

10种聚类算法和Python代码3
电子说
描述
6、DBSCAN
DBSCAN 聚类(其中 DBSCAN 是基于密度的空间聚类的噪声应用程序)涉及在域中寻找高密度区域,并将其周围的特征空间区域扩展为群集。
…我们提出了新的聚类算法 DBSCAN 依赖于基于密度的概念的集群设计,以发现任意形状的集群。DBSCAN 只需要一个输入参数,并支持用户为其确定适当的值
-源自:《基于密度的噪声大空间数据库聚类发现算法》,1996
它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例。
# dbscan 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,尽管需要更多的调整,但是找到了合理的分组。
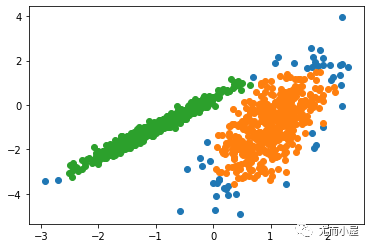
图:使用DBSCAN集群识别出具有集群的数据集的散点图
7、K均值
K-均值聚类可以是最常见的聚类算法,并涉及向群集分配示例,以尽量减少每个群集内的方差。
本文的主要目的是描述一种基于样本将 N 维种群划分为 k 个集合的过程。这个叫做“ K-均值”的过程似乎给出了在类内方差意义上相当有效的分区。
-源自:《关于多元观测的分类和分析的一些方法》1967年
它是通过 K-均值类实现的,要优化的主要配置是“ n _ clusters ”超参数设置为数据中估计的群集数量。下面列出了完整的示例。
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组,尽管每个维度中的不等等方差使得该方法不太适合该数据集。

图:使用K均值聚类识别出具有聚类的数据集的散点图
8、Mini-Batch K-均值
Mini-Batch K-均值是 K-均值的修改版本,它使用小批量的样本而不是整个数据集对群集质心进行更新,这可以使大数据集的更新速度更快,并且可能对统计噪声更健壮。
...我们建议使用 k-均值聚类的迷你批量优化。与经典批处理算法相比,这降低了计算成本的数量级,同时提供了比在线随机梯度下降更好的解决方案。
—源自:《Web-Scale K-均值聚类》2010
它是通过 MiniBatchKMeans 类实现的,要优化的主配置是“ n _ clusters ”超参数,设置为数据中估计的群集数量。下面列出了完整的示例。
# mini-batch k均值聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,会找到与标准 K-均值算法相当的结果。

图:带有最小批次K均值聚类的聚类数据集的散点图
9、均值漂移聚类
均值漂移聚类涉及到根据特征空间中的实例密度来寻找和调整质心。
对离散数据证明了递推平均移位程序收敛到最接近驻点的基础密度函数,从而证明了它在检测密度模式中的应用。
—源自:《Mean Shift :面向特征空间分析的稳健方法》,2002
它是通过 MeanShift 类实现的,主要配置是“带宽”超参数。下面列出了完整的示例。
# 均值漂移聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = MeanShift()
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以在数据中找到一组合理的群集。

图:具有均值漂移聚类的聚类数据集散点图
-
如何在 Python 中安装和使用顶级聚类算法2023-05-22 1707
-
10种聚类算法和Python代码12023-02-20 1650
-
10种顶流聚类算法Python实现(附完整代码)2023-01-07 2925
-
10种聚类介绍和Python代码2022-07-30 8258
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 816
-
一种自适应的关联融合聚类算法2021-04-01 1593
-
如何在python中安装和使用顶级聚类算法?2021-03-12 3158
-
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述2018-05-27 31896
-
基于密度DBSCAN的聚类算法2018-04-26 22907
-
一种基于MapReduce的图结构聚类算法2017-12-19 1065
-
一种新的基于流行距离的谱聚类算法2017-12-07 1003
-
一种改进的BIRCH算法聚类方法2017-11-10 914
-
聚类算法及聚类融合算法研究2011-08-10 1079
全部0条评论

快来发表一下你的评论吧 !
