

机器学习如何影响计算机硬件设计1
电子说
描述
前 言
为什么芯片设计需要很长时间?能不能加速芯片设计周期?能否在几天或几周之内完成芯片的设计?这是一个非常有野心的目标。过去十年,机器学习的发展离不开系统和硬件的进步,现在机器学习正在促使系统和硬件发生变革。
Google在这个领域已率先出发。在第58届DAC大会上,Google AI负责人Jeff Dean分享了《机器学习在硬件设计中的潜力》,他介绍了神经网络发展的黄金十年,机器学习如何影响计算机硬件设计以及如何通过机器学习解决硬件设计中的难题,并展望了硬件设计的发展方向。
他的演讲重点在于Google如何使用机器学习优化芯片设计流程,这主要包括架构搜索和RTL综合、验证、布局与布线(Placement and routing)三大阶段。在架构搜索阶段,Google提出了FAST架构自动优化硬件加速器的设计,而在验证阶段,他们认为使用深度表示学习可提升验证效率,在布局与布线阶段,则主要采用了强化学习技术进行优化。
以下是他的演讲内容:
1
神经网络的黄金十年
制造出像人一样智能的计算机一直是人工智能研究人员的梦想。而机器学习是人工智能研究的一个子集,它正在取得很多进步。现在大家普遍认为,通过编程让计算机变得“聪明”到能观察世界并理解其含义,比直接将大量知识手动编码到人工智能系统中更容易。
神经网络技术是一种非常重要的机器学习技术。神经网络一词出现于1980年代左右,是计算机科学术语中一个相当古老的概念。虽然它当时并没有真正产生巨大的影响,但有些人坚信这是正确的抽象。
本科时,我写了一篇关于神经网络并行训练的论文,我认为如果可以使用64个处理器而不是一个处理器来训练神经网络,那就太棒了。然而事实证明,我们需要大约100万倍的算力才能让它真正做好工作。
2009年前后,神经网络技术逐渐火热起来,因为我们开始有了足够的算力让它变得有效,以解决现实世界的问题以及我们不知道如何解决的其他问题。2010年代至今是机器学习取得显著进步的十年。
是什么导致了神经网络技术的变革?我们现在正在做的很多工作与1980年代的通用算法差不多,但我们拥有越来越多的新模型、新优化方法等,因此可以更好地工作,并且我们有更多的算力,可以在更多数据上训练这些模型,支撑我们使用更大型的模型来更好地解决问题。
在探讨设计自动化方面之前,我们先来看看一些真实世界的例子。首先是语音识别。在使用深度学习方法之前,语音识别很难得到实际应用。但随后,使用机器学习和神经网络技术,大幅降低了词语的识别错误率。
