

【AI简报第20230217期】超越GPT 3.5的小模型来了!AI网恋诈骗时代开启
描述
嵌入式 AI
AI 简报 20230217 期
1. 超越GPT 3.5的小模型来了!
原文:https://mp.weixin.qq.com/s/gv_FJD0aIpDNbky54unj2Q
论文地址:https://arxiv.org/abs/2302.00923
项目地址:https://github.com/amazon-science/mm-cot
去年年底,OpenAI 向公众推出了 ChatGPT,一经发布,这项技术立即将 AI 驱动的聊天机器人推向了主流话语的中心,众多研究者并就其如何改变商业、教育等展开了一轮又一轮辩论。
随后,科技巨头们纷纷跟进投入科研团队,他们所谓的「生成式 AI」技术(可以制作对话文本、图形等的技术)也已准备就绪。
众所周知,ChatGPT 是在 GPT-3.5 系列模型的基础上微调而来的,我们看到很多研究也在紧随其后紧追慢赶,但是,与 ChatGPT 相比,他们的新研究效果到底有多好?近日,亚马逊发布的一篇论文《Multimodal Chain-of-Thought Reasoning in Language Models》中,他们提出了包含视觉特征的 Multimodal-CoT,该架构在参数量小于 10 亿的情况下,在 ScienceQA 基准测试中,比 GPT-3.5 高出 16 个百分点 (75.17%→91.68%),甚至超过了许多人类。
这里简单介绍一下 ScienceQA 基准测试,它是首个标注详细解释的多模态科学问答数据集 ,由 UCLA 和艾伦人工智能研究院(AI2)提出,主要用于测试模型的多模态推理能力,有着非常丰富的领域多样性,涵盖了自然科学、语言科学和社会科学领域,对模型的逻辑推理能力提出了很高的要求。

下面我们来看看亚马逊的语言模型是如何超越 GPT-3.5 的。
包含视觉特征的 Multimodal-CoT
大型语言模型 (LLM) 在复杂推理任务上表现出色,离不开思维链 (CoT) 提示的助攻。然而,现有的 CoT 研究只关注语言模态。为了在多模态中触发 CoT 推理,一种可能的解决方案是通过融合视觉和语言特征来微调小型语言模型以执行 CoT 推理。
然而,根据已有观察,小模型往往比大模型更能频繁地胡编乱造,模型的这种行为通常被称为「幻觉(hallucination)」。此前谷歌的一项研究也表明( 论文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ),基于 CoT 的提示只有在模型具有至少 1000 亿参数时才有用!
也就是说,CoT 提示不会对小型模型的性能产生积极影响,并且只有在与 ∼100B 参数的模型一起使用时才会产生性能提升。
然而,本文研究在小于 10 亿参数的情况下就产生了性能提升,是如何做到的呢?简单来讲,本文提出了包含视觉特征的 Multimodal-CoT,通过这一范式(Multimodal-CoT)来寻找多模态中的 CoT 推理。
