

从3D车道线到局部地图,BEV视角求解「路在何方」| Nullmax进化学
描述
在发达的现代公路交通体系中,「各行其道」是交通运行的一项核心前提,车辆和行人按照划分的道路区域规范通行,可以最大程度地保障交通的安全和效率。因此对自动驾驶来说,从环境信息中求解出自己的道路区域是至关重要的感知任务。
在这方面,Nullmax曾分享过一些出色的研究,包括用于3D车道线检测的CurveFormer,近日入选了国际机器人和自动化顶级会议ICRA 2023,以及可用于局部地图构建的BevSegFormer,入选了计算机视觉领域知名会议WACV 2023。
这两篇论文均是在BEV视角下,基于Transformer对自动驾驶的「路在何方」问题进行了求解,不仅取得了极其出色的算法性能,还高效解决了实际量产应用中的一些难点、痛点,比如:更进一步的车道检测效果,更满足下游需求的任务输出;通过车端实时构建局部地图,将驾驶场景扩展至任意道路。
作为BEV + Transformer技术架构的部分研究,这些技术正与更多的拓展工作,一同应用到Nullmax的多个量产项目中。
BEV感知与车道线检测
在自动驾驶感知中,实时检测环境中的车道情况,乃至构建一份要素更多的局部地图,可以视为理解静态场景的核心工作。有了车道信息,车辆便可以在车道内和车道间进行一系列操作,如巡航、跟车、变道等,从而实现连贯的智能驾驶。
当中,感知系统需要提供自车坐标系下的车道线参数曲线,以便于下游的规控模块使用。因此一些比较领先的行业方案,是将车道线检测的输出设计为BEV视角下的2D或3D车道线参数曲线。
BEV的原意是鸟瞰图视角,这种俯瞰全局的表征方式可以更好地融合不同传感器输入的数据信息,在空间、时间维度进行统一的计算。其中,BEV视角一般可以设为相机坐标系,通过车辆下线的标定与自车坐标系进行便捷的转换,所以BEV视角的车道线结果下游可以直接使用。
但是在行业内,更常见的是另一种方式:先在相机输入的图像上进行感知计算,然后再经过复杂的后处理将图像空间的结果转换到BEV视角下的3D空间。
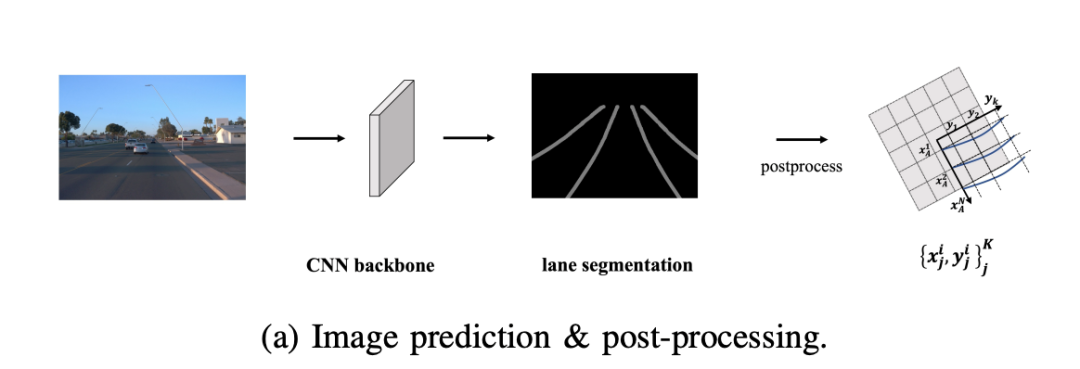
当中的不足在于,这个后处理的过程需要工程师编写大量代码,同时也会消耗大量计算资源。而且面对千变万化的真实世界,这种基于人工规则的后处理方式,也很难在各种情况下都获得满意的效果。
