

分享一个不错的基于深度学习的车牌检测系统设计
描述
概述
基于深度学习的车牌识别,其中,车辆检测网络直接使用YOLO侦测。而后,才是使用网络侦测车牌与识别车牌号。
车牌的侦测网络,采用的是resnet18,网络输出检测边框的仿射变换矩阵,可检测任意形状的四边形。
车牌号序列模型,采用Resnet18+transformer模型,直接输出车牌号序列。
数据集上,车牌检测使用CCPD 2019数据集,在训练检测模型的时候,会使用程序生成虚假的车牌,覆盖于数据集图片上,来加强检测的能力。
车牌号的序列识别,直接使用程序生成的车牌图片训练,并佐以适当的图像增强手段。模型的训练直接采用端到端的训练方式,输入图片,直接输出车牌号序列,损失采用CTCLoss。
一、网络模型
1、车牌的侦测网络模型:
网络代码定义如下:
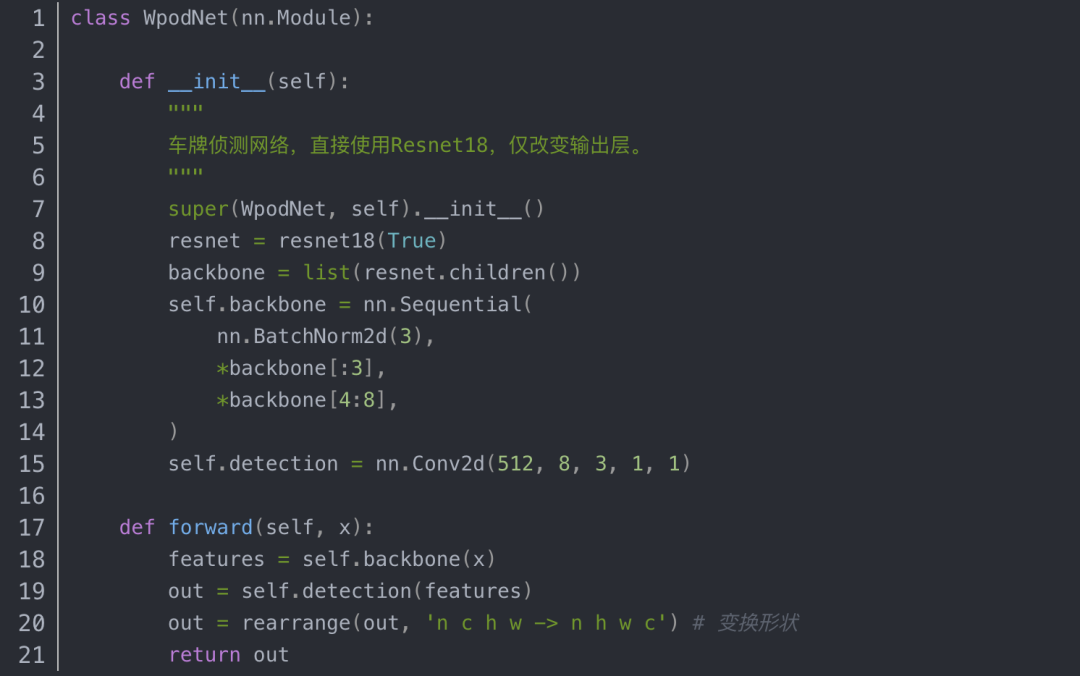
该网络,相当于直接对图片划分cell,即在16X16的格子中,侦测车牌,输出的为该车牌边框的反射变换矩阵。
2、车牌号的序列识别网络:
车牌号序列识别的主干网络:采用的是ResNet18+transformer,其中有ResNet18完成对图片的编码工作,再由transformer解码为对应的字符。
网络代码定义如下:
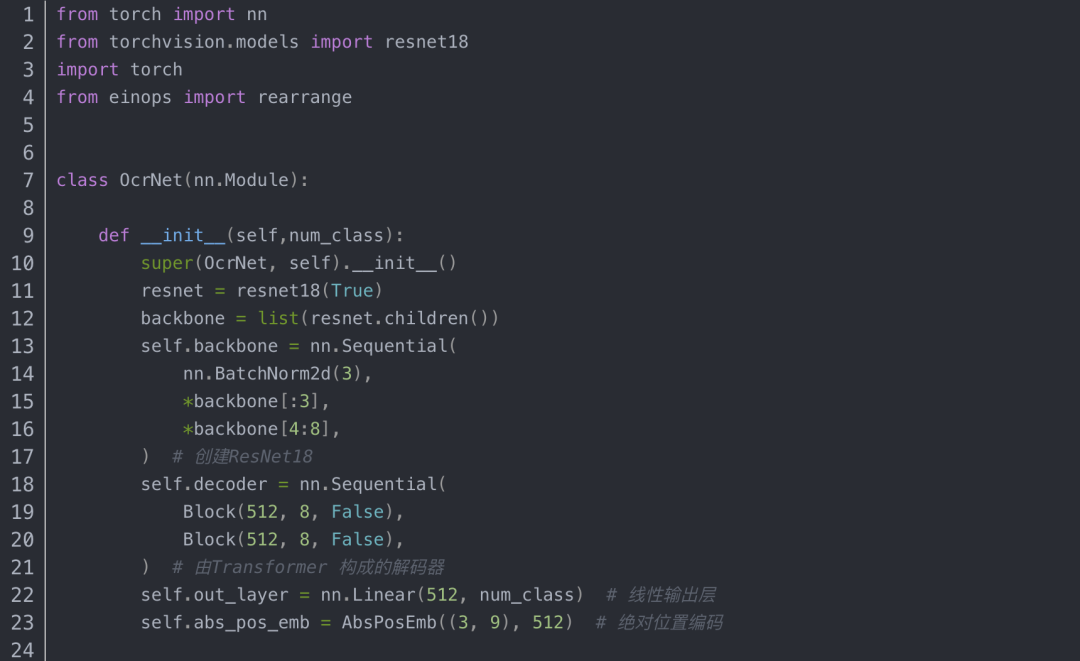

其中的Block类的代码如下:
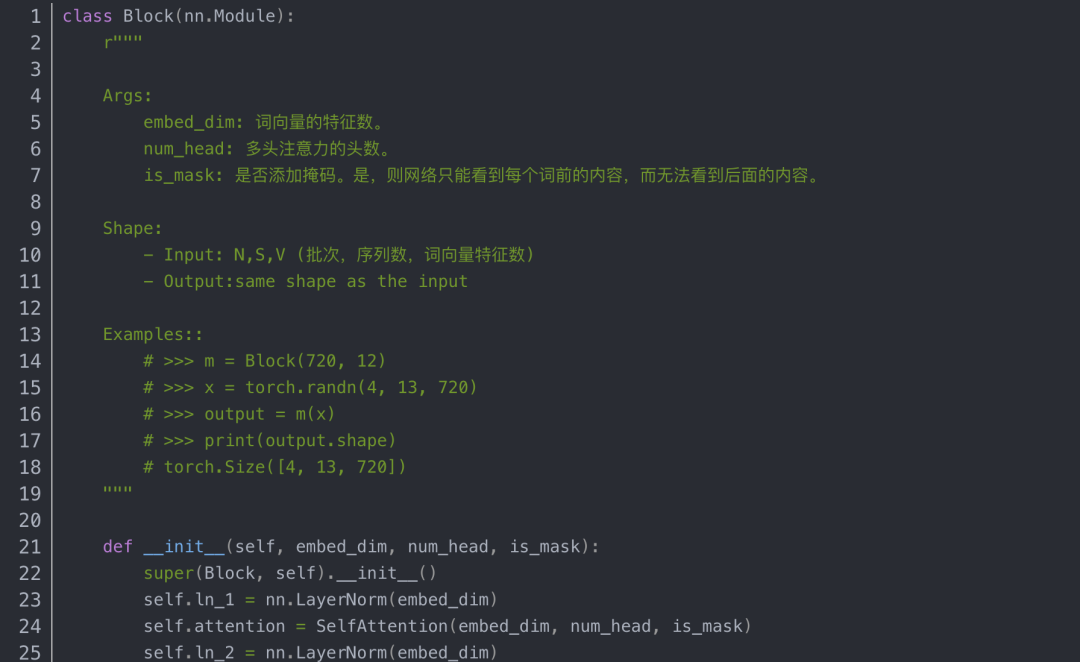
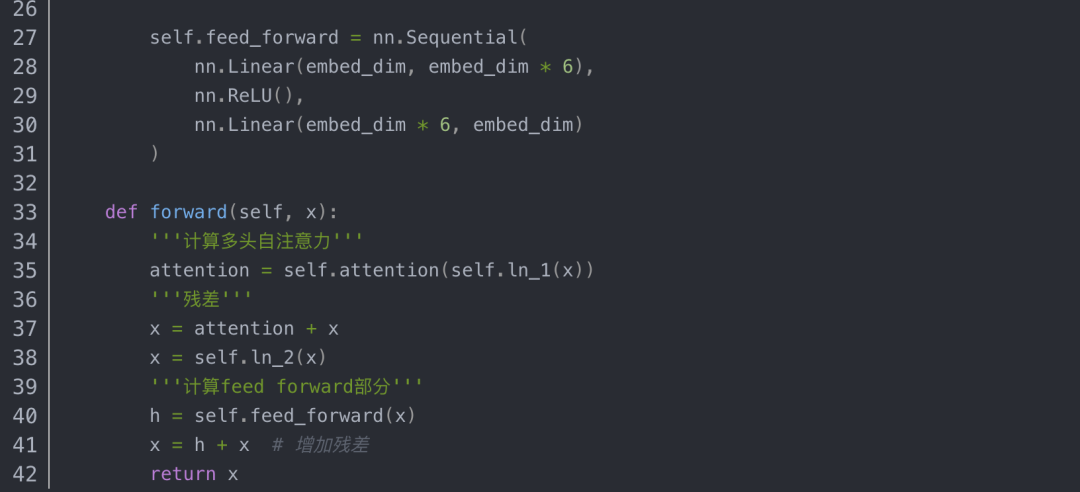