几年后,我们将错误率降低到5%左右,让语音识别更加实用,而现在,在不联网的设备里,我们都可以做到仅仅4%左右的错误率。这样的模型被部署在人们的手机里面,随时随地帮助人们识别自己的语音。
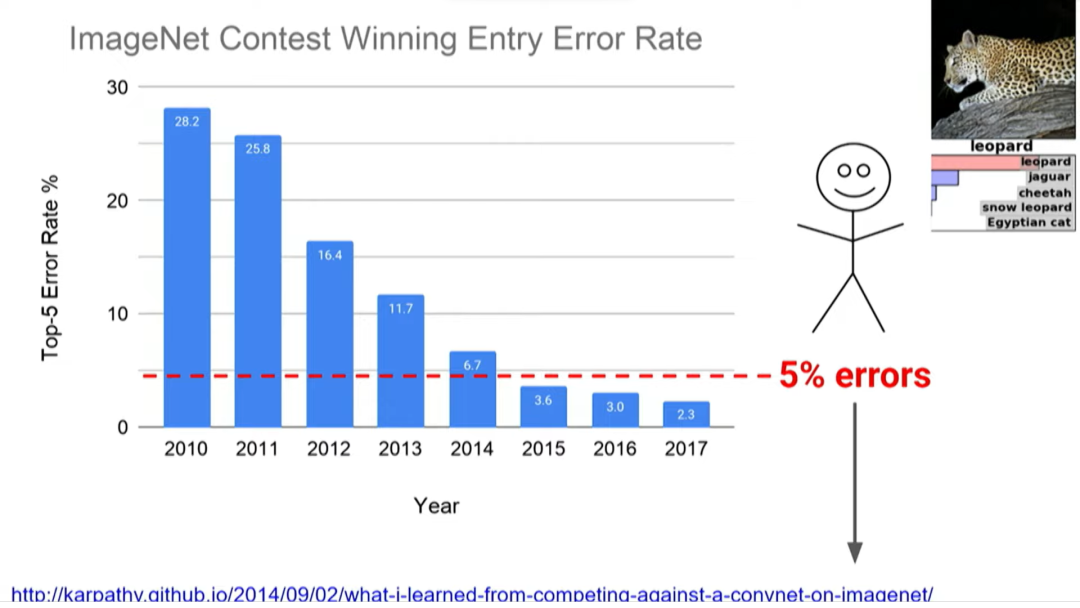
计算机视觉方面也取得了巨大的进步。2012年左右,Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在ImageNet比赛中首次使用了AlexNet,错误率得到显著降低,并在当年夺得桂冠。
后一年的ImageNet比赛中,几乎所有参赛者都使用深度学习方法,研究人员则进一步放弃了传统的方法。其中,2015年,由何恺明等微软研究人员提出ResNet更进一步降低了错误率。
当时的斯坦福大学研究生Andrej Karpathy正在帮助运营ImageNet比赛,他想知道如果人工识别这项艰难的任务,错误率会是多少。在上千个类别中有40种狗,你必须能够看着一张照片说:“哦,那是一只罗威纳犬,不是一只大力金刚犬,或者其他品种的狗。” 经过一百个小时的训练,他将错误率降到了5%。
这是一项非常艰难的任务,将计算机识别错误率从2011年的26%降低到2017年的2%是一件很了不起的事,过去计算机无法识别的东西,现在已经可以识别。自然语言处理、机器翻译和语言理解中也经历了类似的故事。
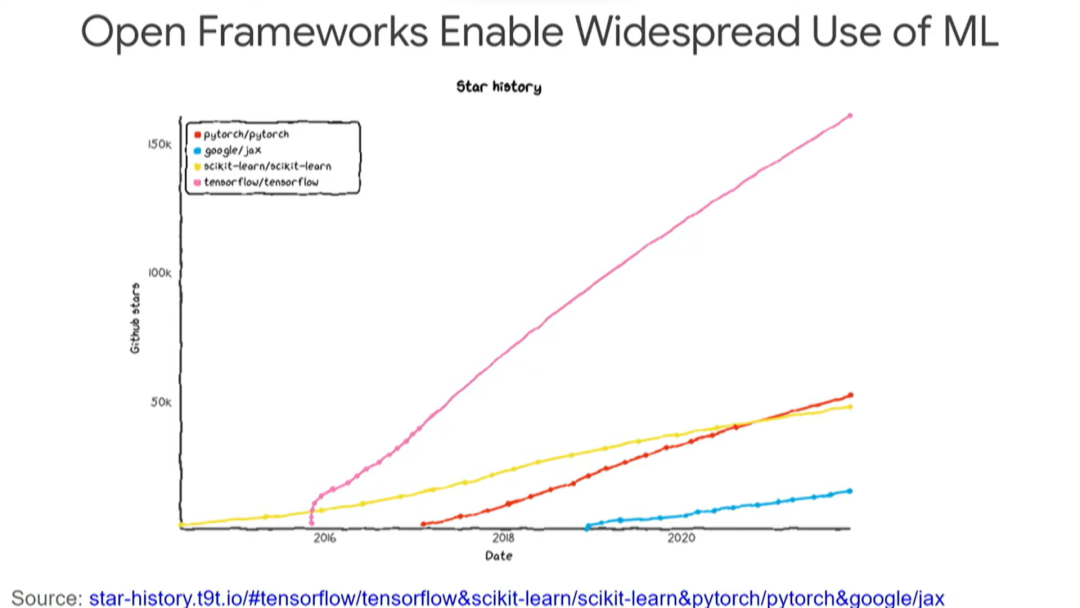
此外,开源框架确实使世界各地的许多人能够应用机器学习技术,TensorFlow就是其中之一。
大约在2015年11月,我们开源了TensorFlow以及供Google内部使用的工具。TensorFlow对世界产生了相当大的影响,它已经被下载了大约5000万次,当然也出现了很多其他框架,比如JAX、PyTorch等等。
世界各地的人们能够将机器学习用于各种了不起的用途,例如医疗保健、机器人技术、自动驾驶等等,这些领域都是通过机器学习方法来理解周围的世界,进而推动领域的发展。
2
机器学习改变计算机设计方式
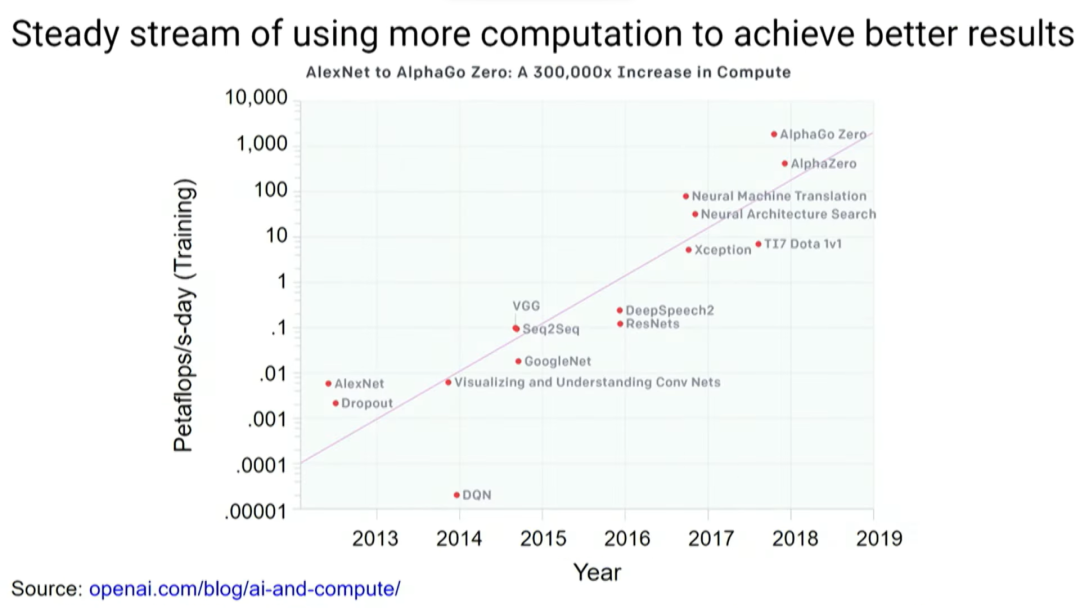
ML研究社区中的许多成功源自使用更多算力和更大的模型,更多的算力促进了机器学习研究领域中重要成果的产生。深度学习的发展正在深刻改变计算机的结构。现在,我们想围绕机器学习计算类型构建专门的计算机。

近年来,我们已经在Google做了很多类似的工作,其中TPU(张量处理单元)是我们构建定制处理器的一种方法,这些处理器专为神经网络和机器学习模型而设计。