因此,包括车道线检测在内的很多感知任务,将后处理部分设计为基于学习的模块,让整个算法以学习为主,这样的话就可以重新定义任务,甚至重构整个自动驾驶系统。
比如车道线检测的任务,就可以直接定义为:输入图像,输出BEV视角的车道线参数曲线。
面向量产的3D车道线算法
在去年,Nullmax提出了基于Transformer的3D车道线检测方法CurveFormer,取得了业界最佳(SOTA)的算法效果,论文在今年被国际机器人领域顶会ICRA录用。
论文链接:https://arxiv.org/abs/2209.07989v1
这项算法可以直接输出BEV视角的3D车道线参数曲线,而不是在图像空间进行输出。当中的技术亮点在于,无需显式构建BEV空间,直接从图像特征求解BEV视角的3D车道线参数曲线,将计算量大大减少。
一般基于CNN和其他Transformer的方法,需要先构建稠密的BEV空间(比如100*100大小的BEV grid)生成BEV特征图,然后以此为基础完成感知任务的输出。
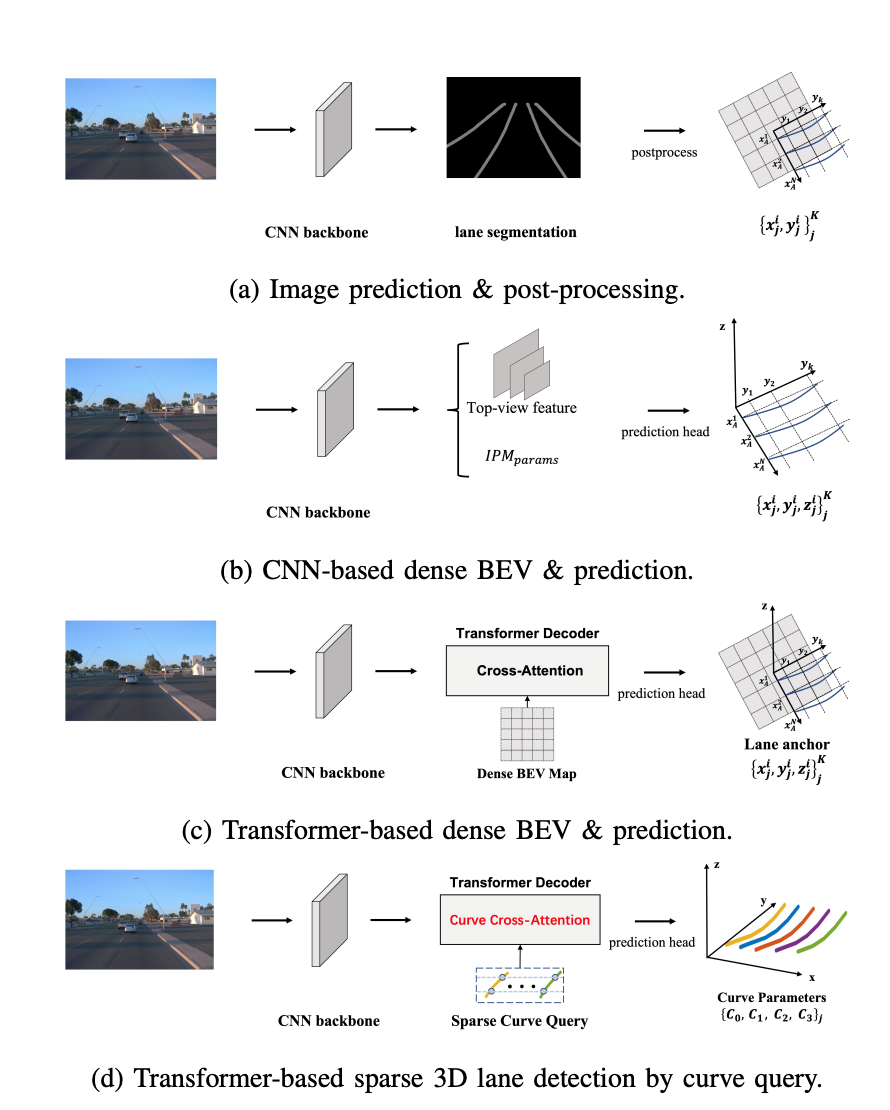
但在现实世界,很多感知对象稀疏分布在环境当中。比如障碍物检测时,视野范围内的目标通常只有几个;车道线检测时,视野范围内的车道线也只有几根。这些感知对象的数量,远远小于BEV网格的数量,显式构建稠密BEV空间的做法不够高效,产生大量多余计算。
Nullmax借鉴目标检测方面的一些思路,将车道线描述为稀疏的曲线query,利用deformable attention机制构建符合车道线检测的curve cross attention,完成BEV空间query和图像特征之间的关联,并通过迭代更新的方式输出3D车道线参数,大大减少了整个过程的计算量。
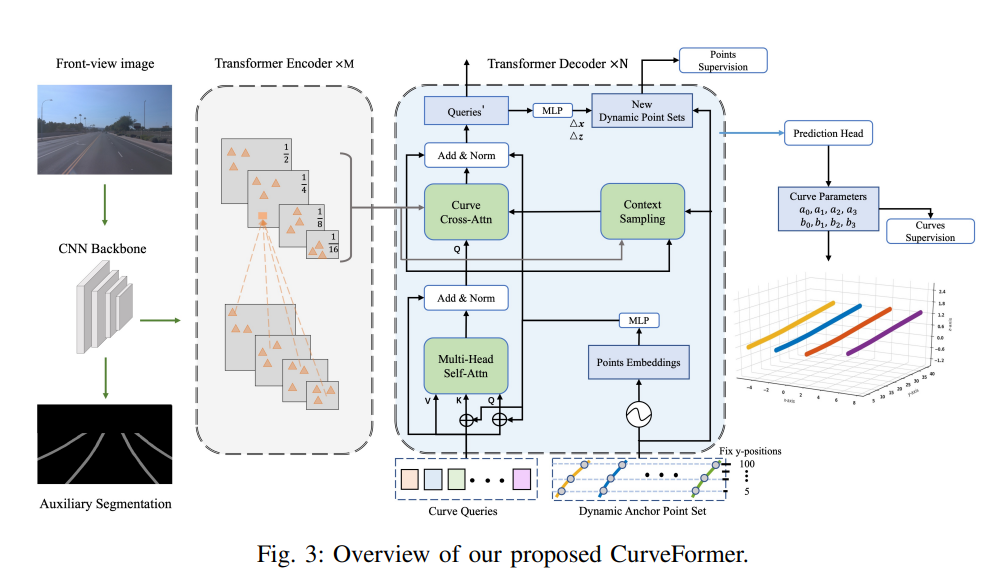
在合成数据集和真实世界数据集上,CurveFormer与3D-LaneNet、Gen-LaneNet、PersFormer等优秀算法进行了对比,实验数据显示CurveFormer拥有非常全面的优异性能,优于其他算法。
因此在量产应用中,CurveFormer也呈现出了巨大的落地优势,不仅任务效果出众,可以满足复杂城市道路等场景下的车道线检测要求,而且计算需求不大,可以部署到算力较低的量产计算平台之上。
局部地图与全场景驾驶
