

德州仪器TDA4背后的OpenVX介绍
描述
近年来行泊一体大行其道,德州仪器的TDA4占了行泊一体大约70%的市场。其背后关键的就是OpenVX。
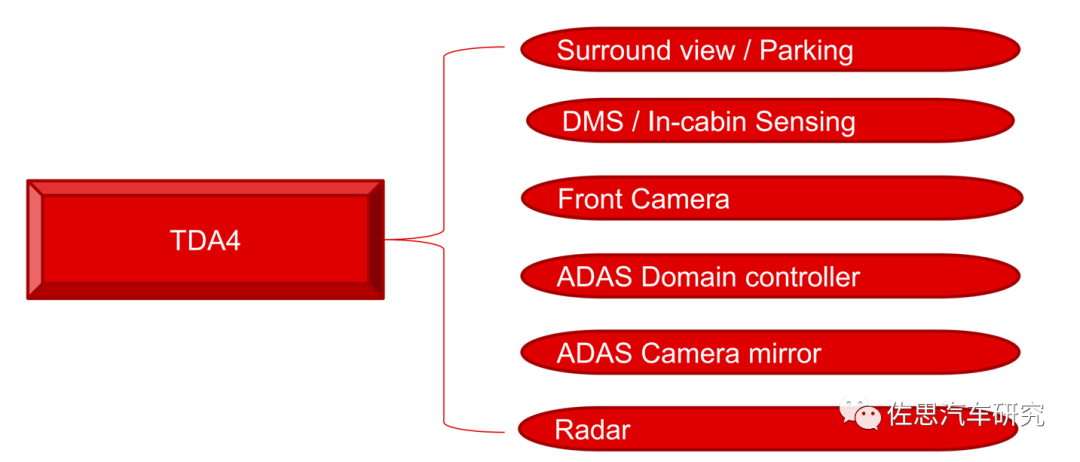
图片来源:德州仪器
TDA4是一个庞大的家族,可以对应六大场景,如上图。TDA4系列产品众多,TDA4VM是最早推出的,性能最低,2023年2季度量产的TDA4VH和TDA4AH是TDA4系列的旗舰产品,具备32TOPS的AI算力(4个MMA),100K DMIPS的CPU算力(8个2.0GHz的Cortex-A72内核),16K DMIPS的MCU算力(8个Cortex-R5F内核),320 GFLOPS的DSP算力(4个C7X),4个4K60显示,内置4口以太网交换,2口PCIe交换。
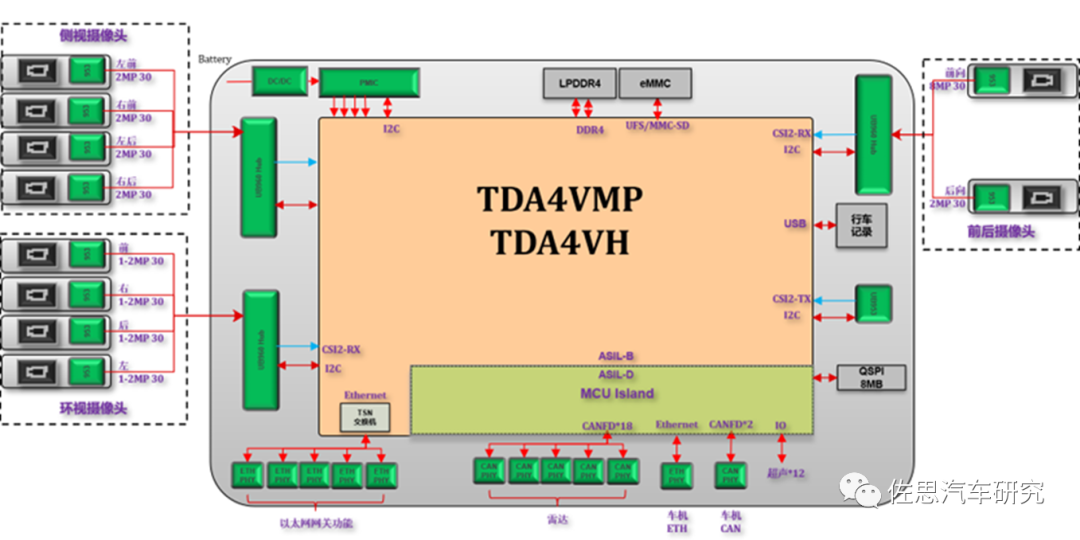
图片来源:德州仪器
这是典型的行泊一体框架图,10个摄像头,对TDA4VMP来说太吃力,还是需要TDA4VH。行车方面,可实现盲区检测(BSD)、开门预警(DOW)、车道偏离预警(LDW)、前向碰撞预警(FCW)、智能远光灯控制(IHC)、前方穿行预警(FCTA)、后方穿行预警(RCTA)、后方碰撞预警(RCW)、自适应巡航(ACC)、车道保持辅助 (LKA)、手动变道(PLC)、交通拥堵辅助(TJA)、高速辅助驾驶(HWA)、自动紧急制动(AEB)、交互式高速公路自动驾驶(HWP)、交互式高速公路拥堵自动驾驶(TJP)、自动辅助导航驾驶(NOA)等功能;泊车方面,可实现全景功能(AVM)、自动泊车辅助(APA)、遥控泊车辅助(RPA)、家庭区域记忆泊车(HAVP)等功能。
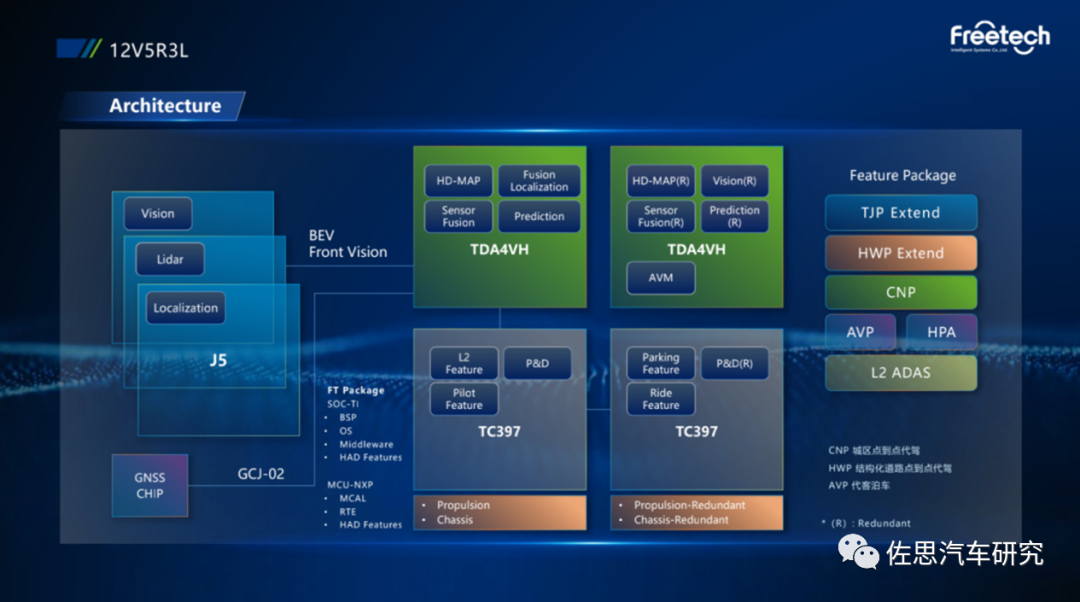
图片来源:福瑞泰克
这是福瑞泰克最顶级的ADC30域控制器架构,12V5R3L方案,基于3颗地平线征程5芯片、2颗TDA4VH以及2颗英飞凌TC397的架构。3颗征程5芯片主要做BEV鸟瞰图。高精度地图处理、传感器融合、轨迹预测、行为决策、路径规划和自动泊车由TDA4VH负责。据说一汽红旗将使用这个域控制器。一汽红旗是福瑞泰克的大客户。
TDA4VM内部框架图
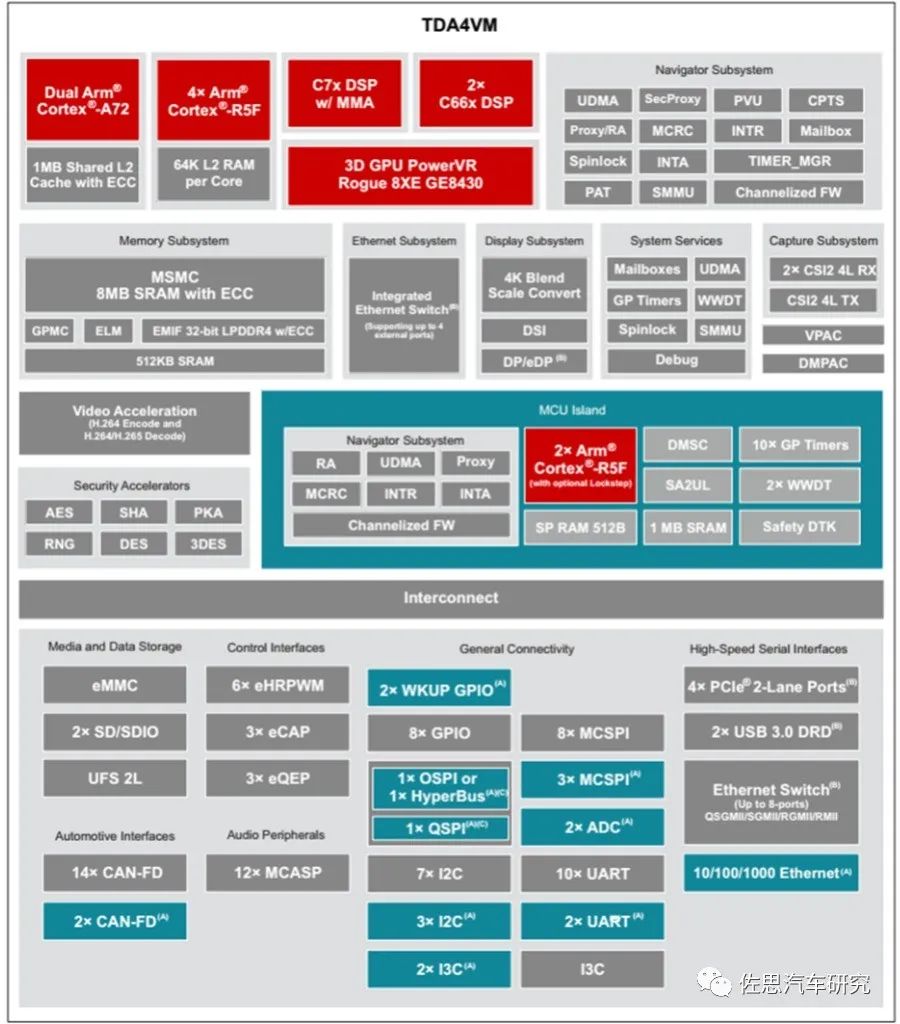
图片来源:德州仪器
TDA4VMID的应用框架图
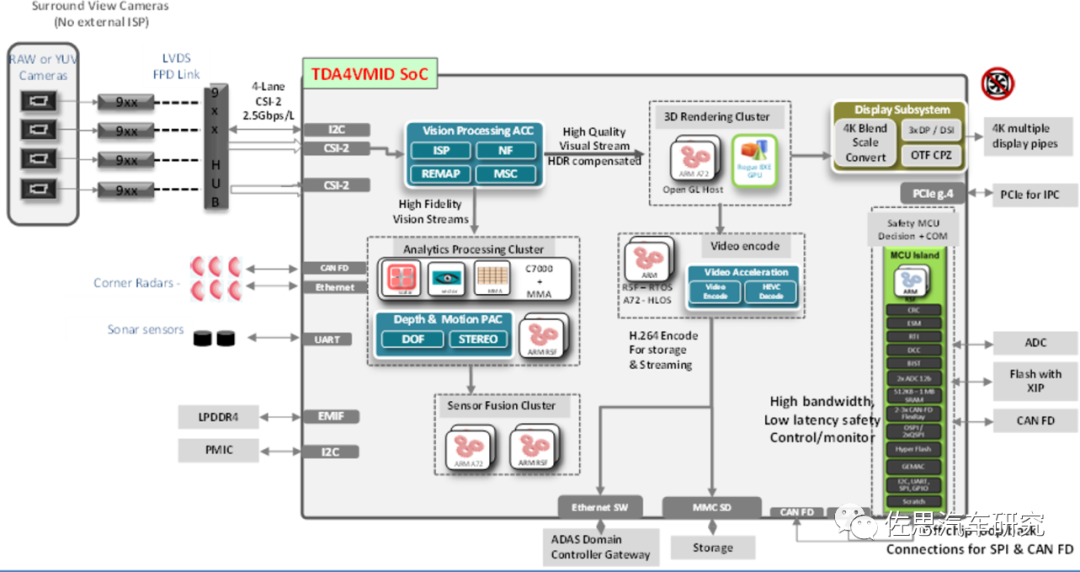
图片来源:德州仪器
TDA4VMID自动泊车的数据流分析
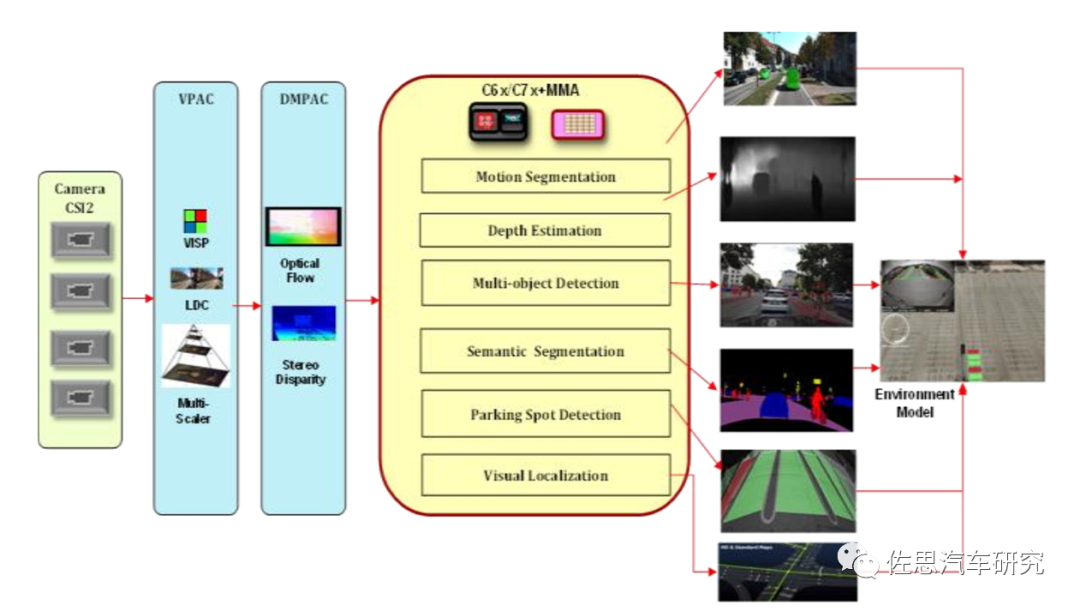