Multimodal-CoT 将视觉特征结合在一个单独的训练框架中,以减少语言模型有产生幻觉推理模式倾向的影响。总体而言,该框架将推理过程分为两部分:基本原理生成(寻找原因)和答案推理(找出答案)。
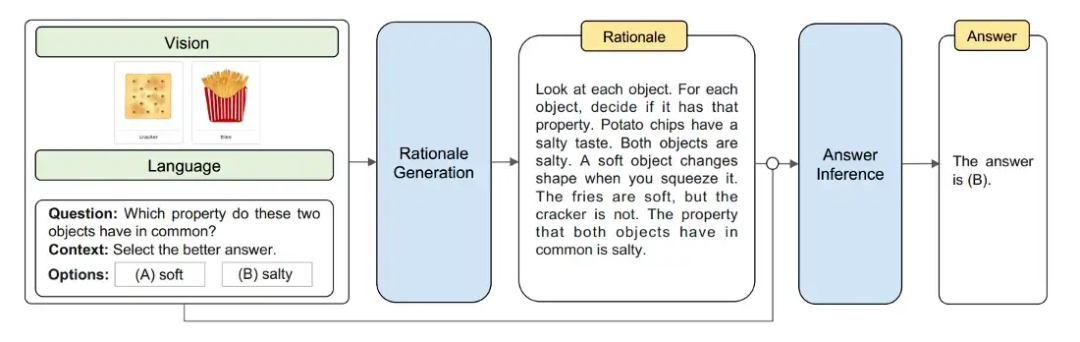
数据集
本文主要关注 ScienceQA 数据集,该数据集将图像和文本作为上下文的一部分,此外,该数据集还包含对答案的解释,以便可以对模型进行微调以生成 CoT 基本原理。此外,本文利用 DETR 模型生成视觉特征。
较小的 LM 在生成 CoT / 基本原理时容易产生幻觉,作者推测,如果有一个修改过的架构,模型可以利用 LM 生成的文本特征和图像模型生成的视觉特征,那么 更有能力提出理由和回答问题。
架构
总的来说,我们需要一个可以生成文本特征和视觉特征并利用它们生成文本响应的模型。
又已知文本和视觉特征之间存在的某种交互,本质上是某种共同注意力机制,这有助于封装两种模态中存在的信息,这就让借鉴思路成为了可能。为了完成所有这些,作者选择了 T5 模型,它具有编码器 - 解码器架构,并且如上所述,DETR 模型用于生成视觉特征。
T5 模型的编码器负责生成文本特征,但 T5 模型的解码器并没有利用编码器产生的文本特征,而是使用作者提出的共同注意式交互层(co-attention-styled interaction layer)的输出。
拆解来看,假设 H_language 是 T5 编码器的输出。X_vision 是 DETR 的输出。第一步是确保视觉特征和文本特征具有相同的隐藏大小,以便我们可以使用注意力层。
结果
作者使用 UnifiedQA 模型的权重作为 T5 模型的初始化点,并在 ScienceQA 数据集上对其进行微调。他们观察到他们的 Multimodal CoT 方法优于所有以前的基准,包括 GPT-3.5。
有趣的地方在于,即使只有 2.23 亿个参数的基本模型也优于 GPT-3.5 和其他 Visual QA 模型!这突出了拥有多模态架构的力量。
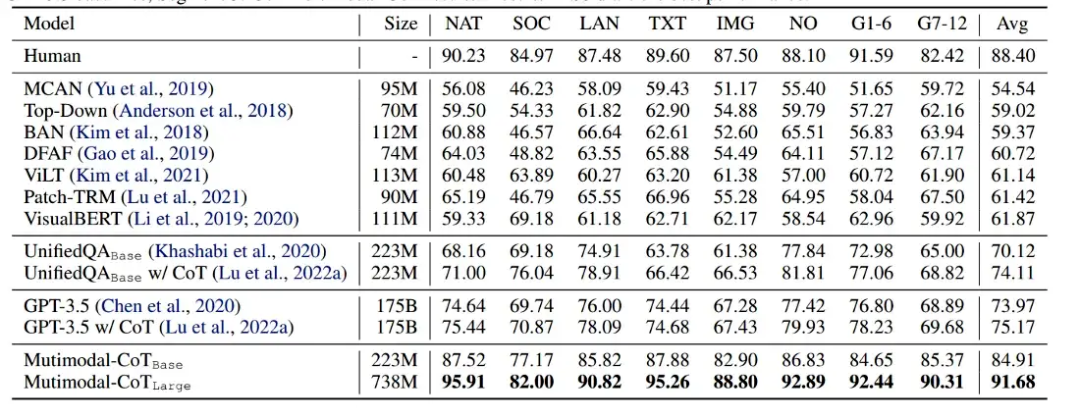
结论
这篇论文带来的最大收获是多模态特征在解决具有视觉和文本特征的问题时是多么强大。
作者展示了利用视觉特征,即使是小型语言模型(LM)也可以产生有意义的思维链 / 推理,而幻觉要少得多,这揭示了视觉模型在发展基于思维链的学习技术中可以发挥的作用。
从实验中,我们看到以几百万个参数为代价添加视觉特征的方式,比将纯文本模型扩展到数十亿个参数能带来更大的价值。
2. AI照骗恐怖如斯!美女刷屏真假难辨,网友:AI网恋诈骗时代开启
原文:https://mp.weixin.qq.com/s/nELNzal7tjkbZ6uKkuGkeA
什么?这些不是真人照片,都是AI画出来的?!