对于自动驾驶来说,车道线检测只是「寻路问道」的一种形态,如果更进一步,在车端实时构建局部地图,那么自动驾驶在技术和应用上还有更多发挥的空间。
比如,通过常规导航地图+高精度局部地图,将驾驶场景扩展至任意常规道路,摆脱对高精地图的依赖。车辆基于导航地图进行全局的道路规划,然后通过局部地图进行具体轨迹的规划,这样在没有高精地图的情况下,自动驾驶功能也能正常启用,完成任意场景下A点到B点的行驶。
再比如,基于局部地图打造端到端的整体方案,也就是一些地方所说的单栈式方案。近年来,学习为主的规划算法成为新的趋势,在这种算法设计下,局部地图相比于车道线是一种更为直接的输出形式,感知、规划更便于融为一个整体网络。
正是如此,局部地图成为了近年来备受关注的一个技术热点。视觉信号蕴含着尤为丰富的环境信息,包括大量的语义、几何信息,因此视觉建图的思路早已在众包地图、泊车地图等方面进行了验证或应用。在这方面,最常用的方法是视觉SLAM(同步定位与地图构建)。
如今,随着BEV感知快速发展,BEV视角的语义分割、道路环境理解也成为了在线视觉建图的一个优先选项。它的优势在于可以很好地融合多个视角相机的图像,提取出丰富的环境信息,整体效果更加鲁棒。同时,BEV视角的语义分割也更方便和其他BEV视角的感知任务、规划任务整合,形成端到端的整体方案,进行全局的优化。
局部地图和其他地图相比,不仅关注地图信息的高精度,还尤为看重车端的实时性,因此这也对算法提出了很高的要求。
行业顶尖的BEV语义分割
为了更好地满足自动驾驶上下游的需求,打造面向全场景的自动驾驶功能,Nullmax的感知团队在去年提出了面向任意相机配置(单个或多个)的BEV语义分割算法BEVSegFormer。
这一基于Transformer的BEV语义分割方法,同样也取得了当下业界最优(SOTA)的算法效果,论文入选计算机视觉学术会议WACV 2023。BEVSegFormer相比于HDMapNet等优秀算法,性能提升超过了10个百分点。
论文链接:https://arxiv.org/abs/2203.04050
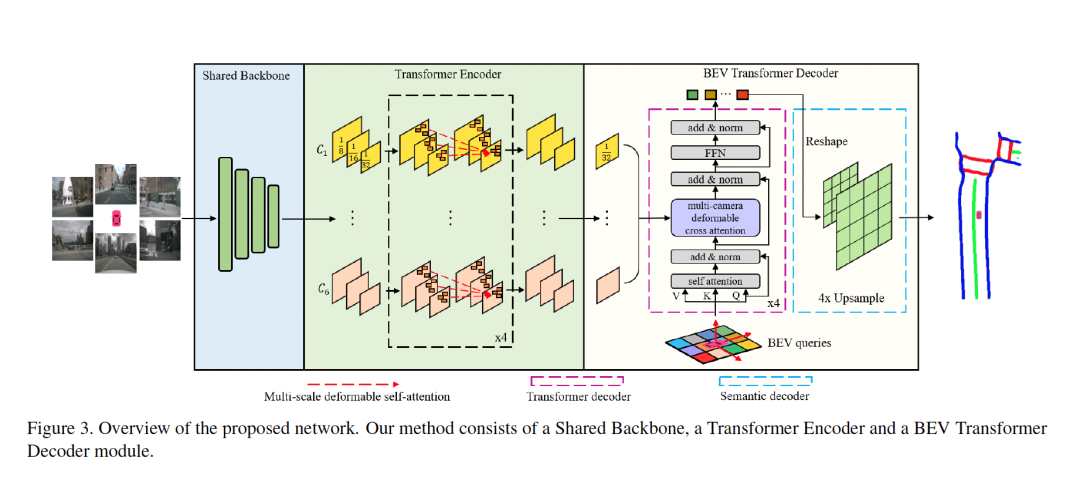
BEVSegFormer同样扩展deformable attention形成multi-camera cross attention,完成BEV空间的query和图像特征之间的关联,从而实现了不依赖相机参数,另一方面也可以大大节约计算量。
