

python3.6-3.10新特性介绍
电子说
描述
(一)首先是第一个f格式化字符串,之前基础篇讲过,我们可以通过f和{}来作为格式化字符串的占位符,比如:

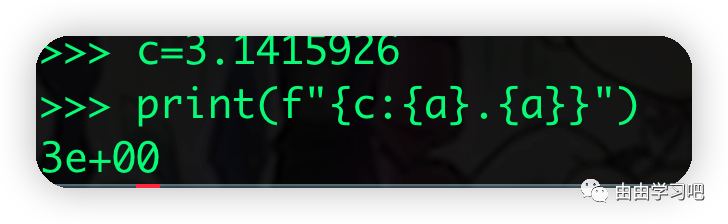
或者使用占位符描述长度和保留位数,比如:
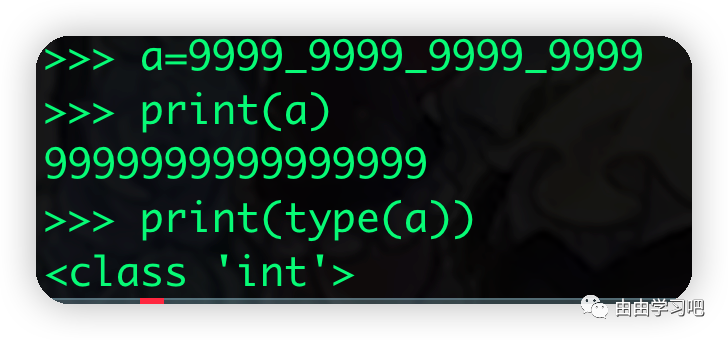
(二)然后是数字下划线,数字使用下划线可以方便阅读,不影响原有类型,比如:
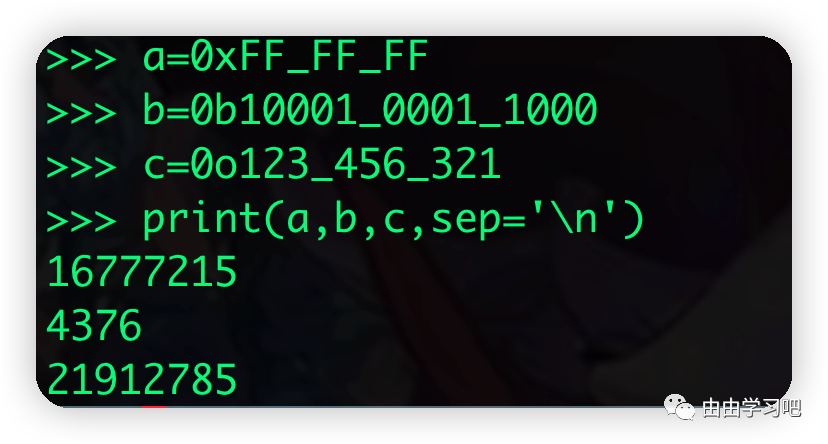
对于16进制,8进制,二进制也是可以的
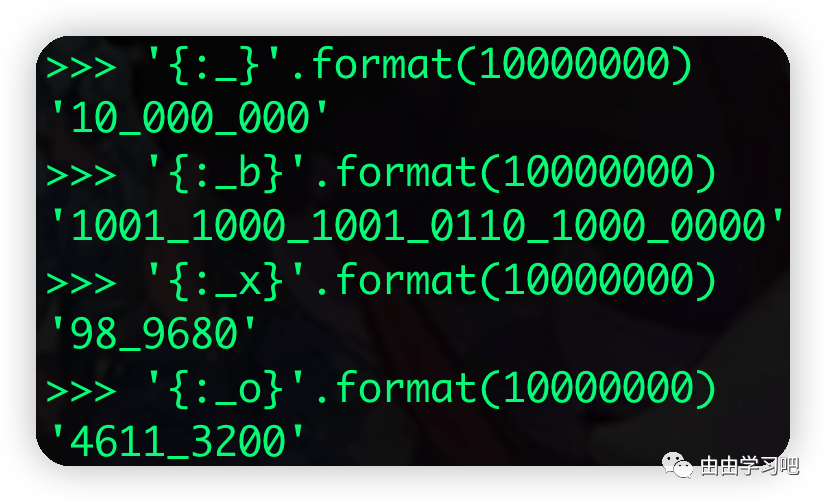
字符串format方法也支持了“_”的选项,当格式化为浮点数或整数时,以3位分隔,当格式化为二进制,八进制,十六进制时,以4位分隔
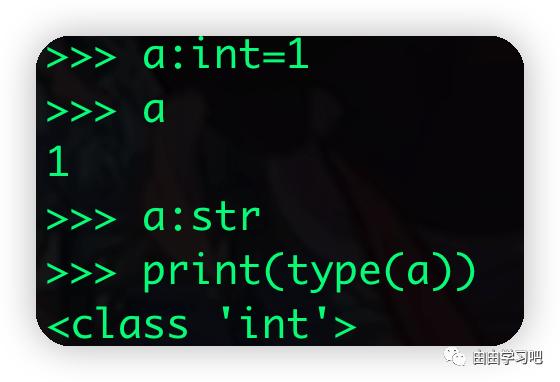
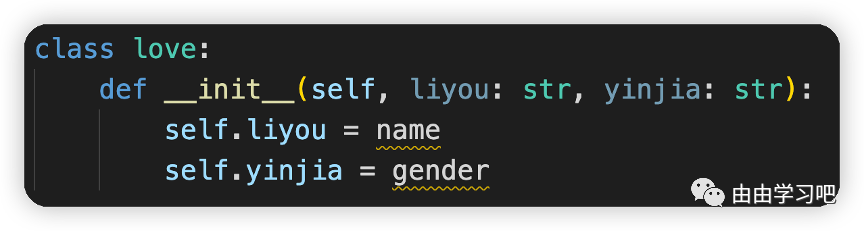
(三)变量注释没有给变量带来特殊的意义,只是为了方便IDE做类型检查
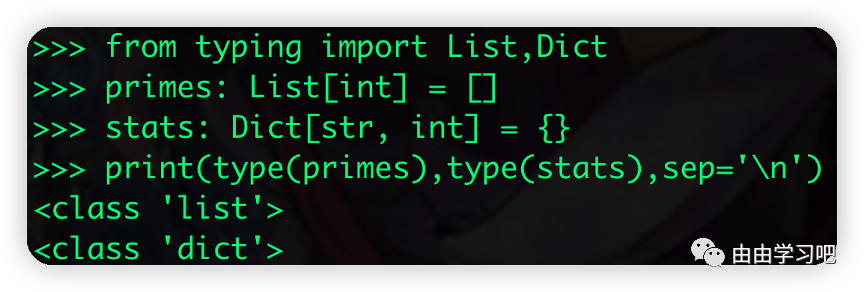
只是起注释作用,实际意义不大
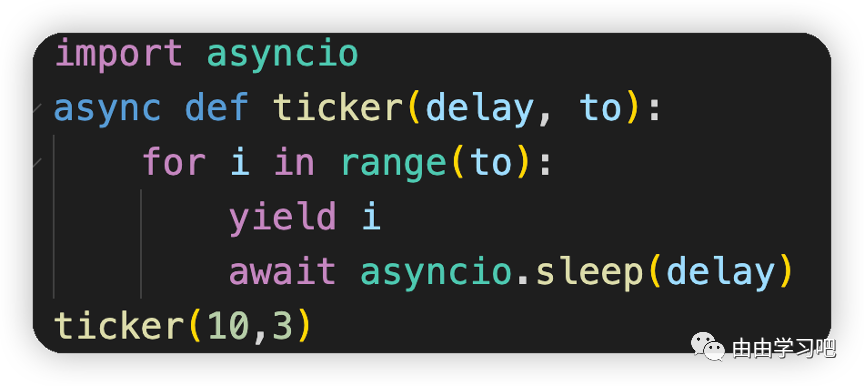
(四)异步生成器在Python3.5中,协程函数await和yield不能再同一个函数中使用,但是Python3.6已经取消了这个限制,可以在同一个函数体中使用了
1.await是一个关键字,只能在协程函数中使用,在遇到IO操作时暂停当前协程(任务)。
2、在暂停当前协程(任务)的过程中,事件循环可以执行其他协程(任务),在当前协程的IO处理完成后,可以再次切换执行的代码。
使用方法
await + 可等待对象(协程对象、Future对象、Task对象)
例如:
import asyncio
async def func():
print("执行协程函数内部代码")