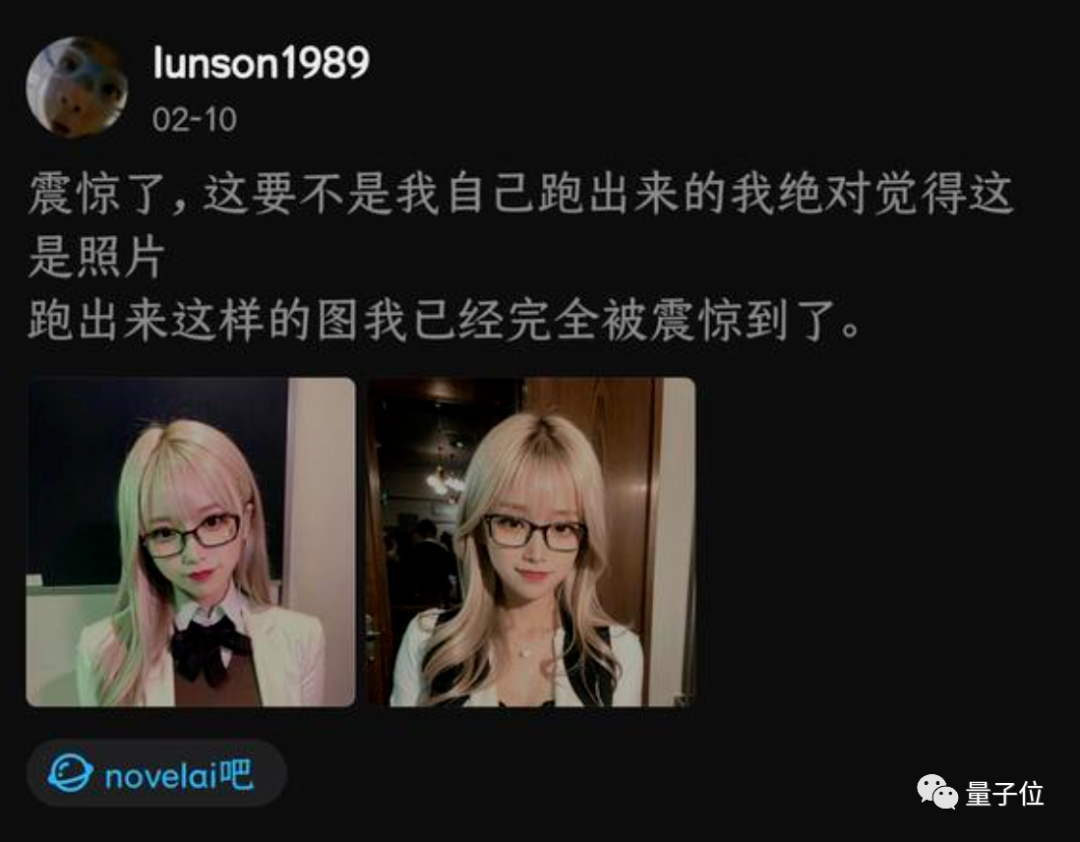
最近这样一组美女图片刷屏了,许多人看到第一反应都是“AI逼真到这个份上了?”。

直到看到手部露出了破绽,才敢确定确实是AI画的。

嗯….啥都不想说,看就得了,感兴趣的小伙伴直接查看原文。
3. YOLOv7农业方向应用|基于注意力机制改进的YOLOv7算法CBAM-YOLOv7
原文:https://mp.weixin.qq.com/s/HXKsTnSbr8Ks1VF2p7RoTA
论文链接:https://www.mdpi.com/2077-0472/12/10/1659/pdf
饲养密度是影响畜禽大规模生产和动物福利的关键因素。然而,麻鸭养殖业目前使用的人工计数方法效率低、人工成本高、精度低,而且容易重复计数和遗漏。
在这方面,本文使用深度学习算法来实现对密集麻鸭群数量的实时监测,并促进智能农业产业的发展。本文构建了一个新的大规模大麻鸭目标检测图像数据集,其中包含1500个大麻鸭目标的检测全身帧标记和仅头部帧标记。
此外,本文提出了一种基于注意力机制改进的YOLOv7算法CBAM-YOLOv7,在YOLOv7的主干网络中添加了3个CBAM模块,以提高网络提取特征的能力,并引入SE-YOLOv7和ECA-YOLOv7进行比较实验。实验结果表明,CBAM-YOLOv7具有较高的精度,mAP@0.5和mAP@0.5:0.95略有改善。CBAM-YOLOv7的评价指标值比SE-YOLOw7和ECA-YOLOv 7的提高更大。此外,还对两种标记方法进行了比较测试,发现仅头部标记方法导致了大量特征信息的丢失,而全身框架标记方法显示了更好的检测效果。
算法性能评估结果表明,本文提出的智能麻鸭计数方法是可行的,可以促进智能可靠的自动计数方法的发展。

随着技术的发展,监控设备在农业中发挥着巨大的作用。有多种方法可以监测个体动物的行为,例如插入芯片记录生理数据、使用可穿戴传感器和(热)成像技术。一些方法使用附着在鸟类脚上的可穿戴传感器来测量它们的活动,但这可能会对受监测的动物产生额外影响。特别是,在商业环境中,技术限制和高成本导致这种方法的可行性低。
因此,基于光流的视频评估将是监测家禽行为和生理的理想方法。最初,许多监控视频都是人工观察的,效率低下,依赖于工作人员的经验判断,没有标准。然而,近年来,由于大数据时代的到来和计算机图形卡的快速发展,计算机的计算能力不断增强,加速了人工智能的发展。与人工智能相关的研究正在增加,计算机视觉在动物检测中的应用越来越广泛。
例如,2014年Girshick等人提出的R-CNN首次引入了两阶段检测方法。该方法使用深度卷积网络来获得优异的目标检测精度,但其许多冗余操作大大增加了空间和时间成本,并且难以在实际的养鸭场中部署。Law等人提出了一种单阶段的目标检测方法CornerNet和一种新的池化方法:角点池化。
然而,基于关键点的方法经常遇到大量不正确的目标边界框,这限制了其性能,无法满足鸭子饲养模型的高性能要求。Duan等人在CornerNet的基础上构建了CenterNet框架,以提高准确性和召回率,并设计了两个对特征级噪声具有更强鲁棒性的自定义模块,但Anchor-Free方法是一个具有前两个关键点组合的过程,并且由于网络结构简单、处理耗时、速率低和测量结果不稳定,它不能满足麻鸭工业化养殖所需的高性能和高准确率的要求。
