

介绍一种信息抽取的大一统方法USM
描述
一句话总结
信息抽取任务具有多样的抽取目标和异构的结构,而传统的模型需要针对特定的任务进行任务设计和标签标注,这样非常的耗时耗力。本文提出一种USM方法,将各种信息抽取任务通过一种统一的模型方法完成。
USM
信息抽取(IE)的挑战在于标签模式的多样性和结构的异构性。
传统方法需要针对特定任务的模型设计,并且严重依赖昂贵的监督,因此很难推广到新模式。
在本文中,我们将 IE 分解为两种基本能力,「结构化」(Structuring)和「概念化」(Conceptualizing),它们由不同的任务和模式共享。
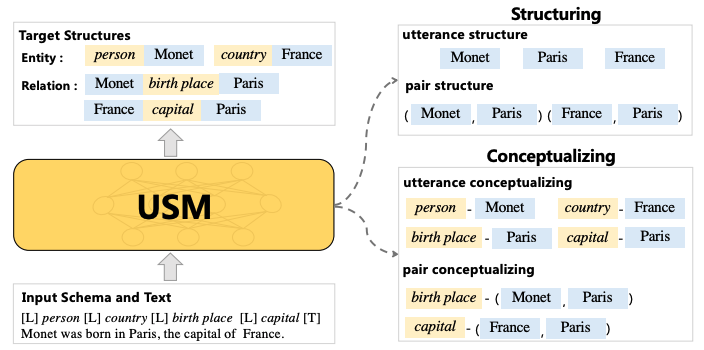
基于这种范式,我们建议使用「统一语义匹配 (Unified Semantic Matching, USM)」 框架对各种 IE 任务进行通用建模,该框架引入了三个统一的标记链接操作来建模结构化和概念化的能力。
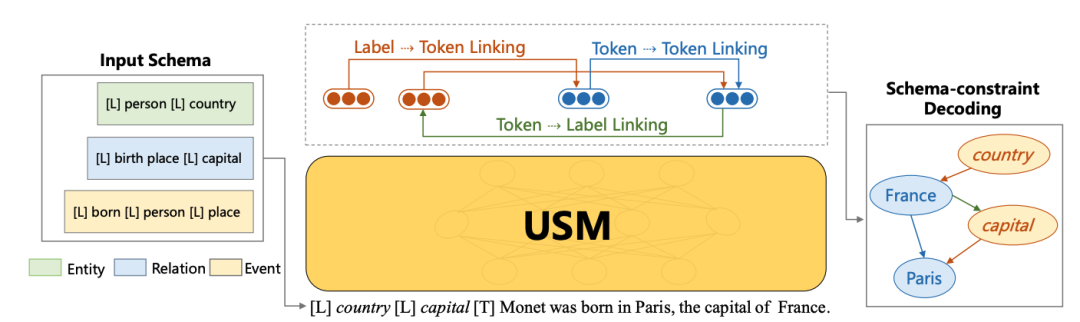
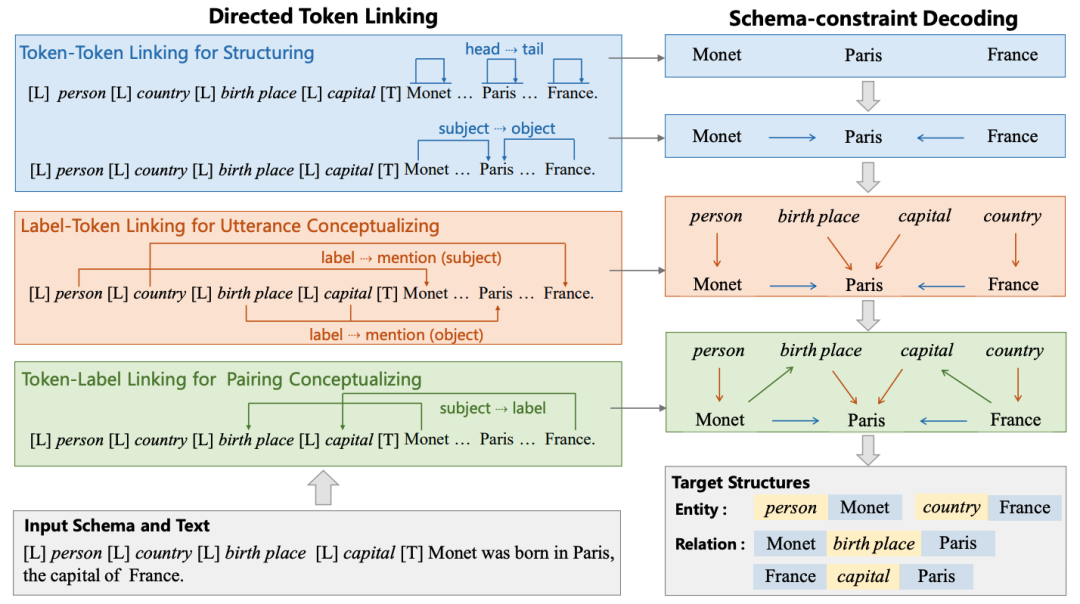
这样,USM 可以联合编码模式和输入文本,并行地统一提取子结构,并按需可控地解码目标结构。
本文的贡献为:
算法细节