# 遇到IO操作挂起当前协程(任务),等IO操作完成之后再继续往下执行。
# 当前协程挂起时,事件循环可以去执行其他协程(任务)。
response = await asyncio.sleep(2)
print("IO请求结束,结果为:", response)
result = func()
asyncio.run(result)
现在生成器和协程函数可以共用了,比如:
(五)增加在list、set和dict的列表推导和生成表达式中使用async for,async/await 是python3的新特性,可以进行协程运行。个人将他理解成多线程
使用异步推导式之后,可以简写成
result = [i async for i in liyou() if i % 3]
现在也支持在所有的推导式中使用await表达式
result = [await liyou() for liyou in liyous]
(六)增加了一个新的模块:secrets。该模块用来生成一些安全性更高的随机数,用于管理passwords, account authentication, security tokens, 以及related secrets等数据,因为python(大部分解析器是cpython,底层随机化是随机数,可以通过种子判断出随机规律,使用secrets解决了这个问题,使得安全性得到了提高)。
(七)其他
新的堆内存分配环境变量允许开发者设置内存分配器,以及注册debug钩子等。
asyncio模块更加稳定、高效,并且不再是临时模块,其中的API也都是稳定版的了。
typing模块也有了一定改进,并且不再是临时模块。
datetime.strftime 和 date.strftime 开始支持ISO 8601的时间标识符%G, %u, %V。
hashlib 和 ssl 模块开始支持OpenSSL1.1.0。
hashlib模块开始支持新的hash算法,比如BLAKE2, SHA-3 和 SHAKE。
Windows上的 filesystem 和 console 默认编码改为UTF-8。
json模块中的 json.load() 和 json.loads() 函数开始支持 binary 类型输入。
Python3.7
