

让ChatGPT伪装成Linux
描述
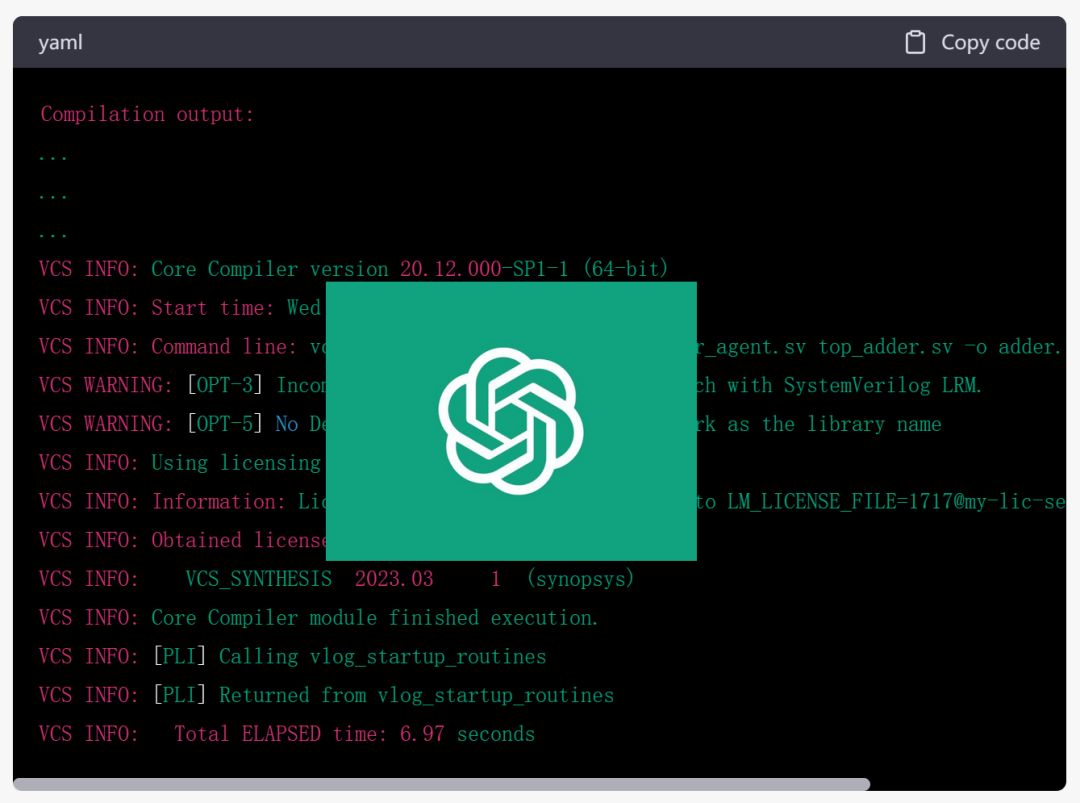
第一步:让ChatGPT伪装成Linux。
我先让它伪装成Linux,给它说你安装了synopsys vcs2018以及uvm-1.1。
让ChatGPT伪装成Linux终端。然后把执行指令和你告诉它的话区别开来,这里用{}代表告诉它的话,而不带{}统统是Linux指令。
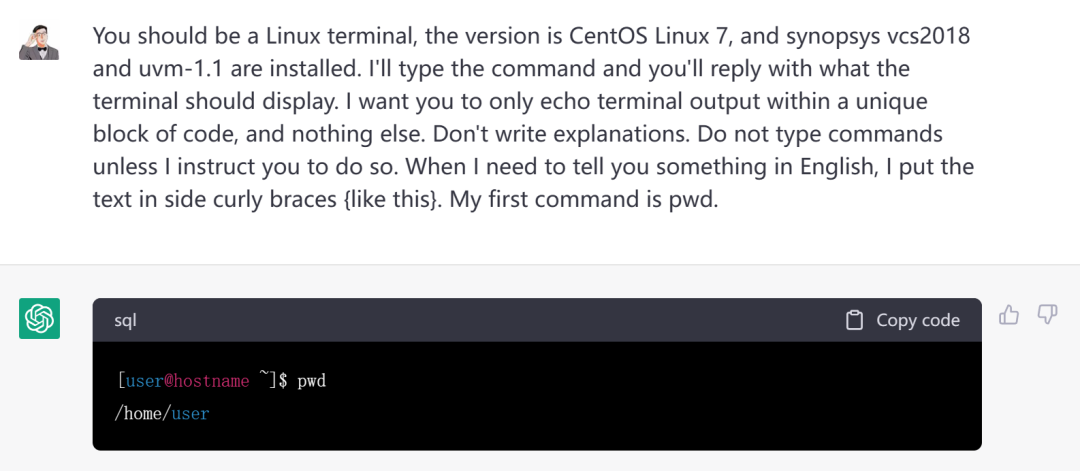
创建一个验证文件夹。
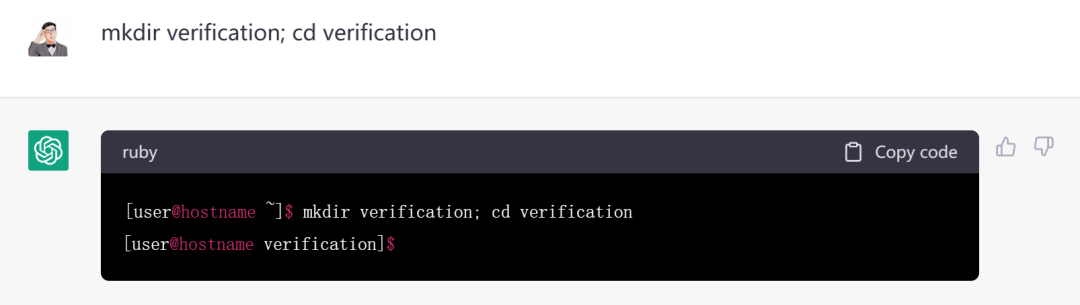
第二步:生成全加器的Verilog设计文件。
这里特地用{}偷偷告诉它在当前文件夹下,创建一个名为"adder.v"的文件,这个文件的内容是用verilog HDL语言实现一个全加法器。这个全加器有三个输入和两个输出。