

说一下对芯片结构工作的体会
描述
第一篇 回到定义
让我们先从一个小游戏开始,
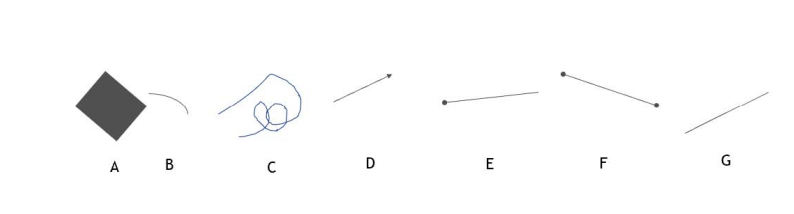
仔细观察上面的几个图形,其中哪些是直线呢?可能很多人会毫不犹豫的回答是”G”。其实,要回答这个问题,我们就要先弄清楚“直线”的定义,直线必须满足三个条件,第一,是直的;第二,是线,也就是必须是一维的,第三,直线没有端点。那么上面有哪个是同时满足这三个条件的图形呢?没有!A不是一维的,B/C不是直的,D/E/F有端点,G不是一维的,因为一维的直线是没有宽度的,而G之所以能够被我们人眼看到,说明它是有宽度的。
这里说这个小游戏的目的是为了引入一种非常重要的思维方式:回到定义。在我看来,我们平时遇到的很多问题,大部分可以通过“回到定义”来获得一个快速的模糊的答案。为了说明这种思维方式的强大之处,我们来看几个问题。
“这件衣服漂亮吗?”
“我做的饭好吃吗?”
“你觉得这个人勇敢吗?”
“你觉得这个事情好不好做?”
“这个解决方案的成本高不高?”
“这个方案和那个方案,哪个好?”
“从这里去公司,开车快还是做地铁快?”
“……”
无论是生活还是工作当中,我们无时无刻都会面临上面类似的问题,这些问题可能来自家人,可能来自同事,也可能来自路人。要回答这些问题,同样,也可以使用“回到定义”的思维方式,当我们弄明白定义之后,以上问题就迎刃而解了。
“什么是漂亮?”
“什么是好吃?”
“怎么定义勇敢?”
“怎么定义好做?”
“成本怎么定义?”
“怎么定义方案的好坏?”
“怎么定义快?”
你会发现,如果我们搞清楚了这几个定义,其实那些问题也就自有答案了。
我们平时的工作,其本质是选择,即,每时每刻要做出有利的选择。针对芯片行业来说,可具体化为我们要选择性能高(P),功耗低(P),面积小(A),复杂度低(C)的方案。一般情况下,大家在这个目标上是没有分歧的,分歧的产生在于每个人对PPAC的预估值不同,或者在于每个人所站的角度不同。然而,一个方案的好坏不止PPAC这四个指标,还有很多其它的参数,有时候也需要考虑进去。还有,上面的提到的“有利的选择”,对不同的人的含义也可能是不同的。最后,以上讨论大多都是基于人是理性的这个假设,然而事实并非如此,这就使事情变得越来越复杂,难以有显而易见的结论。
大道至简,面对这纷繁复杂的多彩世界,我认为“回到定义”是我们可以利用的一把利器,“回到定义”一般不是为了解决某个问题,而是过滤那些价值不大的问题。
第二篇 排列组合
排列组合的本质是降维。
面对一个复杂的问题,当这个问题的复杂性已经超出我们解决问题的能力时,就会变得很棘手。一般情况下,出现这种情况是因为这个问题的维度超过了我们认知的维度,这时,我们可以采用“排列组合”的思维方式来尝试解决。
比如“如何设计一个AI加速器”,这是一个很大的问题,我们可能很难在短时间内得到答案,因为这个问题的复杂性已经超出了很多人的认知范围。这时,我们可以将这个问题进行降维处理,变成多个较简单的,维度低一些的子问题:
“如何设计AI加速器的memory hierarchy?”
“如何设计AI加速器的data path?”
“如何设计AI加速器的control path?”