图片来源:德州仪器
TDA4VMID的软件栈与负载分析
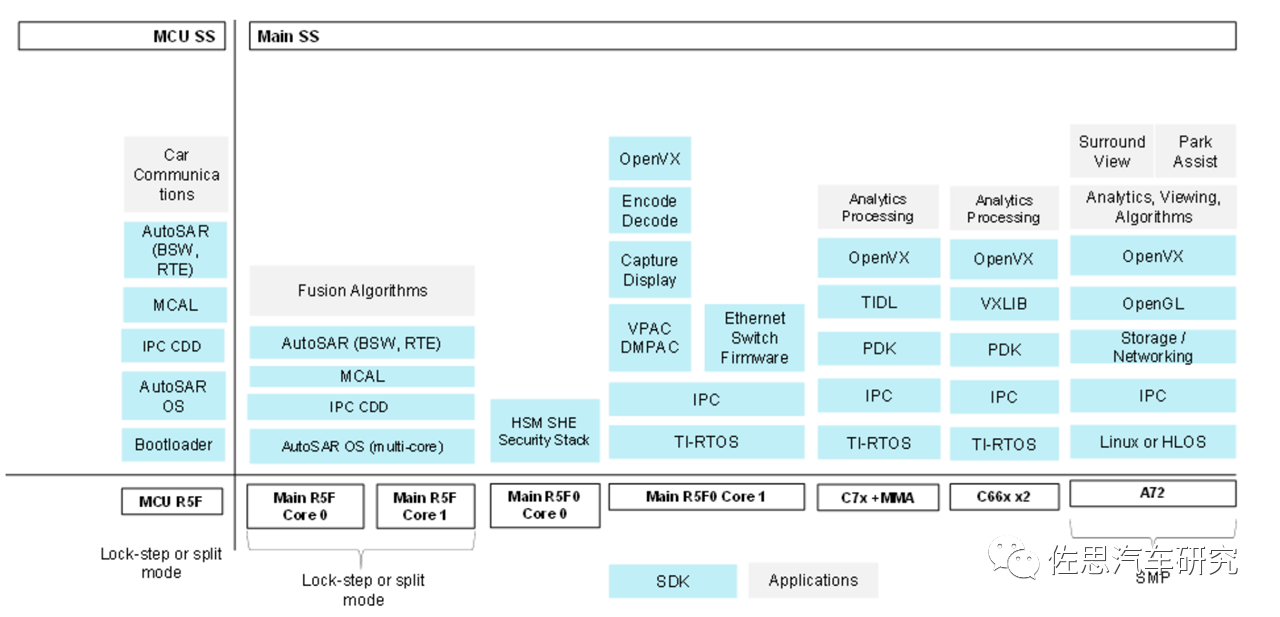
图片来源:德州仪器
关键的算法部分是OpenVX。
OpenVX中间件
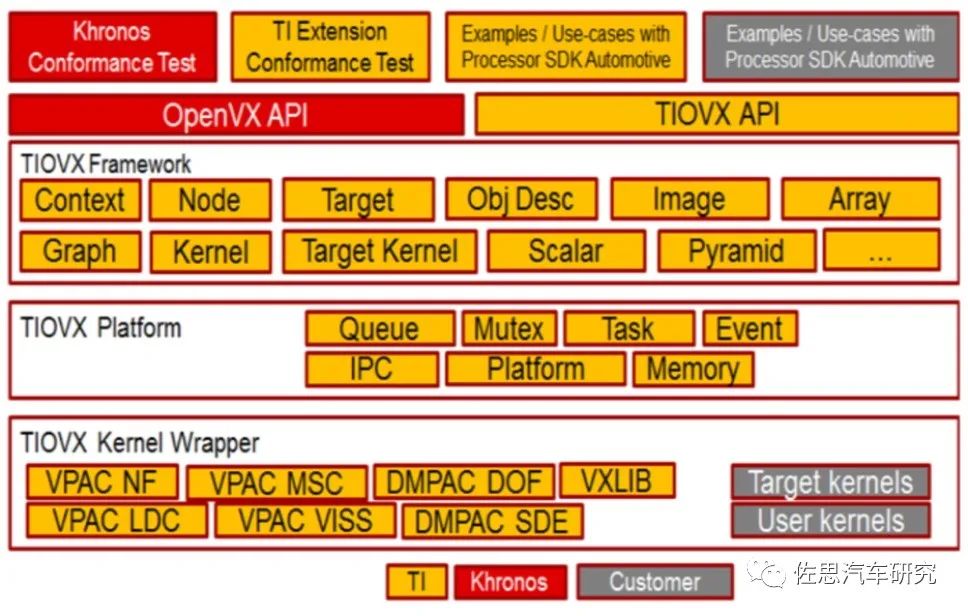
图片来源:OpenVX
图片来源:OpenVX
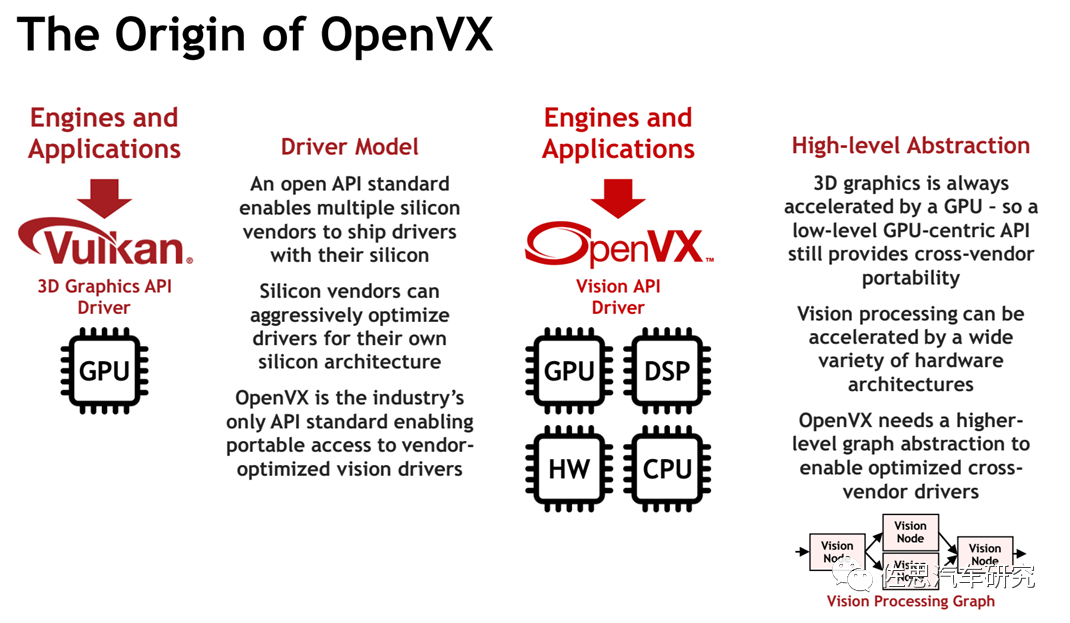
我们来研究一下今天的主角:OpenVX,这实际是TDA4的核心。

图片来源:OpenVX
OpenVX是芯片内部的硬件加速器与视觉应用间的桥梁,也就是个API。
图片来源:OpenVX
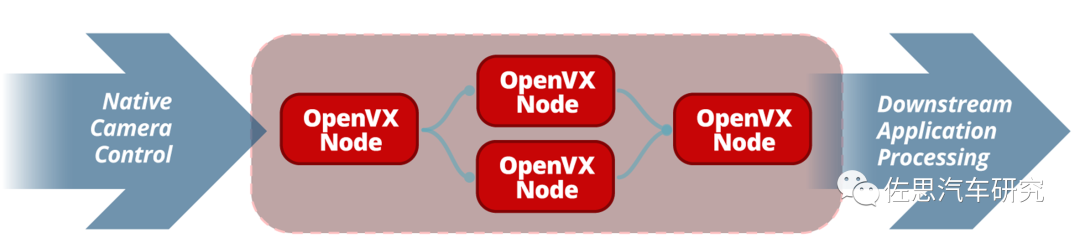
一个Graph,可以说是对象也可以说是图形,一个Graph代表一个图像处理流程,每个进程内可以有多个context(上下文),每个context内可以有多个graph(图,或连接关系),每个graph内可以有多个node(节点)。一个node就是一个最小的调度单元,可以是图像预处理算法,可以是边缘检测算法;一个graph就是一个功能,是由多个步骤连接在一起的完整功能;当graph构造完成后,即可调用vxVerifyGraph函数,交由OpenVX后端去检查参数是否合法。如果合法,即可调用vxProcessGraph函数,交由OpenVX后端将任务分发给特定的加速器和异构核心,等待全部计算完成后即函数返回。