1、内置函数breakpoint()
2、类型和注解
3、新增dataclasses模块
4、生成器异常处理
5、开发模式
6、高精度时间函数
7、新特性
(一)使用breakpoint()可以方便我们使用pdb调试python代码,在 pdb 提示符下,我们可以调用 locals() 来查看当前的本地作用域的所有变量,找到问题所在地方。
(二)类型和注解,和变量注释差不多,方便描述,比如:

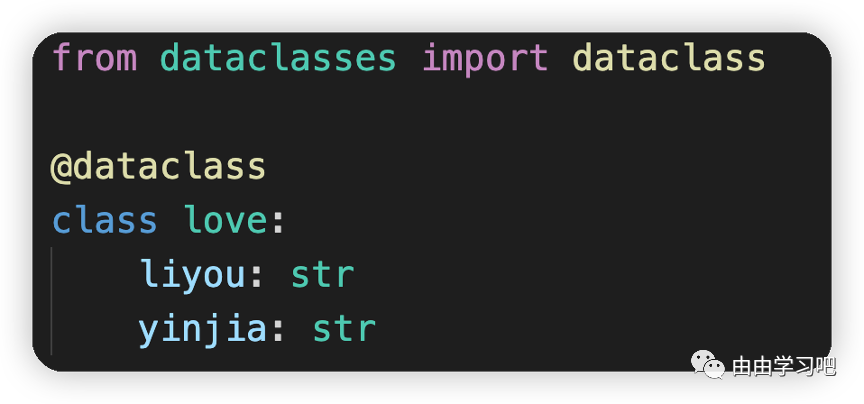
(三)引入了一个新的模块dataclasses,该模块主要提供了一种数据类的实现方式。
优点是:
1. 无需定义__init__,然后将值赋给self,dataclass负责处理它
2. 我们以更加易读的方式预先定义了成员属性,以及类型提示。我们现在立即能知道number是int类型。这无疑比一般定义类成员的方式更具可读性。
比如:
在数据类被定义后,会根据给出的类型注解生成一个如下的初始函数:
是不是很方便,节约了大量时间了
(四)生成器引发StopIteration异常后,StopIteration异常转换RuntimeError异常,它不会影响应用程序的堆栈框架。
(五)Python解释器命令行添加了开发者模式,参数是-X,他激活的内容有asyncio的调试模式。为异步操作提供更详细的日志记录和异常处理。以及面向内存分配器的调试hook。这对于编写CPython扩展件的那些人很有用。它能够实现更明确的运行时检查,了解CPython如何在内部分配内存和释放内存。启用faulthandler模块,那样发生崩溃后,traceback始终转储出去。
(六)新的时间函数使用后缀_ns。比如,time.process_time()的纳秒版本是time.process_time_ns()
(七)其他
字典现在保持插入顺序。这在 3.6 中是非正式的,但现在成为了官方语言规范。在大多数情况下,普通的 dict 能够替换 collections.OrderedDict。
.pyc 文件具有确定性,支持可重复构建 —— 也就是说,总是为相同的输入文件生成相同的 byte-for-byte 输出。