本文的工作使用了一种单阶段目标检测算法,它只需要提取特征一次,就可以实现目标检测,其性能高于多阶段算法。目前,主流的单阶段目标检测算法主要包括YOLO系列、SSD、RetinaNet等。本文将基于CNN的人群计数思想转移并应用到鸭计数问题中。随着检测结果的输出,作者嵌入了一个目标计数模块来响应工业化的需求。目标计数也是计算机视觉领域的一项常见任务。目标计数可分为多类别目标计数和单类别目标计数;本工作采用了一群大麻鸭的单类别计数。
本文希望实现的目标是:
建立了一个新的大规模的德雷克图像数据集,并将其命名为“大麻鸭数据集”。大麻鸭数据集包含1500个标签,用于全身框架和头部框架,用于鸭的目标检测。该团队首次发布了大麻鸭数据集
本研究构建了大鸭识别、大鸭目标检测、大鸭图像计数等全面的工作基线,实现了麻鸭的智能养殖
该项目模型引入了CBAM模块来构建CBAM-YOLOv7算法
本文很长,同时基础理论和背景介绍的非常详细,感兴趣的小伙伴可以翻看原文,进行研究。
4. AutoML并非全能神器!新综述爆火,网友:了解深度学习领域现状必读
原文:https://mp.weixin.qq.com/s/qR2bMaZby299PlEHUlNoBQ
如今深度学习模型开发已经非常成熟,进入大规模应用阶段。
然而,在设计模型时,不可避免地会经历迭代这一过程,它也正是造成模型设计复杂、成本巨高的核心原因,此前通常由经验丰富的工程师来完成。
之所以迭代过程如此“烧金”,是因为在这一过程中,面临大量的开放性问题 (open problems)。
这些开放性问题究竟会出现在哪些地方?又要如何解决、能否并行化解决?
现在一篇论文综述终于对此做出介绍,发出后立刻在网上爆火。
作者严谨地参考了接近300篇文献,对大量应用深度学习中的开放问题进行分析,力求让读者一文了解该领域最新趋势。

这篇论文要研究什么?
众所周知,当我们拿到一个机器学习问题时,通常处理的流程分为以下几步:收集数据、编写模型、训练模型、评估模型、迭代、测试、产品化。
在这篇论文中,作者把上述这些流程比作一个双层次的最佳化问题。
内层优化回路需要最小化衡量模型效果评估的损失函数,背后是为了寻求最佳模型参数而进行的深入研究的训练过程。
而外层优化回路的研究较少,包括最大化一个适当选择的性能指标来评估验证数据,这正是我们所说的“迭代过程”,也就是追求最优模型超参数的过程。
不过,值得注意的是,面对不同的问题,它的解也需要特定分析,有时候情况甚至会非常复杂。
例如,评估度量Mval是一个离散且不可微的函数。它并未被很好地定义,有时候甚至在某些自我监督式和非监督式学习以及生成模型问题中不存在。
同时,你也可能设计了一个非常好的损失函数Ltrain,结果发现它是离散或不可微的,这种情况下它会变得非常棘手,需要用特定方法加以解决。
因此,本篇论文的研究重点就是迭代过程中遇到的各种开放性问题,以及这些问题中可以并行解决优化的部分案例。
机器学习中开放问题有哪些?
论文将开放性问题类型分为监督学习和其他方法两大类。
值得一提的是,无论是监督学习还是其他方法,作者都贴心地附上了对应的教程地址:
如果对概念本身还不了解的话,点击就能直接学到他教授的视频课程,不用担心有困惑的地方。
首先来看看监督学习。
这里我们不得不提到AutoML。作为一种用来降低开发过程中迭代复杂度的“偷懒”方法,它目前在机器学习中已经应用广泛了。
通常来说,AutoML更侧重于在监督学习方法中的应用,尤其是图像分类问题。
毕竟图像分类可以明确采用精度作为评估指标,使用AutoML非常方便。
但如果同时考虑多个因素,尤其是包括计算效率在内,这些方法是否还能进一步被优化?