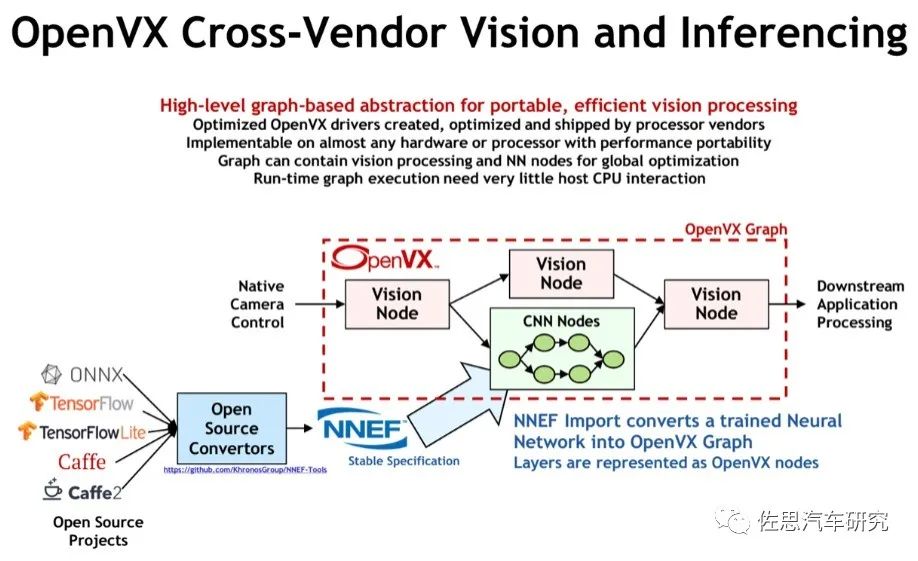
也支持CNN,不过还是不如专用的AI芯片
图片来源:OpenVX
OpenVX是非盈利开源组织Khronos定义的一套API框架,包括:
宏的定义与含义
结构体的定义与含义
函数的定义与行为
而框架的代码完全由各个公司自行实现(实现的API行为符合Khronos定义即可),例如TIOVX是TI公司对OpenVX 的实现,Khronos组织本身也提供了一个OpenVX实现作为参考。OpenVX提出的初衷之一是统一各个平台的图像处理接口,提高业务代码在不同平台下的移植性。
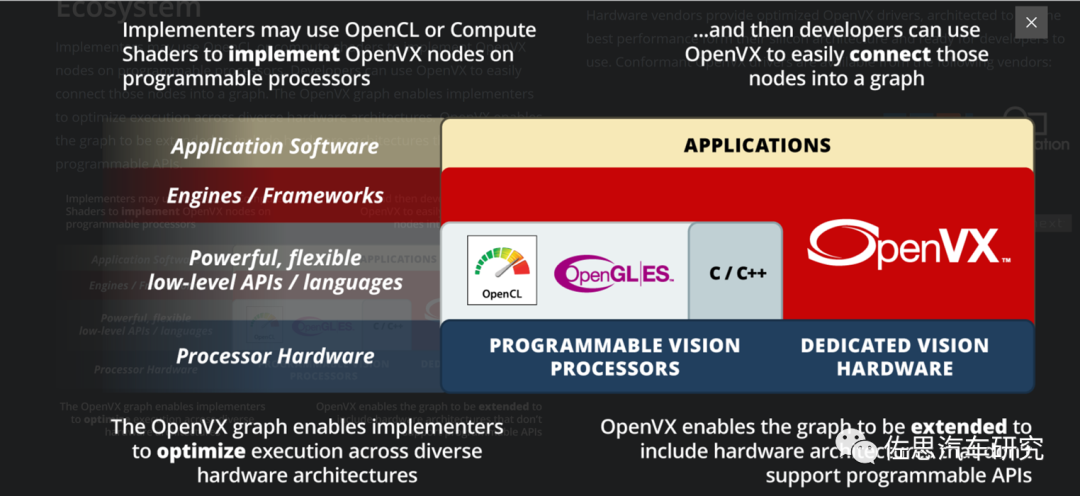
很明显,框架使用了面向对象的设计思路,即结构体(对象)中的数据对使用者隐藏,使用者只能调用相应的函数读取及修改结构体中的数据。OpenVX偏向于硬件硬解码,由芯片厂家决定,OpenCV偏向于通用软件实现功能,由社区决定。
OpenVX规范了标准化的数据结构,基本满足了嵌入式系统的主要需求,尤其是这种数据结构的描述方法对嵌入式系统非常友好:支持虚拟地址、物理地址等异构内存;提供了数据在多种地址之间映射的接口;提供了统一化的自定义结构体的描述方法。