新增contextvars模块,针对异步任务提供上下文变量。
__main__中的代码会显示弃用警告(DeprecationWarning)。
新增UTF-8模式。在Linux/Unix系统,将忽略系统的locale,使用UTF-8作为默认编码。在非Linux/Unix系统,需要使用-X utf8选项启用UTF-8模式。
允许模块定义__getattr__、__dir__函数,为弃用警告、延迟import子模块等提供便利。
新的线程本地存储C语言API。
更新Unicode数据到11.0。
Python3.8
1、海象赋值表达式
2、仅限位置形参
3、f格式化字符串支持 =
4、 typing模块的改进
5、多进程共享内存
6、 新版本的pickle协议
7、 性能改进
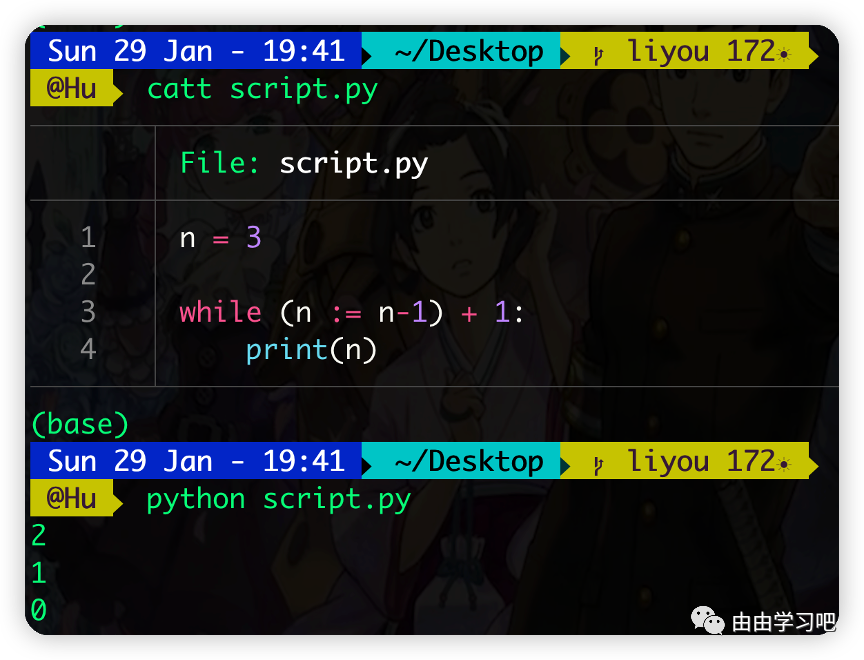
(一)新的语法:= (有点碰瓷go语言,哈哈,不过用法不太一样)他会先进行赋值,然后再进行比较,这样比较方便,避免了两次循环了,比如:
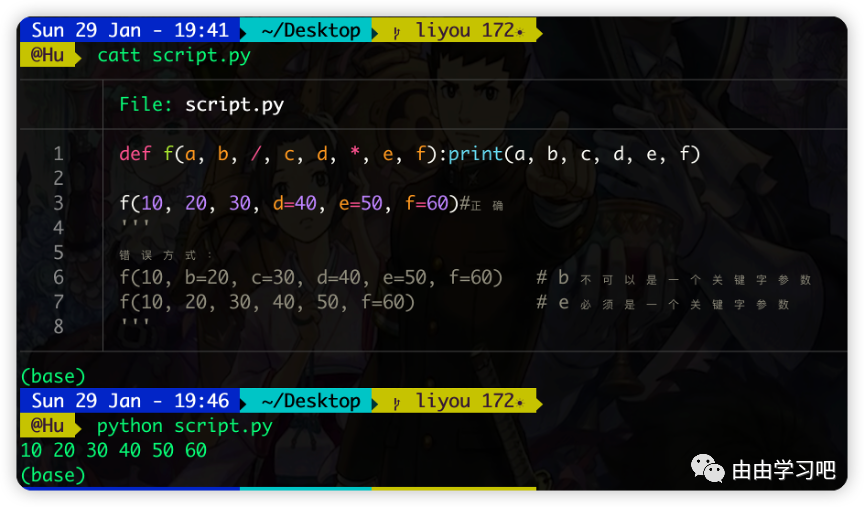
(二)新增一个函数形参语法/ 用来指明某些函数形参必须使用仅限位置而非关键字参数的形式,比如:
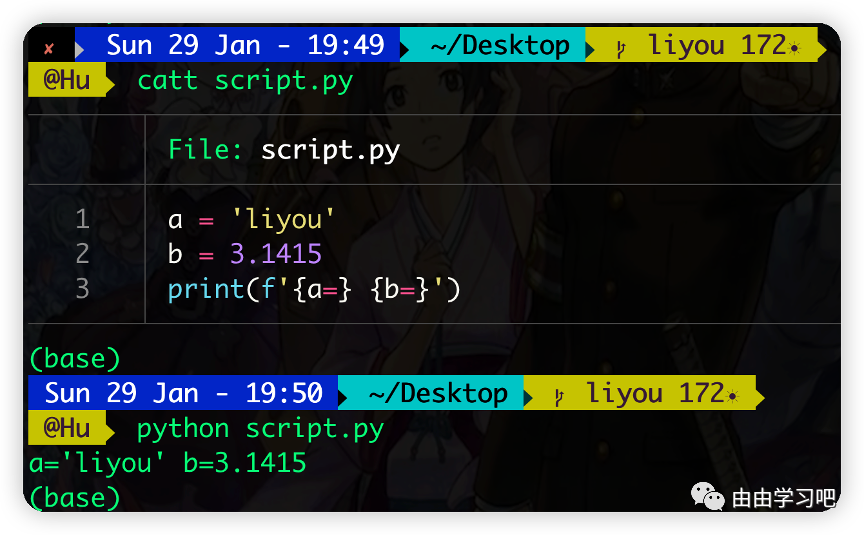
(三)f的格式化字符串可以使用等号=,比如:
(四)Python 3.8给typing添加了一些新元素,因此它能够支持更健壮的检查:
1、final修饰器和Final类型标注表明,被修饰或被标注的对象在任何时候都不应该被重写、继承,也不能被重新赋值。
2、Literal类型将表达式限定为特定的值或值的列表。
3、TypedDict可以用来创建字典,其特定键的值被限制在一个或多个类型上。注意这些限制仅用于编译时确定值的合法性,而不能在运行时进行限制。
(五)multiprocessing模块新增SharedMemory类,可以在不同的Python进城之间创建共享的内存区域。