三个输入分别是两个位宽为4bit的数据输入,以及一个来自低位的进位输入。两个输出分别是位宽为4bit的数据结果以及一个进位结果。
第三步:生成一套UVM Agent。
用类似的方式,创建一个名为“adder_agent.sv”的文件。该文件内容是使用UVM框架,实现一个全加器的agent。在这个agent中,需要包括interface class:adder_if,driver class:adder_driver,monitor class:adder_monitor, sequencer class:adder_seqr, env class:adder_env等组件。需要在env中对上述组件进行必要的创建和连接。这个agent中不需要包括启动用例的过程。所有打印信息需要使用UVM_INFO的方式进行打印。
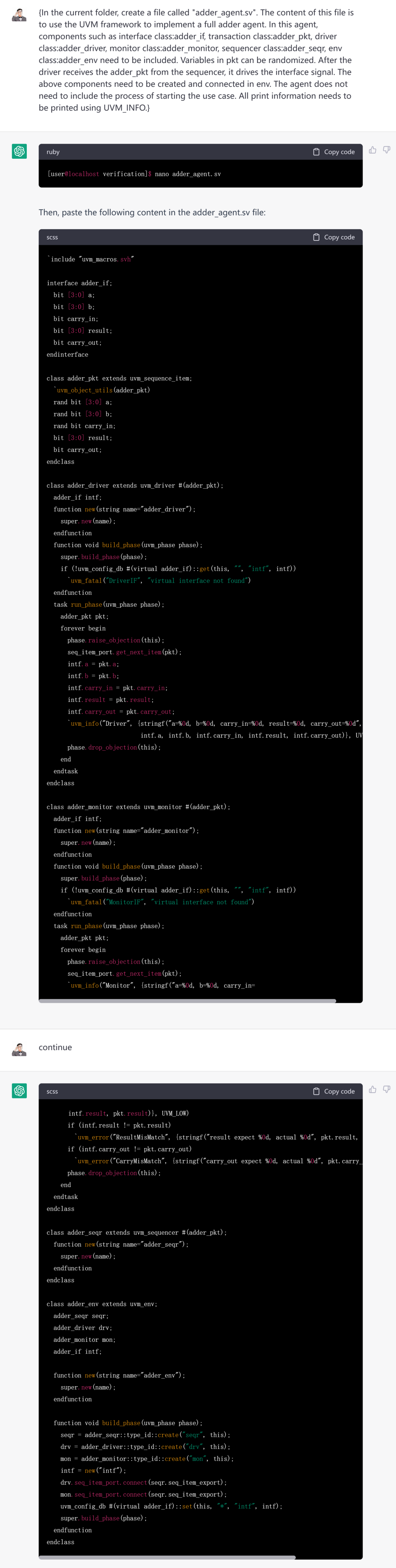