图片来源:OpenVX
OpenCL与OpenVX对比,OpenVX受限于硬件,国内接触的很少,熟悉OpenCL的人很多。

图片来源:OpenVX
目前支持OpenVX主要是以上几家,包括树莓派、日本索喜、德州仪器、英特尔、AMD、高通,还有IP公司芯原、Imagination、CADENCE、Synopsys和 ETRI (韩国电信研究院)。2016年推出第一版OpenVX标准,目前是2019年的1.3版本,AMD和德州仪器是最早使用OpenVX的公司。
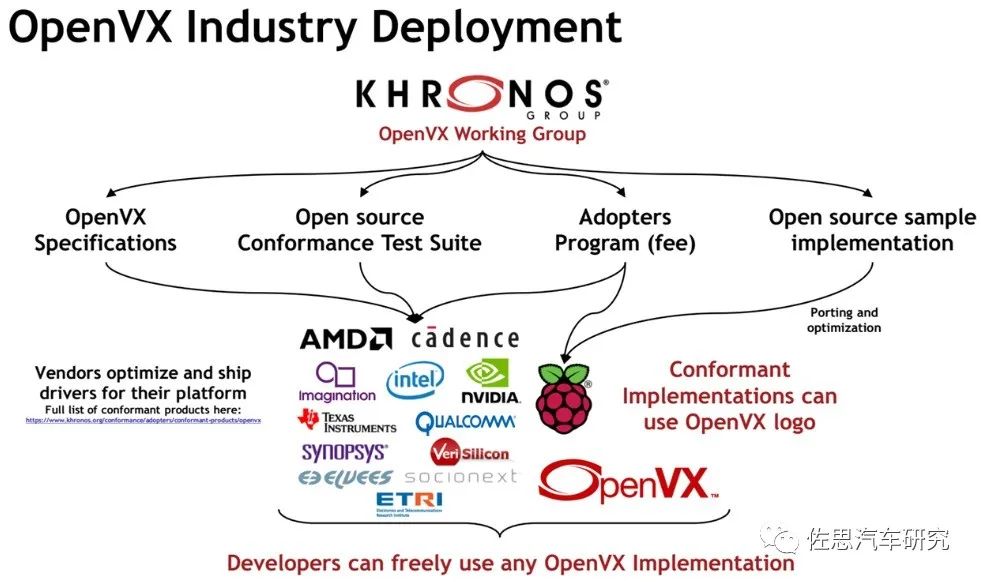
图片来源:KHRONOS
TIOVXFramework包含了官方OpenVX的标准API和TI扩展的API,其中包括public: Context, Parameter, Kernel, Node, Graph Array, Image,Scalar, Pyramid, ObjectArray ;TI: Target, Target Kernel, Obj Desc。TIOVX Platform提供了特定硬件(如TDAx, AM65x)的操作系统(如TI-RTOS, Linux)调用API。API就像饭店服务员,厨师就是底层的硬件系统,食客就像软件应用调度,食客是看不见厨师的,封装好的内核就像菜单,厨师一般只能按菜单做,新菜也能做,但会比较麻烦。
