

剖析MySQL InnoDB存储原理(下)
电子说
描述
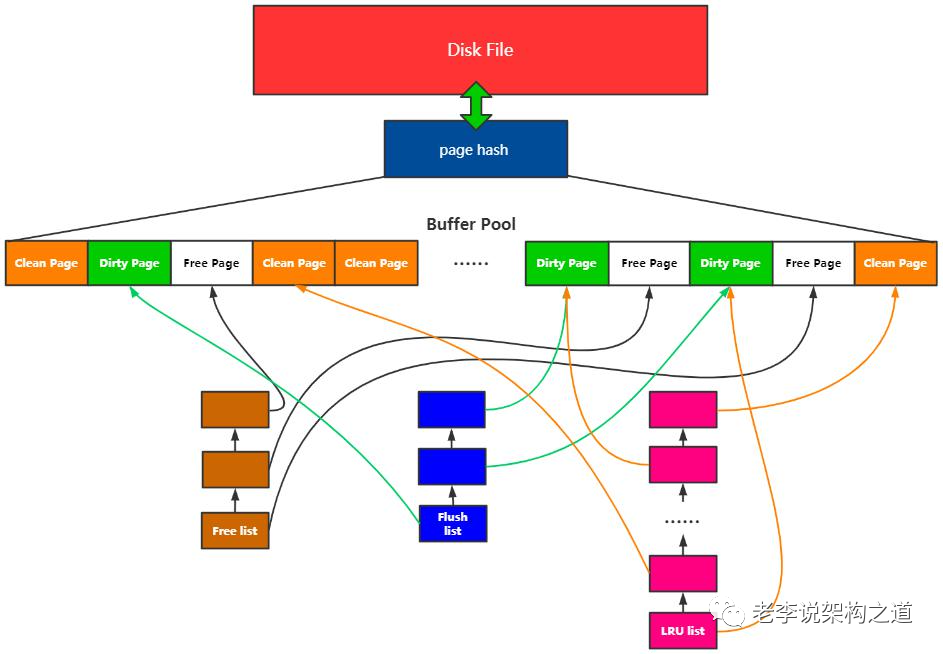
一、InnoDB存储引擎内存管理
1.1 概念:
Buffer Pool:预分配的内存池;
Page:Buffer Pool的最小单位;
Free list:空闲Page组成的链表;
Flush list:脏页链表;
Page hash 表:维护内存Page和文件Page的映射关系;
这几个概念关系,如图所示:
1.2 内存的淘汰算法:LRU
分为三部分:LRU_new、LRU_old、MidPoint。如下图所描述:

1.2.1 页面装载的逻辑如图:

数据从磁盘到内存 > Free list中取 > LRU中淘汰 > LRU Flush
1.2.2 页面淘汰
LRU链表中将第一个脏页刷盘并“释放”,放到Free list中。
1.2.3 位置移动

innodb_old_blocks_time old区存活时间,大于此值,有机会进入new区
Midpoint:指向5/8位置
为了减少移动到次数和lock,思路访问时间 + 频率,避免热数据被移除,通过如下:freed_page_clock:Buffer Pool淘汰页数
移动时机:
当前freed_page_clock - 上次移动到Header时freed_page_clock >LRU_new长度1/4
2、MySQL事务管理机制原理分析
1、基本概念:
1.1 事务特性:
A(Atomicity原子性):全部成功或全部失败
I(Isolation隔离性):并行事务之间互不干扰
D(Durability持久性):事务提交后,永久生效
C(Consistency一致性):通过AID保证
1.2 并发问题:
脏读(Drity Read):读取到未提交的数据
不可重复读(Non-repeatable read):两次读取结果不同
幻读(Phantom Read):select 操作得到的结果所表征的数据状态无法支撑后续的业务操作
1.3 隔离级别
Read Uncommitted(读取未提交内容):最低隔离级别,会读取到其他事务未提交的数据,脏读;
Read Committed(读取提交内容):事务过程中可以读取到其他事务已提交的数据,不可重复读;
Repeatable Read(可重复读):每次读取相同结果集,不管其他事务是否提交,幻读;
Serializable(串行化):事务排队,隔离级别最高,性能最差;
2、事务实现原理
2.1 MVCC
Read View:活跃事务列表(还未提交的事务) 列表中最小事务ID(提交),列表中最大事务ID(未提交);具体可见性通过如下流程图所示:

2.2 MVCC如何实现
undo log:实现数据多版本,回滚,提交即清理;

redo log:实现事务持久性,记录修改,用于异常恢复,循环写文件;
Write Pos:写入位置
Chick Point:刷盘位置
Chick Point -> Write Pos:待落盘数据
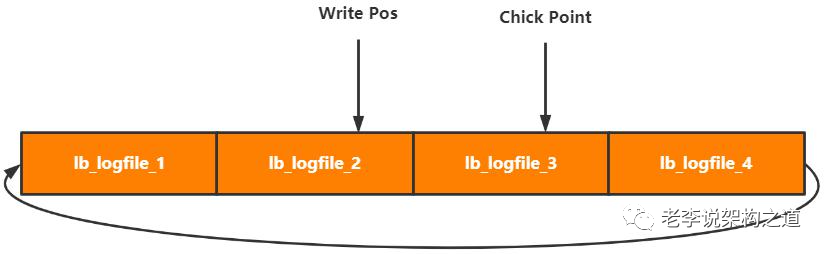
写入流程:

刷盘时机:
innodb_flush_log_at_trx_commit

3、MySQL使用及调优实践分析
3.1 索引使用技巧
联合索引:优于多列独立索引
索引顺序:选择性高的在前面
覆盖索引:二级索引存储主键值更有利
索引排序:索引同时满足查询和排序
3.2 分库分表
是否分表,建议单表不超过1KW
分表方式,取模:存储均匀&访问均匀,按时间:冷热库
分库,按业务垂直分,水平查分多个库
3.3 使用建议
数据库字符集使用utf8mb4;
VARCHAR按实际需要分配长度;
文本字段建议使用VARCHAR;
时间字段建议使用long;
bool字段建议使用tinyint;
枚举字段建议使用tinyint;
交易金额建议使用long;
禁止使用“%”前导的查询;
禁止在索引列进行数学运算,会导致索引失效;
select * from t1 where id+1 >1121 不会使用索引
select * from t1 where id >1121 - 1 会使用索引
表必须有主键,建议使用业务主键;
单张表中索引数量不超过5个;
单个索引字段数不超过5个;
字符串索引使用前缀索引,前缀长度不超过10个字符;
-
深度剖析MySQL/InnoDB的并发控制和加锁技术2020-10-29 2831
-
详解Mysql数据库InnoDB存储引擎事务2019-05-13 1063
-
InnoDB锁的特点和状态查询2019-08-07 1754
-
分布式MySQL的InnoDB cluster2020-04-15 1622
-
MySQL存储引擎简析2021-09-06 2322
-
MySQL存储引擎中MyISAM与InnoDB优劣势比较分析2018-07-18 3212
-
关于mysql存储引擎你知道多少2019-08-23 1153
-
最有用的mysql问答2020-09-30 2363
-
关于InnoDB的内存结构及原理详解2021-04-16 3654
-
MySQL中的redo log是什么2021-09-14 2744
-
innodb究竟是如何存数据的2021-10-09 1907
-
MySQL5.6 InnoDB支持全文检索2022-11-12 2248
-
剖析MySQL InnoDB存储原理(上)2023-02-15 923
-
MySQL中的InnoDB是什么?2023-04-13 1663
-
Mysql数据恢复—Windows Server下MySQL(InnoDB)全表误删数据恢复案例2025-09-23 871
全部0条评论

快来发表一下你的评论吧 !