1、在旧版本的Python中,进程间共享数据只能通过写入文件、通过网络套接字发送,或采用Python的pickle模块进行序列化等方式。共享内存提供了进程间传递数据的更快的方式,从而使得Python的多处理器和多内核编程更有效率。
2、共享内存片段可以作为单纯的字节区域来分配,也可以作为不可修改的类似于列表的对象来分配,其中能保存数字类型、字符串、字节对象、None对象等一小部分Python对象。
(六)Python的pickle模块提供了一种序列化和反序列化Python数据结构或实例的方法,可以将字典原样保存下来供以后读取。不同版本的Python支持的pickle协议不同,而3.8版本的支持范围更广、更强大、更有效的序列化。Python 3.8引入的第5版pickle协议可以用一种新方法pickle对象,它能支持Python的缓冲区协议,如bytes、memoryviews或Numpy array等。新的pickle避免了许多在pickle这些对象时的内存复制操作。NumPy、Apache Arrow等外部库在各自的Python绑定中支持新的pickle协议。新的pickle也可以作为Python 3.6和3.7的插件使用,可以从PyPI上安装。
(七)许多内置方法和函数的速度都提高了20%~50%,因为之前许多函数都需要进行不必要的参数转换。
1、一个新的opcode缓存可以提高解释器中特定指令的速度。但是,目前实现了速度改进的只有LOAD_GLOBAL opcode,其速度提高了40%。以后的版本中也会进行类似的优化。
2、文件复制操作如shutil.copyfile()和shutil.copytree()现在使用平台特定的调用和其他优化措施,来提高操作速度。
3、新创建的列表现在平均比以前小了12%,这要归功于列表构造函数如果能提前知道列表长度的情况下,可以进行优化。
4、Python 3.8中向新型类(如class A(object))的类变量中的写入操作变得更快。operator.itemgetter()和collections.namedtuple()也得到了速度优化。
Python3.9
1、字典并集和可迭代更新
2、字符串方法
3、类型提示
4、新的数学函数
5、新的解析器
6、IPv6范围内的地址
7、新模块:区域信息