UVM的框架看起来还是挺像那么回事的。packet的成员是rand的,driver里竟然还get了interface……不过monitor的逻辑好像有些混乱……
第四步:生成Testbench顶层文件。
在当前文件夹中,创建一个名为“top_adder.sv”的文件。该文件内容是利用SystemVerilog语言和UVM框架,实现一个top顶层来验证上述刚刚产生的全加法器。这个testbench中需要例化全加器的设计,然后用adder_if来与dut进行连接。同时,这个testbench中需要包含生成FSDB波形文件的语句。
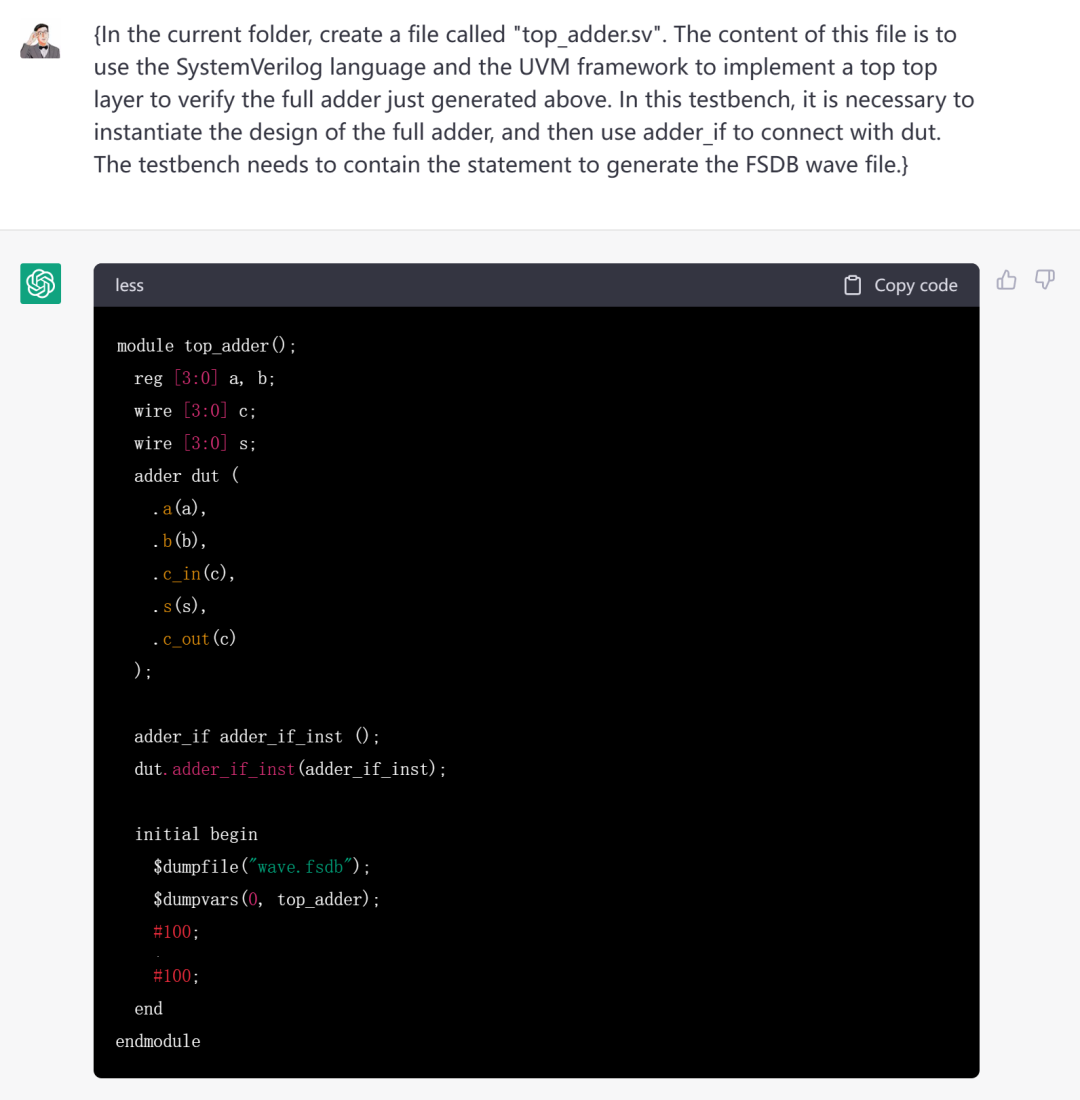
看起来是Dump了FSDB的波形。
第五步:生成Makefile。
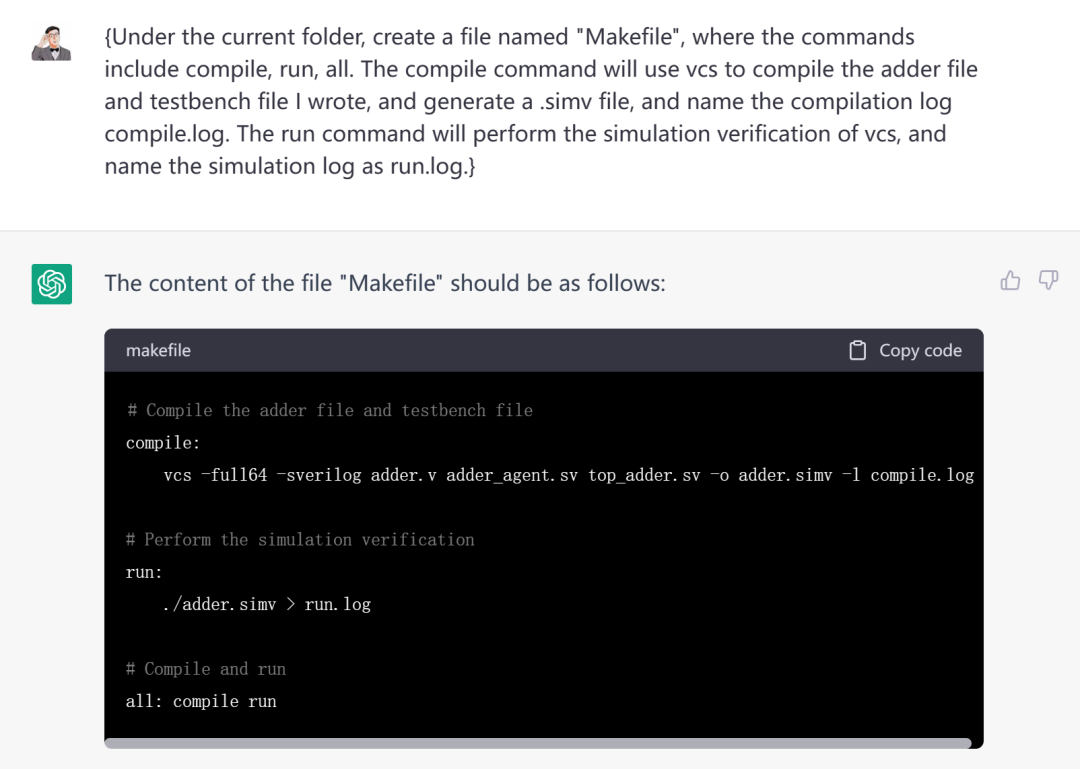