在这种情况下,如何提升性能就成为了一类开放性问题,具体又分为以下几类:
大模型、小模型、模型鲁棒性、可解释AI、迁移学习、语义分割、超分辨率&降噪&着色、姿态估计、光流&深度估计、目标检测、人脸识别&检测、视频&3D模型等。
这些不同的领域也面临不同的开放性问题。
例如大模型中的学习率并非常数、而是函数,会成为开放问题之一,相比之下小模型却更考虑性能和内存(或计算效率)的权衡这种开放性问题。
其中,小模型通常会应用到物联网、智能手机这种小型设备中,相比大模型需求算力更低。
又例如对于目标检测这样的模型而言,如何优化不同目标之间检测的准确度,同样是一种复杂的开放性问题。
在这些开放性问题中,有不少可以通过并行方式解决。如在迁移学习中,迭代时学习到的特征会对下游任务可泛化性和可迁移性同时产生什么影响,就是一个可以并行研究的过程。
同时,并行处理开放性问题面临的难度也不一样。
例如基于3D点云数据同时施行目标识别、检测和语义分割,比基于2D图像的目标识别、检测和分割任务更具挑战性。
再来看看监督学习以外的其他方法,具体又分为这几类:
自然语言处理(NLP)、多模态学习、生成网络、域适应、少样本学习、半监督&自监督学习、语音模型、强化学习、物理知识学习等。
以自然语言处理为例,其中的多任务学习会给模型带来新的开放性问题。
像经典的BERT模型,本身不具备翻译能力,因此为了同时提升多种下游任务性能指标,研究者们需要权衡各种目标函数之间的结果。
又如生成模型中的CGAN(条件GAN),其中像图像到图像翻译问题,即将一张图片转换为另一张图片的过程。
这一过程要求将多个独立损失函数进行加权组合,并让总损失函数最小化,就又是一个开放性问题。
其他不同的问题和模型,也分别都会在特定应用上遇到不同类型的开放性问题,因此具体问题依旧得具体分析。
经过对各类机器学习领域进行分析后,作者得出了自己的一些看法。
一方面,AI表面上是一种“自动化”的过程,从大量数据中产生自己的理解,然而这其中其实涉及大量的人为操作,有不少甚至是重复行为,这被称之为“迭代过程”。
另一方面,这些工作虽然能部分通过AutoML精简,然而AutoML目前只在图像分类中有较好的表现,并不意味着它在其他领域任务中会取得成功。
总而言之,应用深度学习中的开放性问题,依旧比许多人想象得要更为复杂。
论文地址:https://arxiv.org/abs/2301.11316
5. ChatGPT的技术体系总结
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
0.参考资料
RLHF论文:Training language models to follow instructions with human feedback(https://arxiv.org/pdf/2203.02155.pdf)
摘要上下文中的 RLHF:Learning to summarize from Human Feedback (https://arxiv.org/pdf/2009.01325.pdf)
PPO论文:Proximal Policy Optimization Algorithms(https://arxiv.org/pdf/1707.06347.pdf)
Deep reinforcement learning from human preferences (https://arxiv.org/abs/1706.03741)
1.引言
1.1 ChatGPT的介绍
作为一个 AI Chatbot,ChatGPT 是当前比较强大的自然语言处理模型之一,它基于 Google 的 T5 模型进行了改进,同时加入了许多自然语言处理的技术,使得它可以与人类进行自然的、连贯的对话。ChatGPT 使用了 GPT(Generative Pre-training Transformer)架构,它是一种基于 Transformer 的预训练语言模型。GPT 的主要思想是将大量的语料库输入到模型中进行训练,使得模型能够理解和学习语言的语法、语义等信息,从而生成自然、连贯的文本。与其他 Chatbot 相比,ChatGPT 的优势在于它可以进行上下文感知型的对话,即它可以记住上下文信息,而不是简单地匹配预先定义的规则或模式。此外,ChatGPT 还可以对文本进行生成和理解,支持多种对话场景和话题,包括闲聊、知识问答、天气查询、新闻阅读等等。