在实际的行车过程中,颠簸、加速、制动、上下坡等情况都可能引起相机外参的变化,精准的实时相机外参估计相对困难,不依赖相机的参数,可以让算法在这些情况下更加稳定,鲁棒性更强。
特别是,BEVSegFormer不依赖相机参数就可以将图像特征转成BEV特征,基于得到的BEV特征,又可以扩展出多个其他任务,比如3D目标检测,包括将不同时刻的BEV特征缓存下来,进行时序上的融合。并且基于这一创新点,Nullmax感知团队已经完成了多项扩展研究。
目前,Nullmax正在将BEVSegFormer应用到量产项目中,实时构建稠密的高精度局部地图,帮助客户拓展功能范围,从而实现任意常规道路上的智能驾驶。
结语
当前,Nullmax正在完成一套车端实时运行BEV + Transformer技术架构,同时支持感知、规划任务,并能在高、中、低算力平台上完成落地的自动驾驶整体方案。通过BEV感知完成3D车道线检测和局部地图构建,正是当中的一部分工作。
预计在2023年,Nullmax打造的这套多相机BEV-AI方案就将完成交付。通过这些先进的技术,Nullmax希望能够为普通用户提供极致安全、舒适高效的智能驾驶体验。
审核编辑 :李倩
-
TechWiz LCD 3D应用:局部液晶配向2025-01-03 961
-
Nullmax提出多相机3D目标检测新方法QAF2D2024-02-27 2191
-
顶刊TPAMI最全综述!深入自动驾驶BEV感知的魔力!2024-01-14 2367
-
汽车电子的lidar检测车道线原理分析2023-02-07 1348
-
裸眼3D显示应用2022-11-07 1653
-
3D打印发光的登月地图2022-11-04 959
-
基于图像的车道线检测2021-07-20 1116
-
3d地图智慧城市实景的运用是怎样的2021-05-22 3244
-
OpenStack重组敢问未来路在何方?2020-05-14 1729
-
高精地图之3D栅格地图的应用2019-07-24 9415
-
Cadence推出Clarity 3D场求解器2019-06-07 4993
-
基于局部姿态先验的深度图像3D人体运动捕获方法2018-01-03 1050
-
敢问路在何方?2013-08-22 3872
全部0条评论

快来发表一下你的评论吧 !
