

系统调用与普通的函数调用之间的区别
电子说
描述
我们来聊聊系统调用与普通的函数调用之间的区别。
作为程序员你肯定写过无数的函数,假设有这样两个函数:
void funcB() {
}
void funcA() {
funcB();
}
函数之间是可以相互调用的,这很简单很happy有没有。
要知道是代码、是函数就可以相互调用,不管你用什么语言写的。
假设funcB是内核中的函数,funcA是你自己写的函数,就像这样:
// Linux内核中的函数void funcB() {}// 你的函数void funcA() { funcB();}
那么funcA应该也能调用funcB(如果funcB可以供外界调用的话)。
有的同学可能会惊呼,我们可以自己编写代码调用操作系统的函数,那岂不是可以直接控制操作系统了?
too yong too simple!
如果我们编写的代码可以直接调用所有的操作系统函数那么从某种程度上讲的确可以说是能控制操作系统,但如果操作系统只允许你调用内核中的有限的几个函数呢?
怎么样,你(应用程序)是不是就被限制住了。
你又会问,操作系统是怎样限制应用程序能调用哪些内核中的函数呢?
实际上单靠操作系统这种软件是没有办法限制应用程序能调用哪些以及多少个内核函数的,因此为施加这种限制必须依靠——硬件。
这里的硬件指的就是CPU。
那么CPU又是怎么施加这种限制的呢?
我们先来看看普通的函数调用,函数调用对应的机器指令是call指令,就像这样:
call 0x400410
call指令后的这个地址0x400410就是被调函数的第一条机器指令所在的内存地址。
当CPU执行到这条机器指令时直接跳转到对应的地址继续执行指令,从程序员的角度看就是函数调用。
而如果是我们程序的函数调用操作系统的函数就不允许使用call指令了,而是syscall机器指令(x86_64)。
使用syscall指令调用操作系统函数时也是把相应函数的第一条指令的地址放到syscall之后吗?
显然不是的,因为操作系统系统代码和你的代码都是单独编译以及运行的,你根本就不知道操作系统的某个函数存放在内存的什么位置上,也不应该让你知道,因此使用syscall调用操作系统的函数时我们只能附加一个序号,比如序号0对应操作系统中的A函数、序号1对应操作系统中的B函数等等,这样使用syscall指令时只需要将该序号写入rax寄存器即可,CPU在执行syscall指令时通过读取rax寄存器的值就能知道到底该调用操作系统中的哪个函数了。
可以看到,利用这种机制操作系统限制了应用程序可以调用哪些内核中的函数。
有的同学可能会有疑问,如果一个call指令因为种种原因后面跟上的地址”无意“中指向了一个内核函数的地址,那么CPU执行call指令时会怎样呢?就像这样:
call 0x400410
这里假设0x400410这个地址指向了一个内核函数地址。
很简单,CPU在执行这条指令时会判断出当前进程没有权限访问0x400410这个地址,因此CPU在执行这条指令时会产生异常,该进程会被直接kill掉。
这里列举了Linux在各种处理器上怎样进行系统调用。
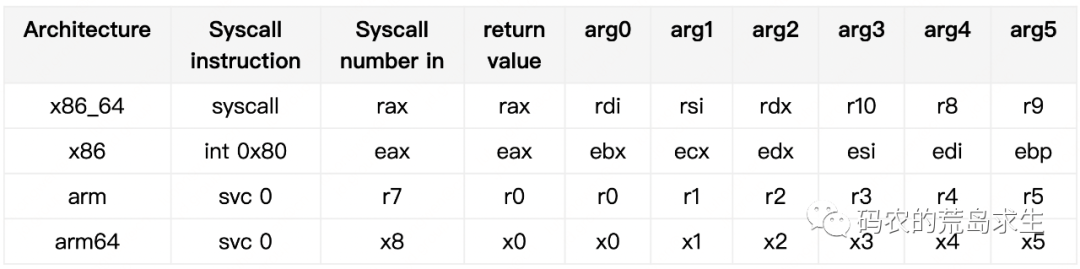
看到了吧,syscall和call在使用方法上还是有很大不同的,可以看到call是直接调用的,也就是说应用程序这一层中的函数调用是直接调用的,而syscall其实是间接调用的,即我们调用操作系统中的函数时其实是间接调用的。
除此之外,CPU在执行call指令以及syscall指令时另外一个不同点在于模式的切换。
当CPU执行普通函数时其实是运行在用户态,user mode,在这种模式下CPU不能执行某些特权指令,这也就意味着我们的程序其实是受限的;而当CPU执行syscall开始执行操作系统的代码时会切换到内核态,kernel mode,在这种模式下CPU可以执行任何特权指令,不受任何限制,操作系统才是真正的管理计算机的大boss。
可以看到,当在普通程序中进行函数调用时就是函数调用,而普通函数调用操作系统中的函数时才叫系统调用。
最后再说一点,普通的函数调用所使用的栈全部位于进程的栈区,假设main函数调用funcA函数,funcA调用funcB函数,那么此时的进程内存布局就像这样:

而进行系统调用时当CPU开始执行操作系统的代码时不再基于进程栈区而是会跳转到操作系统某个特定内存区域,该区域作为进程在内核中的栈区,因此也叫做内核栈,每个进程在内核中都有自己的内核栈,因此我们可以看到一个进程其实有两个栈区,一个在用户态一个在内核态。
假设main函数调用funcA,funcA进行系统调用,调用内核中的funcB函数,funcB函数调用内核中的funcC函数,那么此时的内存布局就像这样:

好啦,这个话题就到这里,希望对大家理解操作系统有所帮助。
-
linux内核系统调用之参数传递2023-12-20 3073
-
如何查看及更改函数/函数块的调用环境2023-11-17 2612
-
python函数与函数之间的调用2023-10-04 1718
-
Linux内核中系统调用详解2023-08-23 1377
-
网络系统调用网络套接字入口函数2023-07-24 1322
-
SCL中调用函数的示例2023-06-06 4103
-
什么是函数的调用?2023-04-04 7713
-
C语言函数调用的形式及过程2023-03-10 2966
-
Linux中的系统调用是怎样实现2023-02-15 2084
-
详解python普通函数创建与调用2022-03-01 2647
-
如何确保在调用之间保留它的值?2020-03-31 1008
-
类成员函数与普通函数的区别研究2011-09-15 999
-
系统调用函数库分析及实例2011-06-23 804
-
C++教程之函数的递归调用2010-05-15 600
全部0条评论

快来发表一下你的评论吧 !