尽管 ChatGPT 在自然语言处理领域已经取得了很好的表现,但它仍然存在一些局限性,例如对于一些复杂的、领域特定的问题,它可能无法给出正确的答案,需要通过人类干预来解决。因此,在使用 ChatGPT 进行对话时,我们仍需要谨慎对待,尽可能提供明确、简洁、准确的问题,以获得更好的对话体验。
1.2 ChatGPT的训练模式
ChatGPT 的训练模式是基于大规模文本数据集的监督学习和自我监督学习,这些数据集包括了各种类型的文本,例如新闻文章、博客、社交媒体、百科全书、小说等等。ChatGPT 通过这些数据集进行预训练,然后在特定任务的数据集上进行微调。
对于 Reinforcement Learning from Human Feedback 的训练方式,ChatGPT 通过与人类进行对话来进行模型训练。具体而言,它通过与人类进行对话,从而了解人类对话的语法、语义和上下文等方面的信息,并从中学习如何生成自然、连贯的文本。当 ChatGPT 生成回复时,人类可以对其进行反馈,例如“好的”、“不太好”等等,这些反馈将被用来调整模型参数,以提高 ChatGPT 的回复质量。Reinforcement Learning from Human Feedback 的训练方式,可以使 ChatGPT 更加智能,更好地模拟人类的思维方式。不过这种训练方式也存在一些问题,例如人类反馈的主观性和不确定性等,这些问题可能会影响模型的训练效果。因此,我们需要在使用 ChatGPT 进行对话时,谨慎对待反馈,尽可能提供明确、简洁、准确的反馈,以获得更好的对话体验。
1.3 RLHF的介绍
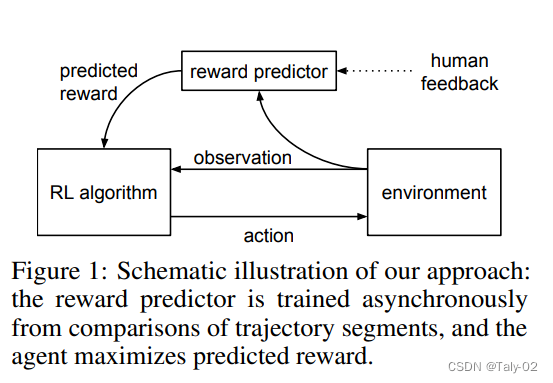
在过去的几年中,语言模型通过根据人类输入提示生成多样化且引人注目的文本显示出令人印象深刻的能力。然而,什么才是“好”文本本质上很难定义,因为它是主观的并且依赖于上下文。有许多应用程序,例如编写您需要创意的故事、应该真实的信息性文本片段,或者我们希望可执行的代码片段。编写一个损失函数来捕获这些属性似乎很棘手,而且大多数语言模型仍然使用简单的下一个loss function(例如交叉熵)进行训练。为了弥补损失本身的缺点,人们定义了旨在更好地捕捉人类偏好的指标,例如 BLEU 或 ROUGE。虽然比损失函数本身更适合衡量性能,但这些指标只是简单地将生成的文本与具有简单规则的引用进行比较,因此也有局限性。如果我们使用生成文本的人工反馈作为性能衡量标准,或者更进一步并使用该反馈作为损失来优化模型,那不是很好吗?这就是从人类反馈中强化学习(RLHF)的想法;使用强化学习的方法直接优化带有人类反馈的语言模型。RLHF 使语言模型能够开始将在一般文本数据语料库上训练的模型与复杂人类价值观的模型对齐。
在传统的强化学习中,智能的agent需要通过不断的试错来学习如何最大化奖励函数。但是,这种方法往往需要大量的训练时间和数据,同时也很难确保智能代理所学习到的策略是符合人类期望的。Deep Reinforcement Learning from Human Preferences 则采用了一种不同的方法,即通过人类偏好来指导智能代理的训练。具体而言,它要求人类评估一系列不同策略的优劣,然后将这些评估结果作为训练数据来训练智能代理的深度神经网络。这样,智能代理就可以在人类偏好的指导下,学习到更符合人类期望的策略。除了减少训练时间和提高智能代理的性能之外,Deep Reinforcement Learning from Human Preferences 还可以在许多现实场景中发挥作用,例如游戏设计、自动驾驶等。通过使用人类偏好来指导智能代理的训练,我们可以更好地满足人类需求,并创造出更加智能和人性化的技术应用
2. 方法介绍
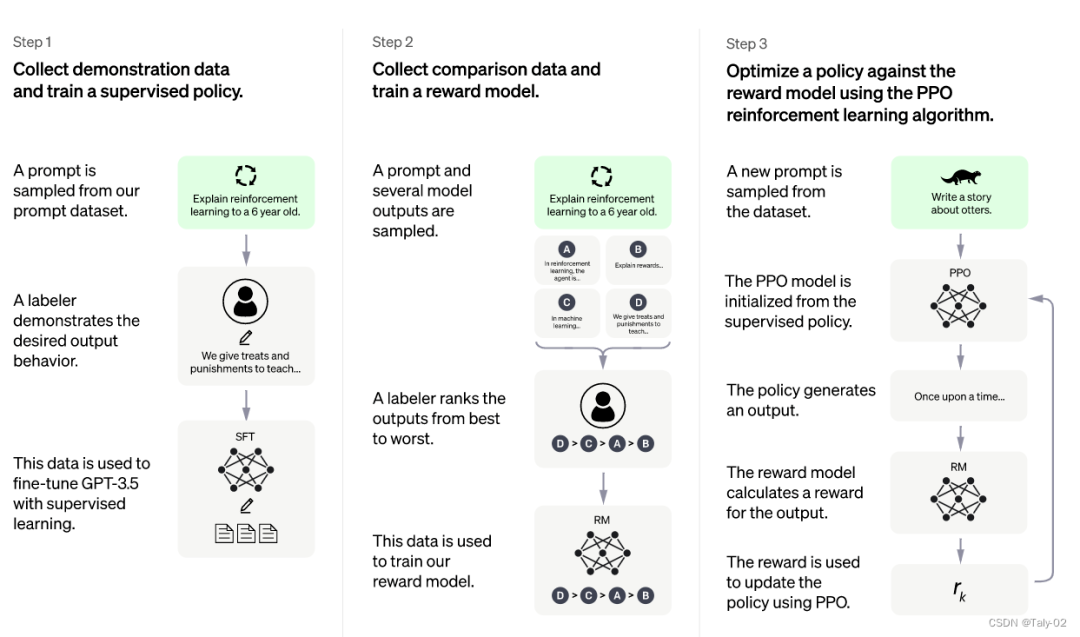
监督调优模型:在一小部分已经标注好的数据上进行有监督的调优,让机器学习从一个给定的提示列表中生成输出,这个模型被称为 SFT 模型。 模拟人类偏好,让标注者们对大量 SFT 模型输出进行投票,这样就可以得到一个由比较数据组成的新数据集。然后用这个新数据集来训练一个新模型,叫做 RM 模型。 用 RM 模型进一步调优和改进 SFT 模型,用一种叫做 PPO 的方法得到新的策略模式。
2.1 监督调优模型
2.2 训练回报模型
利用prompt 生成多个输出。 利用标注者对这些输出进行排序,获得一个更大质量更高的数据集。 把模型将 SFT 模型输出作为输入,并按优先顺序对它们进行排序。
2.3 使用 PPO 模型微调 SFT 模型
