

分布式存储的技术原理
电子说
描述
CAP定理: 在一个分布式计算机系统中,一致性,可用性和分区容错性这三种保证无法同时得到满足;
Consistency 一致性
Availability 可用性
Partition Tolerance 分区容错性
CAP取舍
CP:发生分区,需要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
AP:发生分区,为了高可用,每个节点只能用本地数据提供服务,会导致全局数据的不一致性。
理想情況下,单机数据库 AC 模型
分布式数据库系统 CP模型
单机数据库分布式解决方案:例如mysql
- 垂直拆分
- 水平拆分
- 读写分离
带来问题:
- 业务侵入大,维护成本高
- 带来分布式事务问题
分布数据库特性
- 存储量不受单机容量限制
- 计算能力不受单机资源限制
- 扩展性强
- 容错能力强
- 数据可靠性高
分布数据库设计思路
-
多副本的存储
保证数据一致性 一般KV存储模型 -
主从模型:
提供数据分片路由支持
多副本的存储方式
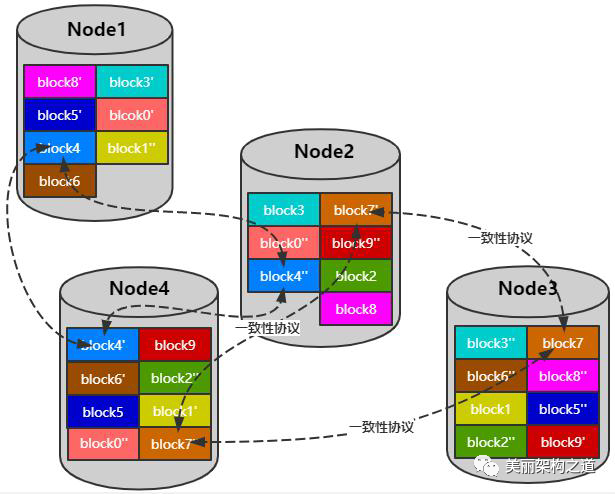
技术难点——热数据问题
- 热点数据
数据分快 热数据迁移
解决思路:实时调整块位置将读写频繁的块均匀分布在各个存储节点;
技术难点——原子性问题
- 保障多个Key写入的原子性
解决思路:一般都遵守Google Percolator分布式事务。(在这里不具体讲)
采取的乐观锁的方式,如图所示:

两阶段提交:Prewrite(预写)、commit(提交);并发冲突提交的问题。
如图所示:

RocksDB数据库存储原理
RocksDB:使用C++编写的嵌入式kv存储引擎,其键值均允许使用二进制流。由Facebook基于levelDB开发。
-
LSM的设计依据
随机写转换成顺序写
优化读性能
-
三种数据结构
MenTable
logfile
sstfiles
如下图:

RocksDB写入
- 插入
记录log MenTable写入新记录 - 更新
记录log MenTable写入新记录 - 删除
记录log MenTable标记key删除
WAL:write-ahead log,确保数据不丢失全部是内存写入,没有磁盘I/O
MenTable写满后写入磁盘,顺序I/O。
LSM读
-
读MemTable
-
定位sslFile,文件内查找


RocksDB首先会去查看内存中的Memtable,如果Memtable中包含key及其对应的value,则返回value值即可;如果在Memtable没有读到key,则接下来到同样处于内存中的Memtable中去读取,类似地,如果读到就返回,若是没有读到,那么会从磁盘中的SSTable文件中查找。
RocksDB为了提高读取速递,增加了读cache和Bloomfilter。
上面的分布式存储原理都理解了,那我们具体的tidb的架构原理就很简单了。
TiDB架构
- 基于RocksDB
- Raft一致性协议
- Etcd存储元数据
- 支持OLTA
- 支持OLAP

MySql迁移到TiDb:数据迁移和流量迁移
数据迁移:
1、支持主从同步的方式
2、双写(MQ)
流量迁移:
1、切读
2、停双写
如下图所示:

注意的事項:
乐观锁冲突的问题,使用分布式锁,串行化处理解决;
-
视频监控中分布式存储技术方案2011-03-10 5211
-
深度解读分布式存储技术之分布式剪枝系统2017-10-27 2349
-
什么是分布式存储技术?有哪些应用?2017-11-17 24665
-
分布式存储技术有哪些2019-01-04 17443
-
阿里巴巴如何使用分布式存储技术2019-05-21 2955
-
瞄上分布式存储技术 京东云投资EasyStack2019-06-11 835
-
分布式存储技术 从你说了算到大家说了算2019-06-12 1627
-
区块链技术的应用有望解决供应链金融的发展痛点2019-06-13 909
-
分布式存储技术之TurboEx超融合邮件系统2019-10-29 1596
-
分布式存储技术将引领着产业区块链的发展2019-10-30 1903
-
曙光中标分布式块存储产品集采 中国移动给大订单2020-07-02 716
-
主流分布式存储技术的对比分析与应用2020-07-13 4080
-
阿里巴巴探讨新基建下数字经济分布式存储新机遇2020-08-17 3780
-
一文知道分布式存储技术的发展历程2020-09-30 4391
-
主流分布式存储技术对比分析2023-02-15 2744
全部0条评论

快来发表一下你的评论吧 !
