

10种聚类算法和Python代码1
电子说
描述
分享一篇关于聚类的文章: 10种聚类算法和Python代码 。文末提供jupyter notebook的完整代码获取方式。
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。
有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 python 中安装和使用顶级聚类算法。
完成本教程后,你将知道:
- 聚类是在输入数据的特征空间中查找自然组的无监督问题。
- 对于所有数据集,有许多不同的聚类算法和单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适配和使用顶级聚类算法。
教程概述
本教程分为三部分:
- 聚类
- 聚类算法
- 聚类算法示例
- 库安装
- 聚类数据集
- 亲和力传播
- 聚合聚类
- BIRCH
- DBSCAN
- K-均值
- Mini-Batch K-均值
- Mean Shift
- OPTICS
- 光谱聚类
- 高斯混合模型
一、聚类
聚类分析,即聚类,是一项无监督的机器学习任务。它包括自动发现数据中的自然分组。与监督学习(类似预测建模)不同,聚类算法只解释输入数据,并在特征空间中找到自然组或群集。
聚类技术适用于没有要预测的类,而是将实例划分为自然组的情况。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
群集通常是特征空间中的密度区域,其中来自域的示例(观测或数据行)比其他群集更接近群集。群集可以具有作为样本或点特征空间的中心(质心),并且可以具有边界或范围。
这些群集可能反映出在从中绘制实例的域中工作的某种机制,这种机制使某些实例彼此具有比它们与其余实例更强的相似性。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
聚类可以作为数据分析活动提供帮助,以便了解更多关于问题域的信息,即所谓的模式发现或知识发现。例如:
- 该进化树可以被认为是人工聚类分析的结果;
- 将正常数据与异常值或异常分开可能会被认为是聚类问题;
- 根据自然行为将集群分开是一个集群问题,称为市场细分。
聚类还可用作特征工程的类型,其中现有的和新的示例可被映射并标记为属于数据中所标识的群集之一。虽然确实存在许多特定于群集的定量措施,但是对所识别的群集的评估是主观的,并且可能需要领域专家。通常,聚类算法在人工合成数据集上与预先定义的群集进行学术比较,预计算法会发现这些群集。
聚类是一种无监督学习技术,因此很难评估任何给定方法的输出质量。
—源自:《机器学习页:概率观点》2012。
二、聚类算法
有许多类型的聚类算法。许多算法在特征空间中的示例之间使用相似度或距离度量,以发现密集的观测区域。因此,在使用聚类算法之前,扩展数据通常是良好的实践。
聚类分析的所有目标的核心是被群集的各个对象之间的相似程度(或不同程度)的概念。聚类方法尝试根据提供给对象的相似性定义对对象进行分组。
—源自:《统计学习的要素:数据挖掘、推理和预测》,2016年
一些聚类算法要求您指定或猜测数据中要发现的群集的数量,而另一些算法要求指定观测之间的最小距离,其中示例可以被视为“关闭”或“连接”。因此,聚类分析是一个迭代过程,在该过程中,对所识别的群集的主观评估被反馈回算法配置的改变中,直到达到期望的或适当的结果。scikit-learn 库提供了一套不同的聚类算法供选择。下面列出了10种比较流行的算法:
- 亲和力传播
- 聚合聚类
- BIRCH
- DBSCAN
- K-均值
- Mini-Batch K-均值
- Mean Shift
- OPTICS
- 光谱聚类
- 高斯混合
每个算法都提供了一种不同的方法来应对数据中发现自然组的挑战。没有最好的聚类算法,也没有简单的方法来找到最好的算法为您的数据没有使用控制实验。
在本教程中,我们将回顾如何使用来自 scikit-learn 库的这10个流行的聚类算法中的每一个。这些示例将为您复制粘贴示例并在自己的数据上测试方法提供基础。我们不会深入研究算法如何工作的理论,也不会直接比较它们。让我们深入研究一下。
三、聚类算法示例
在本节中,我们将回顾如何在 scikit-learn 中使用10个流行的聚类算法。这包括一个拟合模型的例子和可视化结果的例子。这些示例用于将粘贴复制到您自己的项目中,并将方法应用于您自己的数据。
1、库安装
首先,让我们安装库。不要跳过此步骤,因为你需要确保安装了最新版本。你可以使用 pip Python 安装程序安装 scikit-learn 存储库,如下所示:
sudo pip install scikit-learn
接下来,让我们确认已经安装了库,并且您正在使用一个现代版本。运行以下脚本以输出库版本号。
# 检查 scikit-learn 版本
import sklearn
print(sklearn.__version__)
运行该示例时,您应该看到以下版本号或更高版本。
0.22.1
2、聚类数据集
我们将使用 make _ classification ()函数创建一个测试二分类数据集。数据集将有1000个示例,每个类有两个输入要素和一个群集。这些群集在两个维度上是可见的,因此我们可以用散点图绘制数据,并通过指定的群集对图中的点进行颜色绘制。
这将有助于了解,至少在测试问题上,群集的识别能力如何。该测试问题中的群集基于多变量高斯,并非所有聚类算法都能有效地识别这些类型的群集。因此,本教程中的结果不应用作比较一般方法的基础。下面列出了创建和汇总合成聚类数据集的示例。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
%matplotlib inline
# 定义数据集
X, y = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):
# 获取此类的示例的行索引
row_ix = where(y == class_value)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例将创建合成的聚类数据集,然后创建输入数据的散点图,其中点由类标签(理想化的群集)着色。我们可以清楚地看到两个不同的数据组在两个维度,并希望一个自动的聚类算法可以检测这些分组。
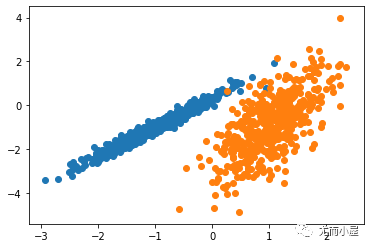
图:已知聚类着色点的合成聚类数据集的散点图
接下来,我们可以开始查看应用于此数据集的聚类算法的示例。我已经做了一些最小的尝试来调整每个方法到数据集。
-
如何在 Python 中安装和使用顶级聚类算法2023-05-22 1797
-
10种聚类算法和Python代码22023-02-20 1846
-
10种顶流聚类算法Python实现(附完整代码)2023-01-07 3025
-
10种聚类介绍和Python代码2022-07-30 9328
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 838
-
一种自适应的关联融合聚类算法2021-04-01 1677
-
如何在python中安装和使用顶级聚类算法?2021-03-12 3238
-
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述2018-05-27 31959
-
基于密度DBSCAN的聚类算法2018-04-26 22978
-
一种新的基于流行距离的谱聚类算法2017-12-07 1014
-
一种改进的BIRCH算法聚类方法2017-11-10 932
-
聚类算法及聚类融合算法研究2011-08-10 1098
-
基于关联规则与聚类算法的查询扩展算法2009-10-17 626
全部0条评论

快来发表一下你的评论吧 !