帮助性:判断模型遵循用户指示以及推断指示的能力。 真实性:判断模型在封闭领域任务中有产生虚构事实的倾向。 无害性:标注者评估模型的输出是否适当、是否包含歧视性内容。
6. 一文梳理清楚Python OpenCV 的知识体系
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
图像读取; 窗口创建; 图像显示; 图像保存; 资源释放。
cv2.imread()、cv2.namedWindow()、cv2.imshow()、cv2.imwrite()、cv2.destroyWindow()、cv2.destroyAllWindows()、 cv2.imshow()、cv2.cvtColor()、cv2.imwrite()、cv2.waitKey()。VideoCapture 类,该类常用的方法有:open() 函数; isOpened() 函数; release() 函数; grab() 函数; retrieve() 函数; get() 函数; set() 函数;
VideoWriter 类,用于保存视频文件。Point 类、Rect 类、Size 类、Scalar 类,除此之外,在 Python 中用 numpy 对图像进行操作,所以 numpy 相关的知识点,建议提前学习,效果更佳。cv2.line(); cv2.circle(); cv2.rectangle(); cv2.ellipse(); cv2.fillPoly(); cv2.polylines(); cv2.putText()。
cv2.setMouseCallback() ,滑动条涉及两个函数,分别是:cv2.createTrackbar() 和 cv2.getTrackbarPos()。cv2.split(),通道合并函数 cv2.merge()。cv2.add(); cv2.addWeighted(); cv2.subtract(); cv2.absdiff(); cv2.bitwise_and(); cv2.bitwise_not(); cv2.bitwise_xor()。
图像缩放 cv2.resize(); 图像平移 cv2.warpAffine(); 图像旋转 cv2.getRotationMatrix2D(); 图像转置 cv2.transpose(); 图像镜像 cv2.flip(); 图像重映射 cv2.remap()。
非线性滤波:中值滤波、双边滤波,
方框滤波 cv2.boxFilter(); 均值滤波 cv2.blur(); 高斯滤波 cv2.GaussianBlur(); 中值滤波 cv2.medianBlur(); 双边滤波 cv2.bilateralFilter()。
固定阈值:cv2.threshold(); 自适应阈值:cv2.adaptiveThreshold()。
消除噪声; 分割独立元素或连接相邻元素; 寻找图像中的明显极大值、极小值区域; 求图像的梯度;
膨胀 cv2.dilate(); 腐蚀 cv2.erode()。
cv2.morphologyEx() 函数进行操作。滤波:滤出噪声対检测边缘的影响 ; 增强:可以将像素邻域强度变化凸显出来—梯度算子 ; 检测:阈值方法确定边缘 ;
Canny 算子,Canny 边缘检测函数 cv2.Canny(); Sobel 算子,Sobel 边缘检测函数 cv2.Sobel(); Scharr 算子,Scharr 边缘检测函数 cv2.Scahrr() ; Laplacian 算子,Laplacian 边缘检测函数 cv2.Laplacian()。
标准霍夫变换、多尺度霍夫变换 cv2.HoughLines() ; 累计概率霍夫变换 cv2.HoughLinesP() ; 霍夫圆变换 cv2.HoughCricles() 。
matplotlib 模块对直方图进行绘制。计算直方图用到的函数是 cv2.calcHist()。直方图均衡化 cv2.equalizeHist(); 直方图对比 cv2.compareHist(); 反向投影 cv2.calcBackProject()。
模板匹配 cv2.matchTemplate(); 矩阵归一化 cv2.normalize(); 寻找最值 cv2.minMaxLoc()。
查找轮廓 cv2.findContours(); 绘制轮廓 cv2.drawContours() 。