8、其他语言更改
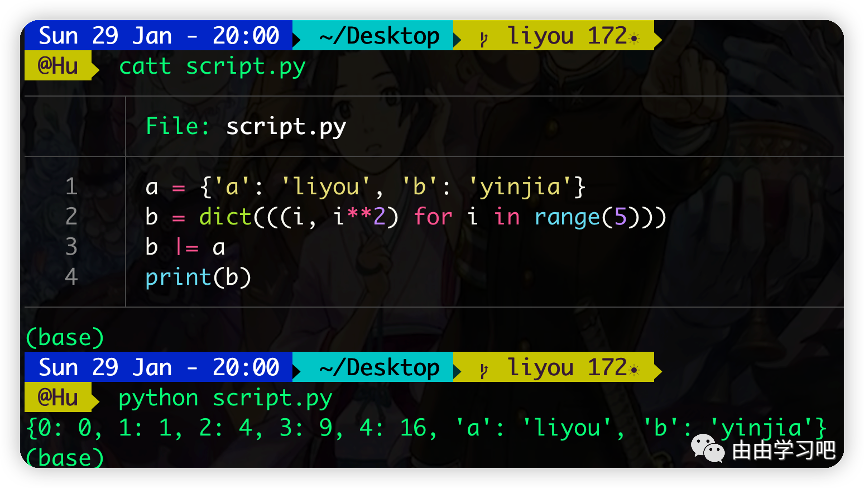
(一)加入了合并运算符|(也就是管道符的那个键),可以使用这些运算符进行合并和更新,比如:
(二)removeprefix()和removesuffix()
str.removeprefix(substring:string)字符串方法:如果str以它开头的话,将会返回一个修改过前缀的新字符串,否则它将返回原始字符串。
str.removesuffix(substring:string)字符串方法:如果str以其结尾,则返回带有修改过后缀的新字符串,否则它将返回原始字符串。
(三)无需从typing.List来调用List,内置集合类型(List和Dict)用作泛型类型,比如:
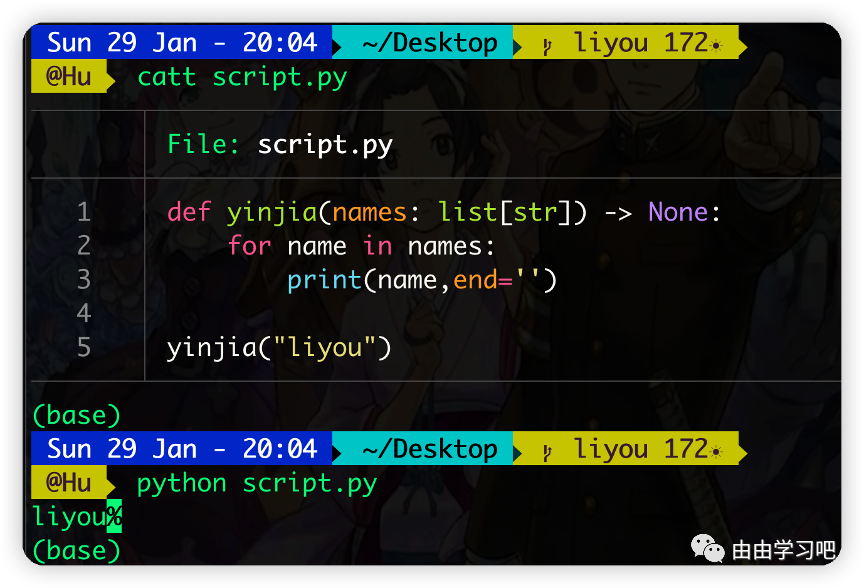
->为函数添加元数据,描述函数的返回类型,从而方便开发人员使用,这里表示函数无返回值
(四)math模块中第一个新添加的是math.lcm函数:
math.lcm(4, 8, 5)
math.lcm计算其参数的最小公倍数。与GCD一样,它允许可变数量的参数。
(五)Python 3.9使用了一个新的基于PEG的解析器(在使用pyinstaller静态编译的时候本机可用,但是经常在低版本系统:win7等会提示缺少动态库的问题,丢失dll文件)
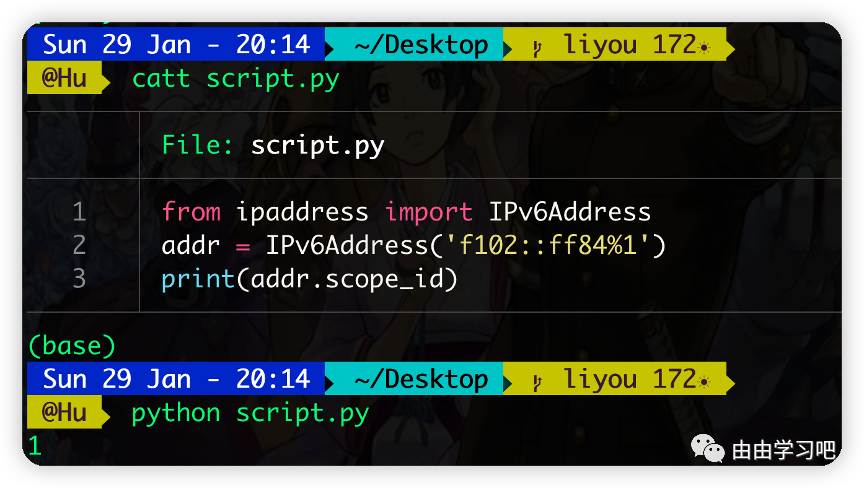
(六)可以指定IPv6地址的范围,比如:
(七)zoneinfo模块将IANA时区数据库的支持引入标准库。它添加了zoneinfo.ZoneInfo,这是一个由系统时区数据支持的具体的datetime.tzinfo实现。
(八)引入了几个新的内置函数,包括range、tuple、set、frozenset、list、dict ——使用vectorcall可以加快执行速度。__import __()现在增加了ImportError以替代ValueError,通常在相对导入超出其顶级包时发生。“”.replace(“”,s,n)现在对于所有非零n返回s而不是空字符串。现在它与““ .replace(”“,s)相一致。