“如何设计AI加速器的运算单元?”
“如何使以上几个子系统协同工作?”
我们仔细观察发现,以上几个问题是最开始问题的子问题,以及这些子问题之间的关系的问题。也就是原始的问题被降低到了更低的维度。如果发现个别子问题仍然不能解决,那么,可以采用同样的方式,将这个子问题采用“排列组合”进行拆解。这里,我们假设“如何设计AI加速器的运算单元”这个子问题还是太复杂,超出了我们的能力,那么,我们可以进一步将其降维:
“如何设计AI加速器的Tensor processor?”
“如何设计AI加速器的Vector processor?”
“如何设计AI加速器的Scaler processor?”
同样,我们也可以继续拆解:“如何设计AI加速器的Tensor processor?”
“AI加速器的Tensor processor 负责完成哪些功能?”
“AI加速器的Tensor processor 的sequence如何选择?”
“AI加速器的Tensor processor PPA budget是怎样的?”
“AI加速器的Tensor processor 带宽需求是怎样的?”
“AI加速器的Tensor processor 需要的data format是怎样的?”
“……”
每个人解决问题的能力不同,所需要拆解到的问题的维度也不同,能力强的人,需要拆解的层数少一些,能力弱一些的人,可能需要将问题拆解到较低的维度时才能解决。
排列组合,除了可以将问题降维之外,还可以弥补脑容量不足所带来的问题。平时工作当中,有一类问题难度太高,一时无法下手,可以采用排列组合来解决,正如上面刚刚提到的例子;还有另外一类问题,其本身难度并不高,在我们解决问题能力范围之内,但问题比较繁杂,怎奈脑容量有限,一时难以将所有情况都考虑周全。对于这样的问题,也可以采用“排列组合”来防止遗漏。这个时候,“好记性不如烂笔头”就会发挥作用,当我们列出所有排列组合之后,然后用大脑依次分析,就能得出结论了。
第三篇 论数据
当今时代是一个信息爆炸的时代,天量的数据无时无刻的被生产,收集,传播开来,数据分析与筛选技能已经是一个人最基本的技能之一了,经过常年的学习与训练,关于数据的能力很多都已经变成了我们的前意识记忆,甚至是在非意识范围内影响着我们。这一点对于IT从业者尤其明显,在平时的工作中,无论是谁,每天都会面临很多“选择题”,而我们要做出选择,大多是出于理性的,而理性本身需要数据支撑。
“为什么采用这个方案,有什么好处吗?”
“这个方案的PPAC怎么样?”
“如果采用这个方案,会有什么代价?”
“……”
在做出以上选择之前,大多需要准备一些数据,而一个没有任何数据支撑的问题的决定能力是一个人重要的技能,对两个或者多个方案,数据上难分伯仲时的决策能力也是一个人重要的技能。
另外,数据有结论之前的数据和结论之后的数据之分。前者使我们自信,后者使我们开心。全面的数据使我们柳暗花明又一村,走出泥潭,片面的数据使我们不识庐山真面目,误入歧途。“实事求是,不先入为主”是SOL, “求全责备,所有决定都要有数据支撑”也是SOL,需要知道的是SOL我们人类做不到的。
给纷繁的世界建模以获取数据是困难的,在天量的数据中做出正确的决定也是不易的。数据不会骗人,骗人的是使用数据的人而已。我建议的是,工作中80%的决定要基于收集到的数据,20%的决定要基于内心。生活中20%的决定要基于收集到的数据,80%的决定要基于内心。类似模拟退火。理性是可贵的,但感性也不是一文不值。智慧是好的,但我们也不能倚靠自己的聪明。追求完美,大多数情况是褒义词,但有时候也可以是贬义词。
第四篇 正反合(A=A=!A)
A=A=!A这个式子可以先拆成两个简单一点的式子来看:
A=A 和A=!A,为了便于描述,我称第一个式子为“A向左运动”,第二个叫“A向右运动”。