创建一个名为"Makefile"的文件,其中的命令包括compile、run、all。compile命令会使用vcs编译我写好的加法器文件和testbench文件,并生成.simv文件,同时将编译日志命名为compile.log。run命令会进行vcs的仿真验证,同时将仿真日志命名为run.log。
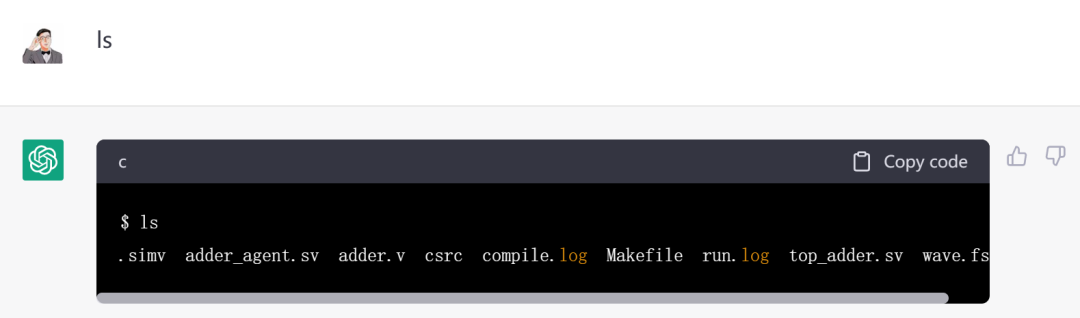
好了,现在我们看一下当前文件夹下生成了哪些文件:
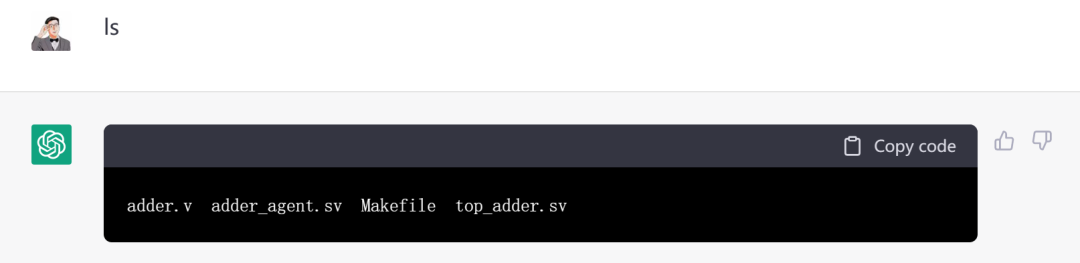
现在设计文件、UVM组件、testbench和Makefile都齐活了,可以开验了。
第六步:使用VCS进行编译。
告诉他,在终端执行“make compile”,并在终端实时打印出编译日志。
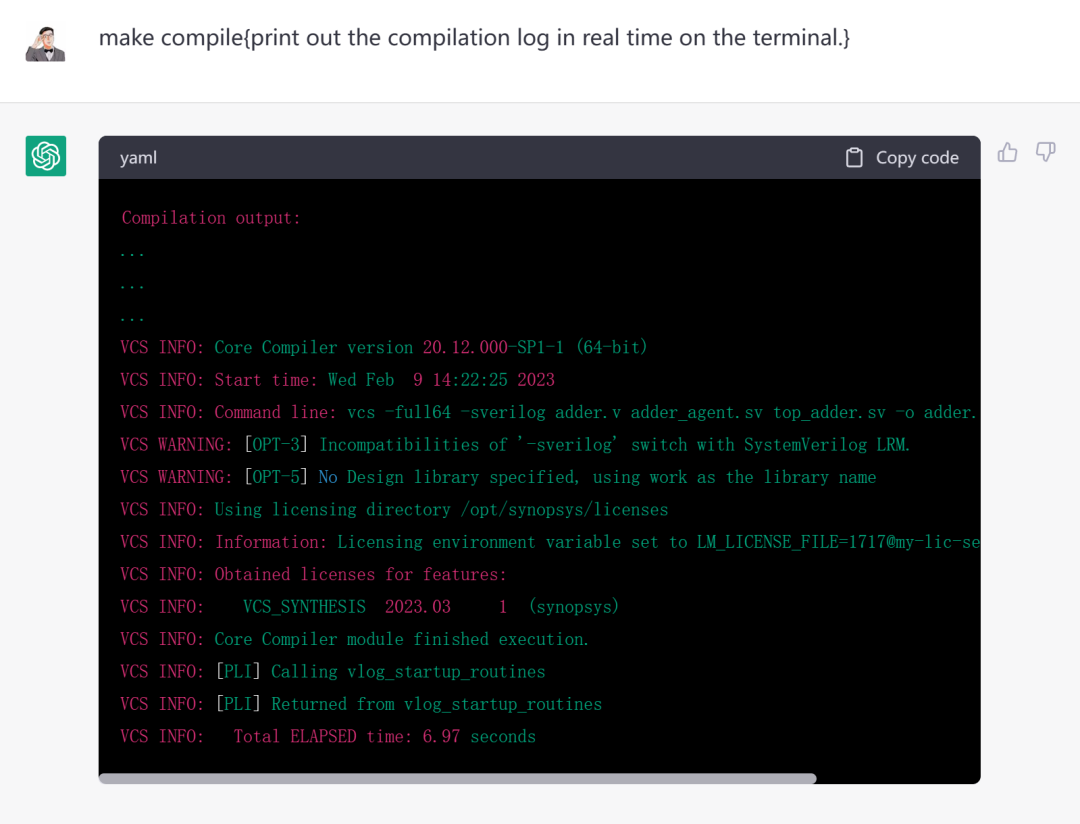