Python3.10
1、类型检查改进
2、类型别名更改
3、二进制表示中的频率为1的数量统计
4、准备弃用Distutils内置库
5、字典增加mapping属性
6、函数zip()增加strict参数
7、模板匹配
8、支持 switch语法
(一)Python3.10版本中,联合运算符使用"|"线来代替了旧版本中的Union[]方法,使得程序更加简洁,不仅如此, Python3.10在一些内置函数中,同样可以利用"|"线的联合运算符来提升程序的性能
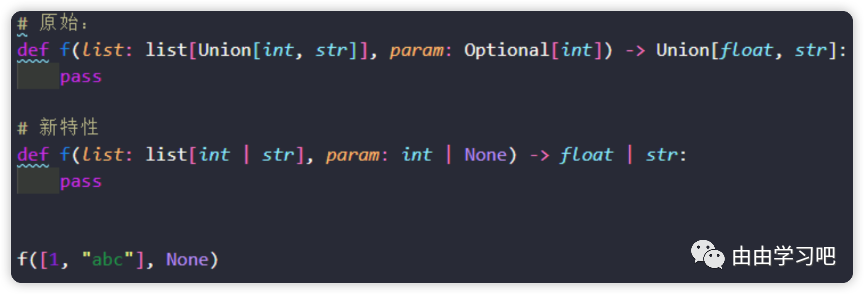
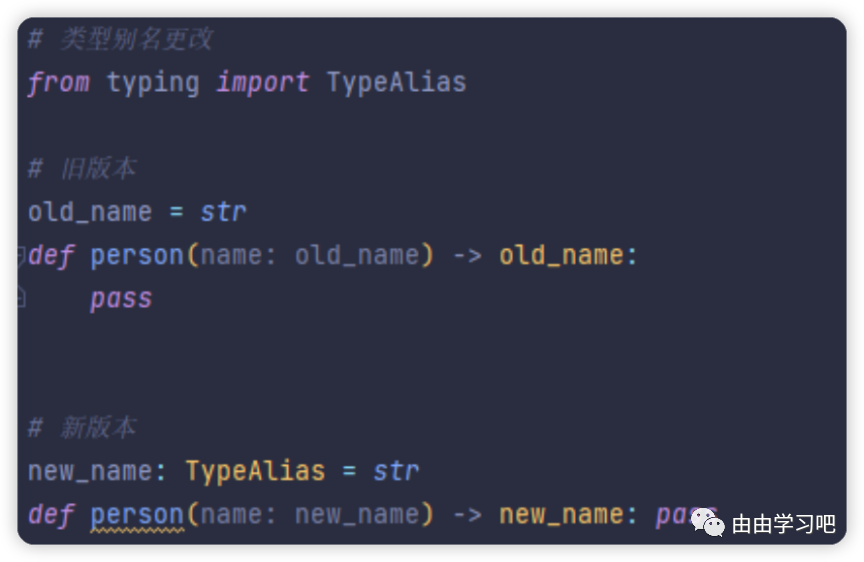
(二)Python3.10版本中,则通过 TypeAlias 来规定了类型名字的替换。这样操作的优势在于能够让程序开发人员和Python编辑器更加清楚的知道newname是一个变量名还是一个类型的别名,提升程序开发的可靠性。
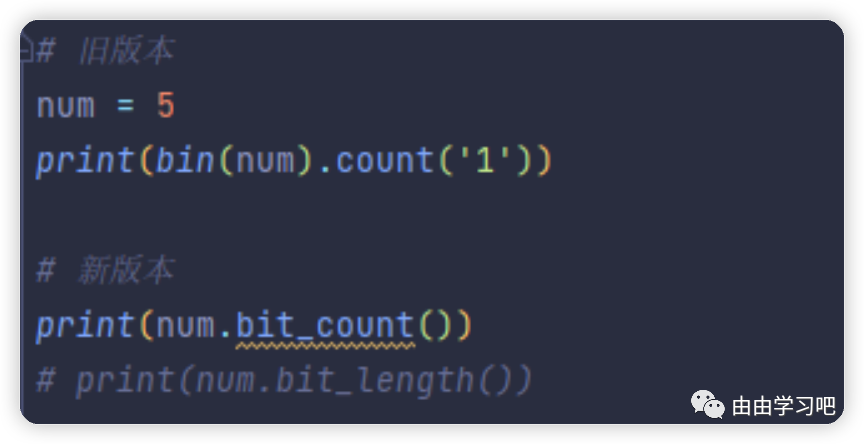
(三)在Python3.10版本中,可以通过调用bit_count函数来统计二进制中数字“1"的个数,当然,在旧版本中,也可以通过很简单的代码实现这个功能。
(四)由于Distutils库的功能已经被此setuptools和package库取代了,所以本着简洁性的原则,Distutils在不久的将来将会被完全的删除掉。
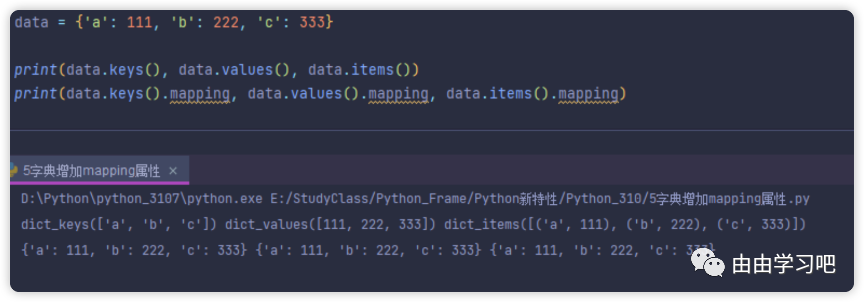
(五)在Python3.10中,针对于字典的三个方法,items, keys和values都增加了一个新的"mapping"属性,通过下述的程序可以发现,对三个方法调用mapping属性后都会返回原字曲数据。
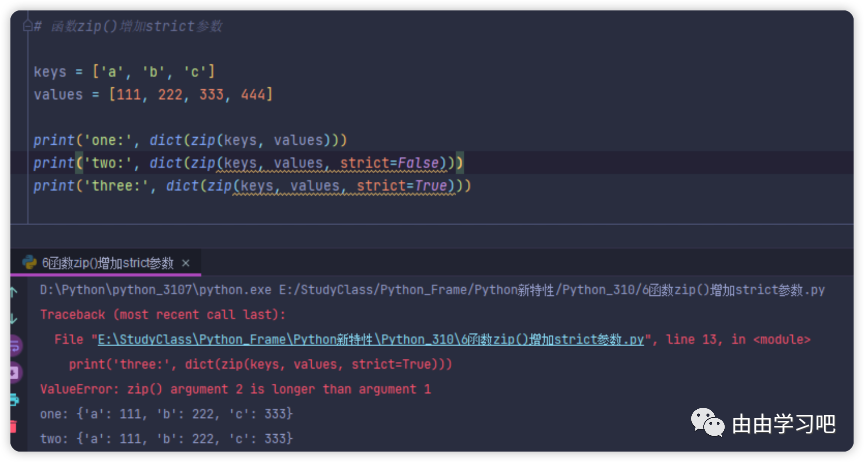
(六)Python3.10中对于zip函数添加了strict参数, 顾名思义,strict参数就是要严格的遵守参数长度的匹配原则,下述程序中,keys和values列表的长度并不一致。旧版本的zip函数会根据长度最短的参数来创建字典。新版本的zip函数中, 当设定strict参数设置为True时, 则要求zip的输入参数必须要长度一致,否则就合报错。