位置编码的代码如下:
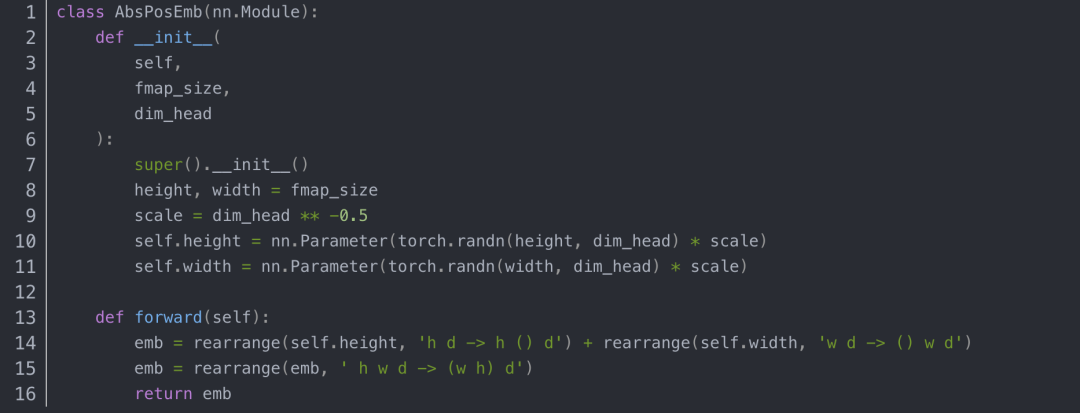
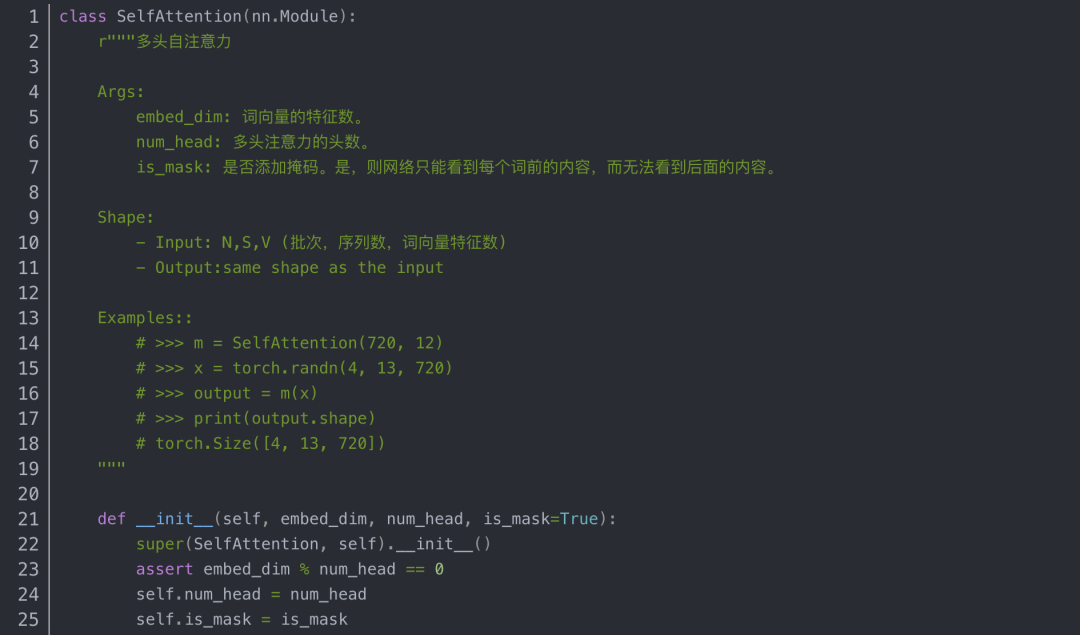
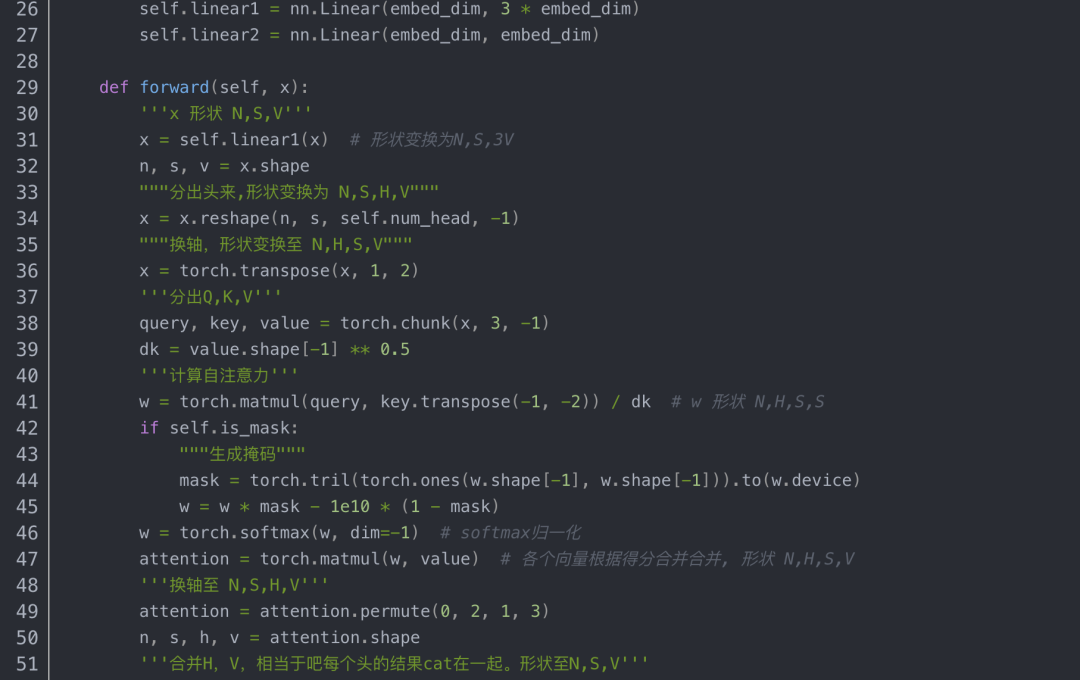
Block类使用的自注意力代码如下:

二、数据加载
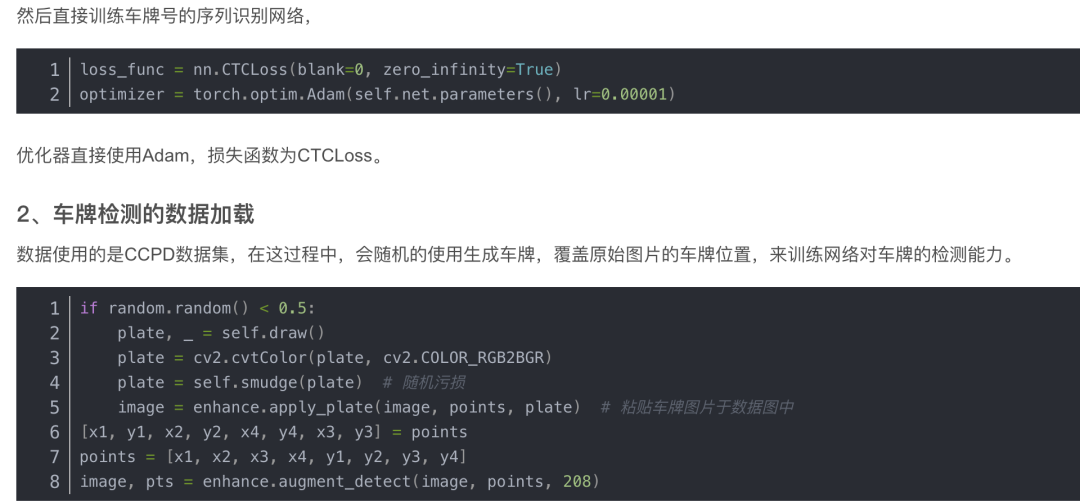
1、车牌号的数据加载
同过程序生成一组车牌号:

再通过数据增强,
主要包括:


三、训练
分别训练即可
其中,侦测网络的损失计算,如下:
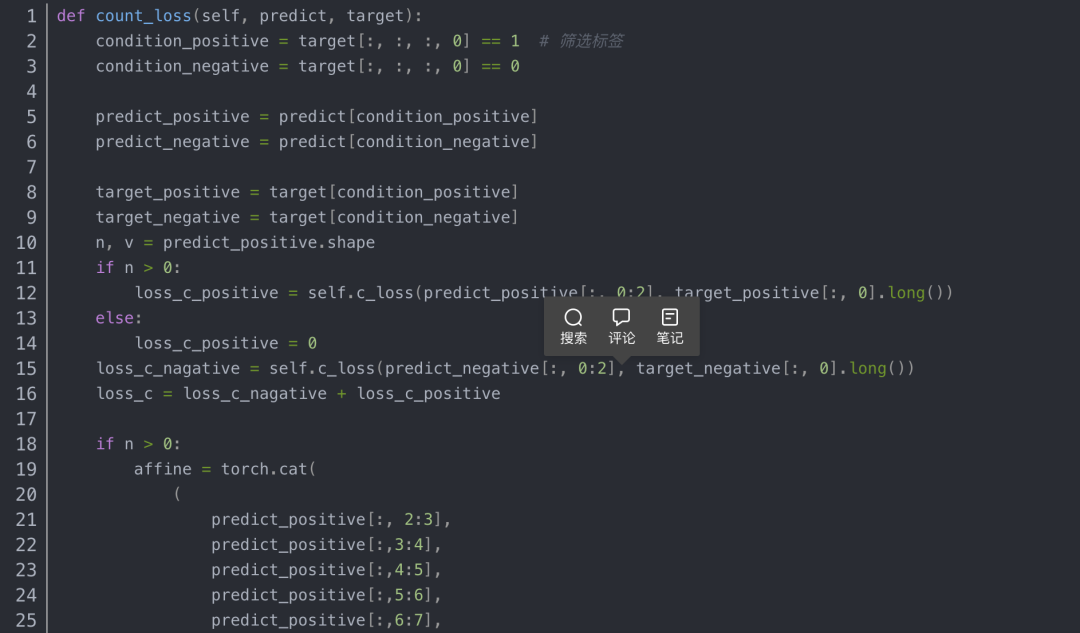
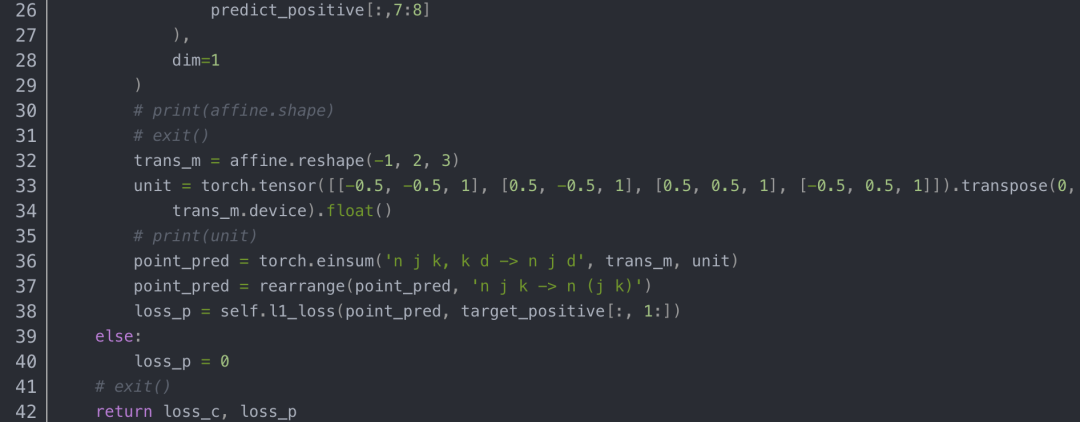