无论是在工作还是在生活中,我们的核心工作就是解决这样或那样的问题。以上提到的几种方法之所以有用,很大程度上是因为我们发现了问题的矛盾点。如果把“A向左运动”看成是“证明方案A是对的(矛)”的话,那么“A向右运动”就是“证明方案A是错的(盾)”。矛与盾相互否定,推动盾与矛互相肯定,这个过程反复出现,实现了问题的瓦解,即,问题的解决,达到了新的稳态,新的合理,新的存在。
比如,我们要新加一个具体的feature,最开始,我们会提出一个方案,假设就叫方案A,方案A的提出过程,其实就是“A向左运动”,这个过程中,最重要的是要确定“方案A确实可以解决这个问题”,就是A的肯定。一旦方案A提出之后,随之而来的是“为什么方案A有这个缺点”或者“为什么不选择方案B”,这个过程就是“A向右运动”的过程,即方案A的否定。接下来,就又是“A的肯定”过程,即,要完善最开始的方案A,完善之后可能还有反对者提出问题,如此往复,经过几个回合的拉锯之后,方案A渐趋成熟,而这时方案A还是方案A,方案A也是方案A的否定了。“追求无我,成就自我”,“无知者是不自由的”,每一次的否定自我,就是一次自我的肯定,每一次的自我肯定,都是向对立陌生的一次前进。
A=A=!A就是“正”,“反”,过程是螺旋上升的,目的是“合”。然而,世界是复杂的,我们偶尔也会遇到一时没有矛盾,但仍然需要我们解决的问题,这个时候,用我们人类最柔软的内心与这个问题握手。
第五篇 关于芯片架构
以上讨论了几种个人解决实际问题的方式方法,接下来说一下对芯片结构工作的体会。
芯片架构,大体上可分为三个事情:Architecture, Algorithm和Association。显然,架构工作,是要生产一些架构(Architecture)作为产品的,作为设计人员的参考与指导。架构本身并不是无根之木,是需要一些数据支撑的,而这数据的来源,主要是算法分析,所以架构工作还应包括一些算法分析的内容,此外,为了发挥所做架构的效力,应该提供一些基本的工具来帮助用户。
三者之间,相辅相成,不同阶段,不同情况,重要程度不同。算法分析者可以提供必要的信息,比如算法发展趋势,所关心领域算法特点等重要内容,架构者基于这些内容,可以提出合适的硬件架构来,而另外一些人可以提供合适的工具来弥补架构和客户之间的gap。三者之间不是单向影响的,是互相关联的,架构者可以提出在做架构时的痛点,以影响算法发展和工具提供者。
芯片架构工作,很像是玩打地鼠游戏,目的不是把从某个洞里出来的地鼠全部打死,而是能够权衡,使总体得分最高,而权衡中的原则是,如果自己与非自己有冲突时,或者正义与利益有冲突时,尽量使非自己开心。
审核编辑:刘清
-
求大神说一下bais-tee的工作原理说一下2015-09-01 6174
-
那位大侠能讲一下EA1530芯片工作原理。2015-12-16 3405
-
说一下逆变驱动电路2021-11-11 1415
-
介绍一下机电暂态开源工具使用过程中的一些体会2021-12-30 1372
-
可以分享一下RXD管脚的内部结构吗?2023-03-27 589
-
小米6定了!小米:有件大事提前说一下2017-04-11 760
-
介绍一下ARCore的基本概念并剖析其工作机理2018-01-24 7095
-
宏碁智能佛珠了解一下2018-08-08 4309
-
电磁炉加热一下就停一下什么原因及解决办法2020-03-18 289886
-
电磁炉加热一下就停一下什么原因2021-06-04 42365
-
管窥一下汽车这样的“自控力”是如何实现的2021-03-30 2517
-
何谓延时电路?介绍一下6种延时电路工作原理2021-05-18 25738
-
说一下模拟信号与数字信号的区别2023-05-15 10030
-
一个亿,啪一下就没了!2022-06-02 1596
-
介绍一下芯片的VIA pillar2023-12-06 2275
全部0条评论

快来发表一下你的评论吧 !