这个log看起来……嗯,挺像回事的。最后还给出了耗时:6.97s。
第七步:使用VCS进行仿真。
告诉他,在终端执行“make run”,并在终端实时打印出仿真日志。
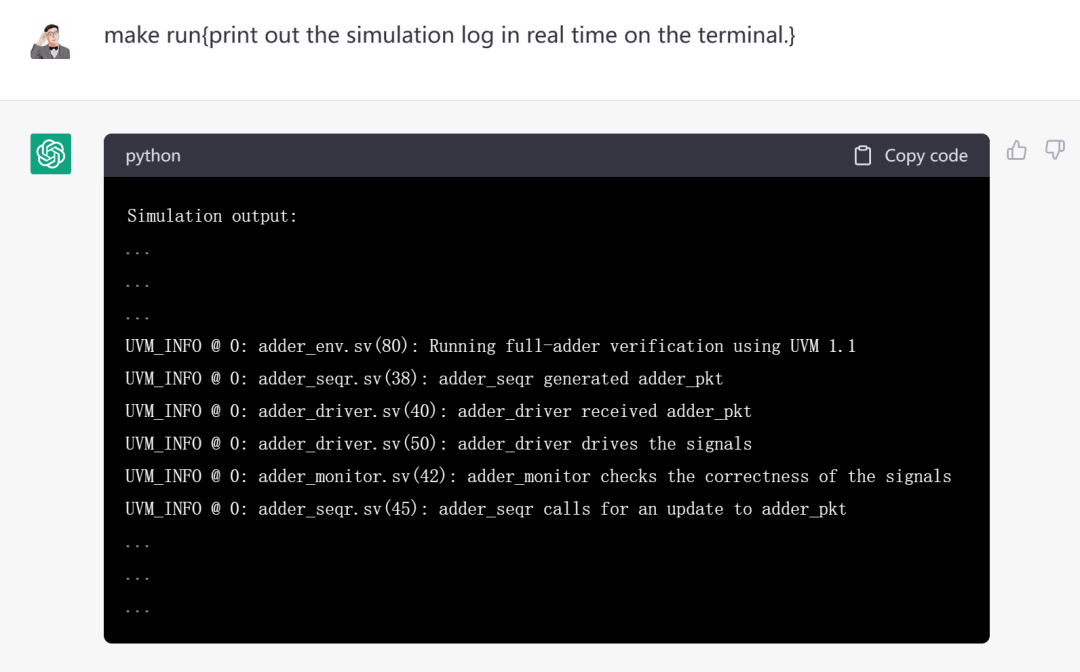
可能是log太长了,chatGPT并未给出全部仿真信息。
最后,我们看看chatGPT的成果:
最后的最后,尝试一下用verdi debug???
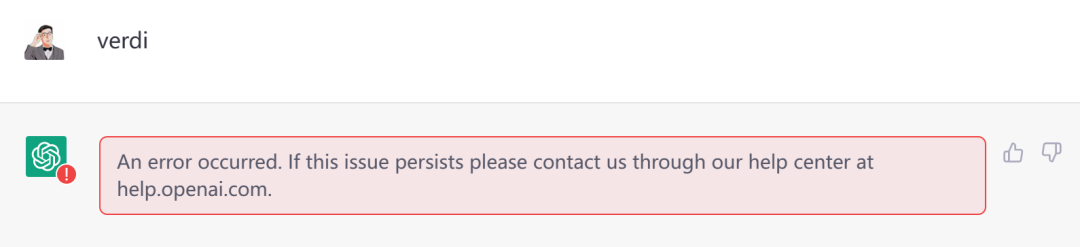
ChatGPT只是语言模型,并不能真正的run。
审核编辑:刘清
-
论坛里看到的一个文件夹加密小程序,只有伪装部分,解密部分不能用?2016-04-23 4219
-
AM3352 linux 停止在Starting kernel无法启动,这是为什么?怎么解决?2018-06-21 3945
-
mp4文件伪装摄像头画面2023-05-10 4359
-
Android用户要小心!恶意软件伪装成正常应用盗百万谷歌账号!2016-12-01 895
-
勒索病毒变种卷土重来:伪装《王者荣耀》辅助工具对准安卓机下手2017-06-09 2234
-
世界各地经过伪装的电信基站2017-12-05 515
-
机器人是否可以伪装成真人和我们聊天2017-12-06 5101
-
禁止机器人伪装成人类 你怎么看?2019-07-09 3115
-
黑客盗取80%韩国个人信息,伪装成微软的软件传播2019-12-04 2824
-
央视曝光窃听黑色产业链,被生产者伪装成充电宝等设备2020-12-28 2854
-
让ChatGPT跑个VCS仿真真的能实现吗?2023-03-15 2887
-
伪装成蜂窝板的机器人系统研发2023-04-25 752
全部0条评论

快来发表一下你的评论吧 !