侦测网络输出的反射变换矩阵,但对车牌位置的标签给的是四个角点的位置,所以需要响应转换后,做损失。其中,该cell是否有目标,使用CrossEntropyLoss,而对车牌位置损失,采用的则是L1Loss。
四、推理
1、侦测网络的推理
按照一般侦测网络,推理即可。只是,多了一步将反射变换矩阵转换为边框位置的计算。
另外,在YOLO侦测到得测量图片传入该级进行车牌检测的时候,会做一步操作。代码见下,将车辆检测框的图片扣出,然后resize到长宽均为16的整数倍。

2、序列检测网络的推理
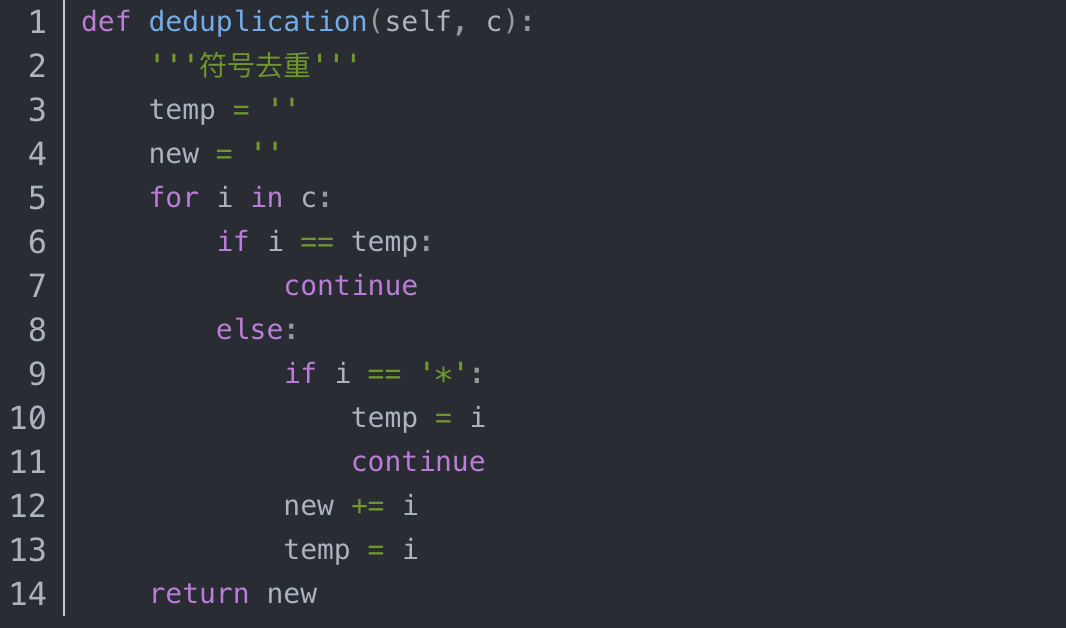
对网络输出的序列,进行去重操作即可,如间隔标识符为“*”时:
完整代码
https://github.com/HibikiJie/LicensePlate
审核编辑:陈陈
-
【TL6748 DSP申请】车牌检测系统2015-10-09 1745
-
【超值干货】 揭秘车牌识别算法2017-05-25 7826
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 4385
-
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计2020-09-25 1048
-
基于深度学习的异常检测的研究方法2021-07-12 1672
-
射频系统的深度学习【回映分享】2022-01-05 6548
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 28299
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2173
-
【KV260视觉入门套件试用体验】六、VITis AI车牌检测&车牌识别2023-09-26 9461
-
如何使用深度学习进行视频行人目标检测2018-11-19 1937
-
如何使用Python应用软件实现车牌检测和识别2020-02-03 4706
-
车牌检测系统2022-12-13 637
-
基于深度学习的车牌识别侦测网络模型2023-02-19 1508
-
基于深度学习的小目标检测2024-07-04 3116
-
基于AI深度学习的缺陷检测系统2024-07-08 3927
全部0条评论

快来发表一下你的评论吧 !
