是缓解这种生成回复与真实回复之间的偏置产生更加符合人类预期的回复。
chatGPT是一种基于转移学习的大型语言模型,它使用GPT-2 (Generative PretrainedTransformer2)模型的技术,使用了transformer的架构,并进行了进一步的训练和优化。
chatGPT是在GPT-2模型的基础上进一步训练和优化而得到的。 它使用了更多的语料库,并且进行了专门的训练来提高在对话系统中的表现。这使得chatGPT能够在对话中白然地回应用户的输入,并且能够生成流畅、连贯、通顺的文本。
那么接下来我们来看下什么是InstructGPT。从字面上来看,顾名思义,它就是指令式的GPT,“which is trained to follow an instruction in a prompt and provide a detailed response”。接下来我们来看下InstructGPT论文中的主要原理:
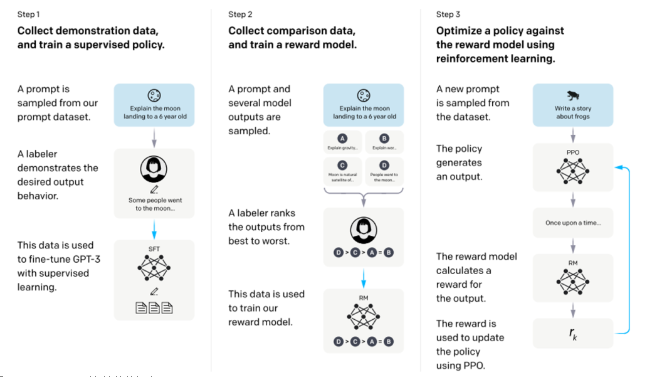
InstructGPT整体训练流程
从该图可以看出,InstructGPT是基于GPT-3模型训练出来的,具体步骤如下:
步骤1.)从GPT-3的输入语句数据集中采样部分输入,基于这些输入,采用人工标注完成希望得到输出结果与行为,然后利用这些标注数据进行GPT-3有监督的训练。该模型即作为指令式GPT的冷启动模型。
步骤2.)在采样的输入语句中,进行前向推理获得多个模型输出结果,通过人工标注进行这些输出结果的排序打标。最终这些标注数据用来训练reward反馈模型。
步骤3.)采样新的输入语句,policy策略网络生成输出结果,然后通过reward反馈模型计算反馈,该反馈回过头来作用于policy策略网络。以此反复,这里就是标准的reinforcement learning强化学习的训练框架了。
所以总结起来ChatGPT(对话GPT)其实就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通过人工标注方式训练出强化学习的冷启动模型与reward反馈模型,最后通过强化学习的方式学习出对话友好型的ChatGPT模型。
InstructGPT的训练实际上是分为三个阶段的,第一阶段就是我们上文所述,利用人工标注的数据微调GPT3;第二阶段,需要训练一个评价模型即Reward Model,该模型需学习人类对于模型回复的评价方式,对于给定的上文与生成回复给出分数;第三阶段,利用训练好的Reward Model作为反馈信号,去指导GPT进一步进行微调,将目标设定为Reward分数最大化,从而使模型产生更加符合人类偏好的回复。
自然语言理解的不同发展阶段
在20世纪60年代,随着计算机技术的发展,自然语言处理技术也进一步提升。当时,美国国家科学基金会(NSF)成立了“自然语言处理研究计划”,专门用于支持自然语言处理技术的研究。同时,英国也成立了“自然语言处理研究室(Natural Language Processing Research Laboratory)”,专门致力于自然语言处理技术的研究与应用。
在20世纪70年代,自然语言处理技术又迎来了一个新的发展阶段。这一时期,自然语言处理技术发展到了语言学理论与计算机科学相结合的阶段。其中,语义学和句法学等语言学理论成为自然语言处理技术研究的重要基础。
在20世纪80年代,随着人工智能技术的进一步发展,自然语言处理技术也进入了一个新的阶段。这一时期,自然语言处理技术得到了广泛应用,并取得了一系列突破性成果。例如,英国语言工程研究所(LEL)在1983年成功开发出了世界上第一个基于人工智能的翻译系统,该系统能够将英语翻译成法语。
在20世纪90年代,自然语言处理技术进一步发展壮大。随着互联网的普及,自然语言处理技术在搜索引擎、社交媒体、客服机器人等领域得到广泛应用。此外,自然语言处理技术还进入了深度学习阶段,开始使用深度神经网络进行语言模型的建立和训练,从而提升自然语言处理技术的准确性和效率。如今,自然语言处理技术已经成为人工智能领域的重要组成部分,并在多个领域得到广泛应用。
-
 jf_08733437
2023-04-11
0 回复 举报我已经注册了,,可是要在哪里才能看到注册信息呢? 收起回复
jf_08733437
2023-04-11
0 回复 举报我已经注册了,,可是要在哪里才能看到注册信息呢? 收起回复
-
树莓派与EthernetHat:用ChatGPT实现的MQTT智能家居项目!2025-06-03 16785
-
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 42024-02-14 46850
-
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢2024-03-28 43873
-
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了2024-05-27 44553
-
ChatGPT对话语音识别YS YYDS 2023-05-30
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2307
-
如何让ChatGPT实现MIMO波束赋形2023-02-03 1473
-
ChatGPT了的七个开源项目2023-02-15 798
-
如何让ChatGPT实现MIMO波束赋形和写一封会议邀请信?2023-02-22 1211
-
微软发布Visual ChatGPT:视觉模型加持ChatGPT实现丝滑聊天2023-03-16 2095
-
基于ChatGPT实现微信机器人2023-03-30 3293
-
ChatGPT是怎么实现的2023-10-16 1979
-
能和Ai-M61模组对话了?手搓一个ChatGPT 语音助手2025-03-12 11861
全部0条评论

快来发表一下你的评论吧 !