实验分析
对 4 个 IE 任务的实证评估表明,所提出的方法在监督实验下实现了最先进的性能,并在零/少镜头传输设置中表现出强大的泛化能力。
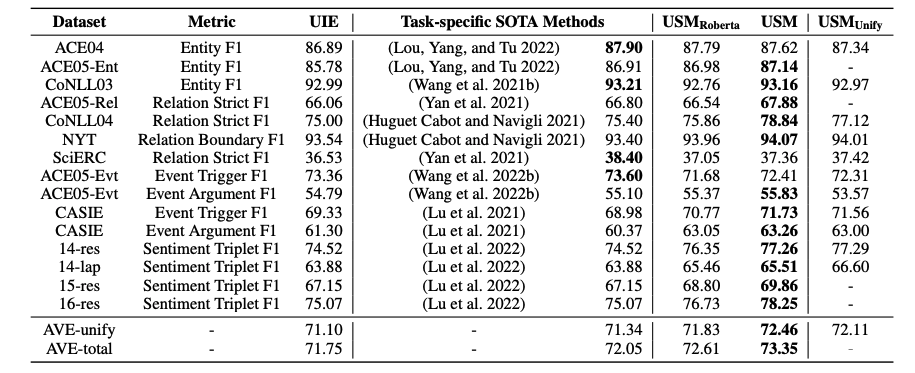
USM在不同数据集上的结果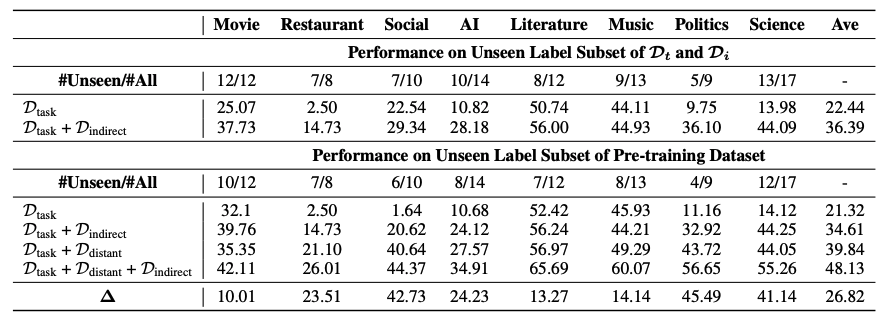
零样本迁移实验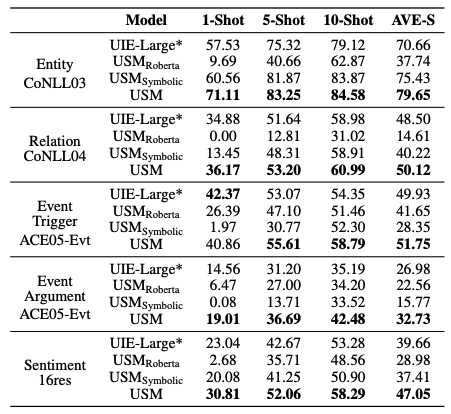
少样本实验
总结
在本文中,我们提出了一个统一的语义匹配框架——USM,它对提取模式和输入文本进行联合编码,并行地统一提取子结构,并按需可控地解码目标结构。
实验结果表明,USM 在监督实验下实现了最先进的性能,并在零/少场景设置下表现出强大的泛化能力,验证了 USM 是一种新颖、可传输、可控和高效的框架。
对于未来的工作,我们希望将 USM 扩展到 NLU 任务,例如文本分类,并研究 IE 的更多间接监督信号,例如文本蕴含。
审核编辑:刘清
-
请问一下VGA应用中硅器件注定要改变砷化镓一统的局面?2021-05-21 1316
-
PD快充协议有望一统吗?2021-11-30 4281
-
基于子树广度的Web信息抽取2009-03-28 465
-
文本分类中一种混合型特征降维方法2009-04-01 812
-
基于WebHarvest的健康领域Web信息抽取方法2017-12-26 927
-
苹果实现大一统:打通PC、平板、手机隔阂2020-11-11 1731
-
为应对苹果大一统,微软尽力让win10全力拥抱Android2020-11-30 1772
-
华为要最终实现其全场景、大一统的生态2021-01-13 2921
-
一个接口一统江湖!Intel雷电成功了2021-03-08 1320
-
一种面向维吾尔语的停用词抽取方法2021-05-25 821
-
一种全新易用的基于Word-Word关系的NER统一模型2022-03-23 3819
-
基于统一语义匹配的通用信息抽取框架USM2023-01-16 2211
-
学技术 | 充电器大一统:USB Type-C接口PD协议解决方案2022-11-21 5245
全部0条评论

快来发表一下你的评论吧 !