TIOVXKernel Wrapper提供了由硬件模块VPAC(Vision Pre-processing Accelerator)和DMPAC(Depthand Motion Perception Accelerator)封装成的Kernel,用户也可用Wrapper将自定义的算法(如OpenCV算法,DSP算法)封装成Kernel。Kernel是指OpenVX中的一种功能,比如对一个图片进行高通滤波,这在OpenVX 里面叫做一个user kernel。
在OpenVX中,把参数定义初始化好后的kernel叫做node,因此,node就是 kernel的一个实例化--即拥有指定参数的 kernel。 视觉预处理加速器(VPAC)是一组常见的视觉基元函数,执行内存到内存 (M2M)像素数据处理任务,例如:颜色处理和增强、噪声过滤、宽动态范围 (WDR)处理,镜头失真校正,用于去扭曲的像素重新映射,即时比例生成,即时金字塔生成。
VPAC从主SoC处理器(ARM、DSP等)卸载这些常见任务,因此可以将这些CPU用于差异化的高级算法。VPAC旨在通过在时分复用模式下工作来支持多个摄像头。VPAC用作视觉处理的前端,并为SoC中的其他视觉加速器或处理器内核的进一步处理。
VPAC逻辑图
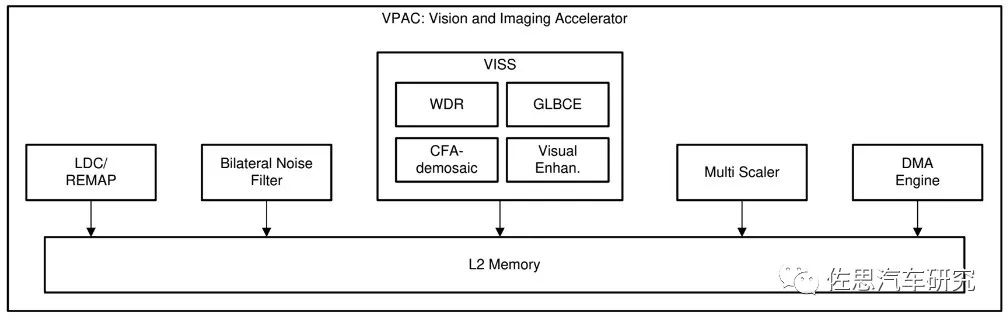
图片来源:TIOVX
DMPAC包含两个模块,即 Sterei Disparity Engine(SDE, 用于加速立体深度预测)和Dense Optical Flow Engine (DOF Engine,用于加速密集光流)。DMPAC计算来自相机输入的密集立体深度图(深度)和密集光流矢量(运动)。基于图像/视频传感器的环境感知(也称为场景理解)是汽车、工业和消费电子领域许多新兴应用的核心。通常这涉及通过分析一个或多个相关的输入视频流来检测场景中的所有对象,以及它们相对于观察者或汽车的3D位置和运动。
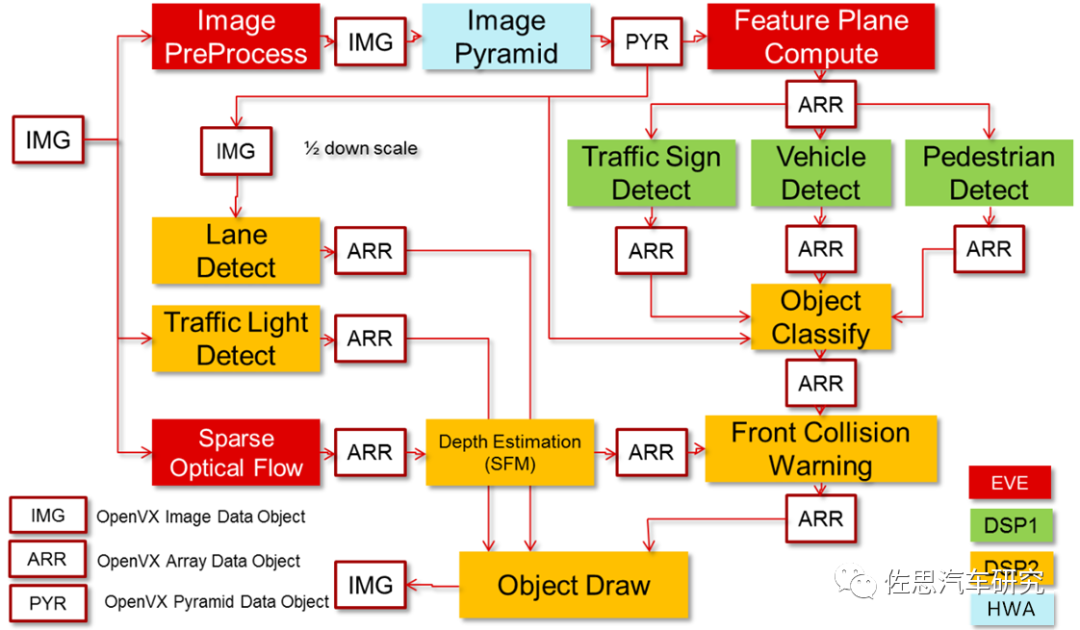
图片来源:TIOVX
上图为TIOVX的典型应用,L2级智能驾驶最核心功能AEB。每一步就是一个node。EVE是一个比较复杂的应用,需要调用ARM CPU和DSP。HWA是硬件加速,可以理解为FPGA那种查找表类型的硬连线输出。
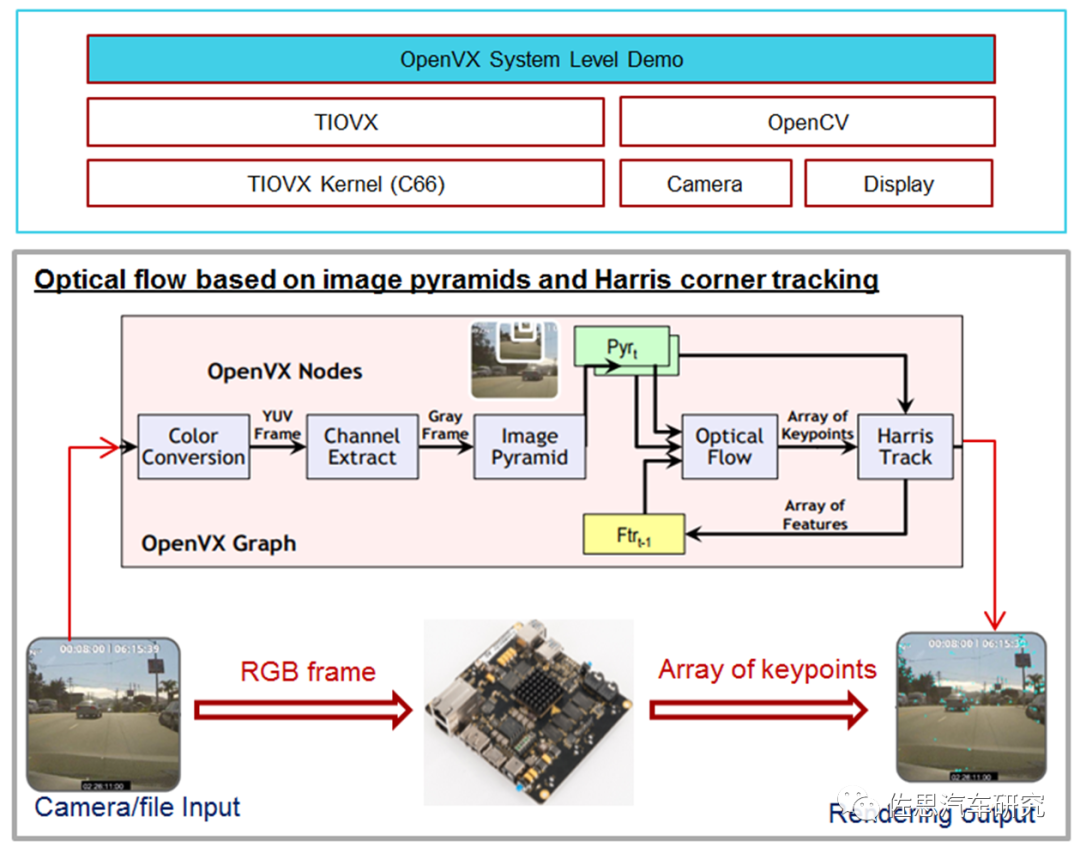
光流功能的实现可以用来追踪目标及预测目标轨迹位置
图片来源:OpenVX
用TDA4来做ADAS,算法工作量可以大幅度缩减,并且执行效率远高于手工OpenCV代码,研发成本可以大幅度降低,这也是TDA4横扫行泊一体市场的原因。
审核编辑:刘清
-
TDA4 HS Prime密钥烧录以及vHSM的集成2024-09-27 826
-
TDA4系列的SPI启用和验证2024-09-04 539
-
TDA4:定制电路板启动指南2024-08-28 629
-
TDA4刷写技术2024-08-23 551
-
德州仪器助力Nullmax智能驾驶产品亮相北京车展2024-05-07 1394
-
TDA4对深度学习的重要性2022-11-03 1536
-
当深度学习遇上TDA42022-10-28 847
-
德州仪器dsp芯片2021-07-28 2579
-
德州仪器的OMAP4系列芯片介绍2018-06-26 6240
-
《德州仪器》介绍2015-10-27 1099
-
德州仪器推荐器件2013-09-03 7376
-
各类NXP FREESCALE,TI(德州仪器)2013-05-11 2718
-
德州仪器(TI)模拟开关资料2012-12-20 5692
-
德州仪器(TI)副总裁访华,介绍收购Luminary背后的M2009-07-28 764
全部0条评论

快来发表一下你的评论吧 !
