

10种聚类算法和Python代码2
电子说
描述
3、亲和力传播
亲和力传播包括找到一组最能概括数据的范例。
我们设计了一种名为“亲和传播”的方法,它作为两对数据点之间相似度的输入度量。在数据点之间交换实值消息,直到一组高质量的范例和相应的群集逐渐出现
—源自:《通过在数据点之间传递消息》2007。
它是通过 AffinityPropagation 类实现的,要调整的主要配置是将“ 阻尼 ”设置为0.5到1,甚至可能是“首选项”。
下面列出了完整的示例。
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法取得良好的结果。
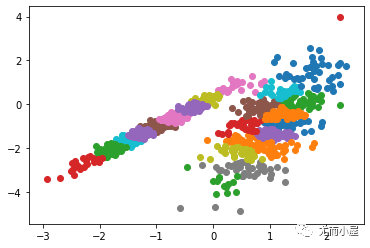
图:数据集的散点图,具有使用亲和力传播识别的聚类
4、聚合聚类
聚合聚类涉及合并示例,直到达到所需的群集数量为止。它是层次聚类方法的更广泛类的一部分,通过 AgglomerationClustering 类实现的,主要配置是“ n _ clusters ”集,这是对数据中的群集数量的估计,例如2。下面列出了完整的示例。
# 聚合聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组。

图:使用聚集聚类识别出具有聚类的数据集的散点图
5、BIRCH
BIRCH 聚类( BIRCH 是平衡迭代减少的缩写,聚类使用层次结构)包括构造一个树状结构,从中提取聚类质心。
BIRCH 递增地和动态地群集传入的多维度量数据点,以尝试利用可用资源(即可用内存和时间约束)产生最佳质量的聚类。
—源自:《 BIRCH :1996年大型数据库的高效数据聚类方法》
它是通过 Birch 类实现的,主要配置是“ threshold ”和“ n _ clusters ”超参数,后者提供了群集数量的估计。下面列出了完整的示例。
# birch聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 适配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个很好的分组。

图:使用BIRCH聚类确定具有聚类的数据集的散点图
-
如何在 Python 中安装和使用顶级聚类算法2023-05-22 1675
-
10种聚类算法和Python代码12023-02-20 1628
-
10种顶流聚类算法Python实现(附完整代码)2023-01-07 2915
-
10种聚类介绍和Python代码2022-07-30 8112
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 816
-
一种自适应的关联融合聚类算法2021-04-01 1570
-
如何在python中安装和使用顶级聚类算法?2021-03-12 3142
-
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述2018-05-27 31882
-
基于密度DBSCAN的聚类算法2018-04-26 22895
-
一种新的基于流行距离的谱聚类算法2017-12-07 997
-
一种改进的BIRCH算法聚类方法2017-11-10 906
-
基于MCL与Chameleon的混合聚类算法2017-10-31 1465
-
聚类算法及聚类融合算法研究2011-08-10 1075
全部0条评论

快来发表一下你的评论吧 !
