

10种聚类算法和Python代码4
电子说
描述
10、OPTICS
OPTICS 聚类( OPTICS 短于订购点数以标识聚类结构)是上述 DBSCAN 的修改版本。
我们为聚类分析引入了一种新的算法,它不会显式地生成一个数据集的聚类;而是创建表示其基于密度的聚类结构的数据库的增强排序。此群集排序包含相当于密度聚类的信息,该信息对应于范围广泛的参数设置。
—源自:《OPTICS :排序点以标识聚类结构》,1999
它是通过 OPTICS 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。下面列出了完整的示例。
# optics聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法在此数据集上获得合理的结果。
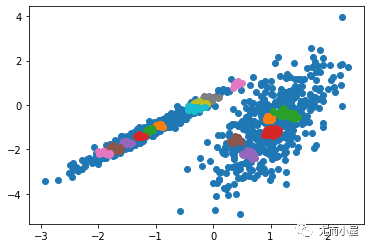
图:使用OPTICS聚类确定具有聚类的数据集的散点图
11、光谱聚类
光谱聚类是一类通用的聚类方法,取自线性线性代数。
最近在许多领域出现的一个有希望的替代方案是使用聚类的光谱方法。这里,使用从点之间的距离导出的矩阵的顶部特征向量。
—源自:《关于光谱聚类:分析和算法》,2002年
它是通过 Spectral 聚类类实现的,而主要的 Spectral 聚类是一个由聚类方法组成的通用类,取自线性线性代数。要优化的是“ n _ clusters ”超参数,用于指定数据中的估计群集数量。下面列出了完整的示例。
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。
在这种情况下,找到了合理的集群。

图:使用光谱聚类聚类识别出具有聚类的数据集的散点图
12、高斯混合模型
高斯混合模型总结了一个多变量概率密度函数,顾名思义就是混合了高斯概率分布。它是通过 Gaussian Mixture 类实现的,要优化的主要配置是“ n _ clusters ”超参数,用于指定数据中估计的群集数量。下面列出了完整的示例。
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我们可以看到群集被完美地识别。这并不奇怪,因为数据集是作为 Gaussian 的混合生成的。

图:使用高斯混合聚类识别出具有聚类的数据集的散点图
三、总结
在本教程中,您发现了如何在 python 中安装和使用顶级聚类算法。具体来说,你学到了:
- 聚类是在特征空间输入数据中发现自然组的无监督问题。
- 有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适合和使用10种顶级聚类算法
-
如何在 Python 中安装和使用顶级聚类算法2023-05-22 1754
-
10种聚类算法和Python代码12023-02-20 1711
-
10种顶流聚类算法Python实现(附完整代码)2023-01-07 2981
-
10种聚类介绍和Python代码2022-07-30 8807
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 830
-
一种自适应的关联融合聚类算法2021-04-01 1649
-
如何在python中安装和使用顶级聚类算法?2021-03-12 3206
-
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述2018-05-27 31935
-
基于密度DBSCAN的聚类算法2018-04-26 22948
-
一种基于MapReduce的图结构聚类算法2017-12-19 1076
-
一种新的基于流行距离的谱聚类算法2017-12-07 1009
-
一种改进的BIRCH算法聚类方法2017-11-10 927
-
聚类算法及聚类融合算法研究2011-08-10 1087
全部0条评论

快来发表一下你的评论吧 !