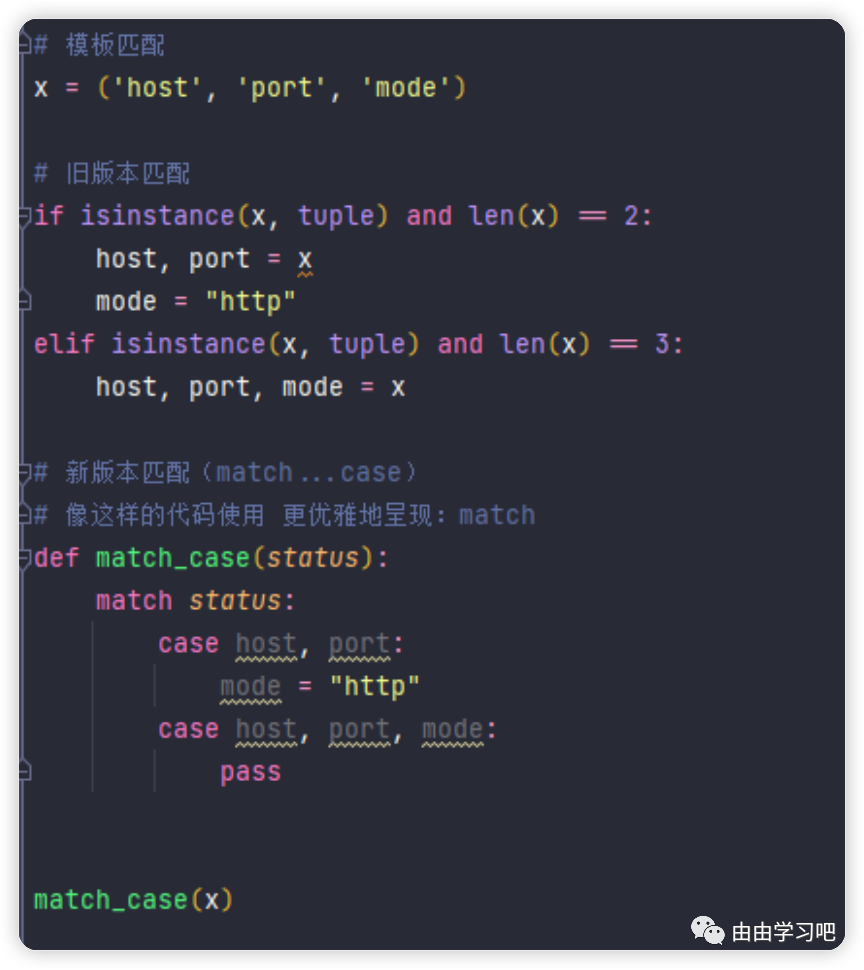
(七)Python 3.10引入了结构化的模式匹配,通过match...case关键词来完成,可以匹配字典,类以及其他更复杂的结构。match...case的模式匹配,在使用的方式上与C++中的switch有很多的相似之处。
(八)switch语句
由 match 关键词和 case 语句组成。通用语法如下:
match subject:
case
case
case _:
(九)优化了报错模式,对排查错误的时候更加准确定位
审核编辑:刘清
-
Python3.10.0的特性介绍2023-10-31 1062
-
zip():Python 中最好用的内置类型之一2023-10-30 3994
-
使用Python3.10安装Openvino-Dev Pip包失败了是为什么?2023-08-15 499
-
【芒果派MangoPi MQ Pro】+ 失败的Python 3尝试2023-07-28 563
-
Python常用的几个命令介绍2023-06-21 3107
-
介绍Python中文件创建与写入的基本方法2023-04-27 3903
-
鲁班猫0 安装python-pip2023-04-06 973
-
介绍python列表的边界和嵌套2023-02-27 1500
-
IPython的特性介绍及使用技巧2022-10-14 1956
-
Python语言介绍及开发环境2021-04-26 754
-
四个有趣的关于Python 3.9版本新特性2020-10-08 3578
-
使用Python操作excel表格的xlrd介绍2020-07-02 813
-
Python3.6零基础入门与实战PDF电子书免费下载2019-09-19 4471
-
让Python输出更整洁:PrettyPrinter2018-03-17 7960
全部0条评论

快来发表一下你的评论吧 !