寻找凸包 cv2.convexHull() 与 凸性检测 cv2.isContourConvex(); 轮廓外接矩形 cv2.boundingRect(); 轮廓最小外接矩形 cv2.minAreaRect(); 轮廓最小外接圆 cv2.minEnclosingCircle(); 轮廓椭圆拟合 cv2.fitEllipse(); 逼近多边形曲线 cv2.approxPolyDP(); 计算轮廓面积 cv2.contourArea(); 计算轮廓长度 cv2.arcLength(); 计算点与轮廓的距离及位置关系 cv2.pointPolygonTest(); 形状匹配 cv2.matchShapes()。
cv2.watershed() 。cv2.inpaint(),学习完毕可以尝试人像祛斑应用。GrabCut 算法 cv2.grabCut(); 漫水填充算法 cv2.floodFill(); Harris 角点检测 cv2.cornerHarris(); Shi-Tomasi 角点检测 cv2.goodFeaturesToTrack(); 亚像素角点检测 cv2.cornerSubPix()。
“FAST” FastFeatureDetector; “STAR” StarFeatureDetector; “SIFT” SIFT(nonfree module) Opencv3 移除,需调用 xfeature2d 库; “SURF” SURF(nonfree module) Opencv3 移除,需调用 xfeature2d 库; “ORB” ORB Opencv3 移除,需调用 xfeature2d 库; “MSER” MSER; “GFTT” GoodFeaturesToTrackDetector; “HARRIS” (配合 Harris detector); “Dense” DenseFeatureDetector; “SimpleBlob” SimpleBlobDetector。
meanShift, camShift,粒子滤波, 光流法 等。meanShift 跟踪算法 cv2.meanShift(); CamShift 跟踪算法 cv2.CamShift()。
人脸检测:从图像中找出人脸位置并标识; 人脸识别:从定位到的人脸区域区分出人的姓名或其它信息; 机器学习。
———————End———————
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!

↓点击阅读原文
爱我就请给我在看
原文标题:【AI简报第20230217期】超越GPT 3.5的小模型来了!AI网恋诈骗时代开启
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- RT-Thread
-
AI模型的配置AI模型该怎么做?2025-10-14 385
-
AI赋能6G与卫星通信:开启智能天网新时代2025-10-11 3885
-
适用于数据中心和AI时代的800G网络2025-03-25 2709
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1521
-
微软发布phi-3AI模型,性能超越GPT-3.52024-04-23 1242
-
Anthropic推出Claude 3系列模型,全面超越GPT-4,树立AI新标杆2024-03-05 1375
-
【嵌入式AI简报20231117期】面对未来AI的三大挑战!2023-11-17 2220
-
【第20231110期嵌入式AI简报】OpenAI 如何再次让 AI 圈一夜未眠?2023-11-10 2573
-
【AI简报20230602】能听懂语音的ChatGPT来了!***开发调查报告发布2023-06-05 2079
-
【AI 简报 202305269期】谨防AI诈骗!避免AI合成歌手的使用不侵犯个人知识产权2023-05-27 2223
-
【AI简报20230522期】ChatGPT App 来了!谷歌大模型PaLM 2细节遭曝光2023-05-22 2200
-
【AI简报20230407期】 MLPref放榜!大模型时代算力领域“潜力股”浮出水面、CV或迎来GPT-3时刻2023-04-08 3788
-
ChatGPT:AI模型框架研究2023-03-29 1124
-
超越GPT 3.5的小型语言模型案例概述2023-02-27 1292
全部0条评论

快来发表一下你的评论吧 !