TPU v1是我们第一个针对推理的产品,当你拥有经过训练的模型,并且只想获得已投入生产使用的模型的预测结果,那它就很适合,它已经被用于神经机器翻译的搜索查询、AlphaGo比赛等应用中。
后来我们还构建了一系列处理器。TPU v2旨在连接在一起形成称为Pod的强大配置,因此其中的256个加速器芯片通过高速互联紧紧连接在一起。TPU v3则增加了水冷装置。
TPU v4 Pod不仅可以达到ExaFLOP级的算力,它还让我们能够在更大的模型训练中达到SOTA效果,并尝试做更多的事情。
以ResNet-50模型为例,在8块P100 GPU上训练完ResNet-50需要29小时,而在2021年6月的MLPerf竞赛中,TPU v4 pod仅耗时14秒就完成了训练。但我们的目的不仅仅是在14秒内训练完ResNet,而是想把这种强大的算力用于训练其他更先进的模型。
可以看到,从一开始的29小时到后来的14秒,模型的训练速度提高了7500倍。我认为实现快速迭代对于机器学习非常重要,这样才能方便研究者试验不同想法。
基于机器学习的计算方式越来越重要,计算机也正在往更适应机器学习计算方式的方向上演进。但深度学习有可能影响计算机的设计方式吗?我认为,答案是肯定的。
3
机器学习缩短芯片设计周期
目前,芯片的设计周期非常长,需要几十甚至几百人的专业团队花费数年的努力。从构思到完成设计,再到成功生产,中间的时间间隔十分漫长。但如果将来设计芯片只需要几个人花费几周时间呢?这是一个非常理想的愿景,也是研发人员当前的目标。
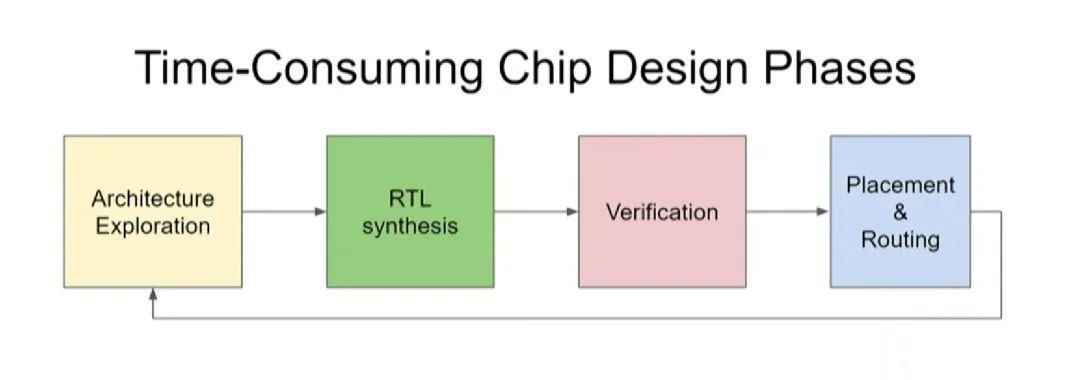
如上图所示,芯片设计包含四个阶段:架构探索→RTL综合→验证→布局和布线。完成设计之后,在制作生产环节需要进行布局和布线(Placement & Routing),有没有更快、更高质量的布局和布线方法?验证是非常耗时的一步,能不能用更少的测试次数涵盖更多的测试项目?有没有自动进行架构探索和RTL综合的方法?目前,我们的芯片架构探索只针对几种重要的应用,但我们终将要把目光扩大。
布局与布线
首先,关于布局和布线,Google在2020年4月发表过一篇论文Chip Placement with Deep Reinforcement Learning,2021年6月又在Nature上发表了A graph placement methodology for fast chip design。
我们知道强化学习的大致原理:机器执行某些决定,然后接收奖励(reward)信号,了解这些决定带来什么结果,再据此调整下一步决定。
因此,强化学习非常适合棋类游戏,比如国际象棋和围棋。棋类游戏有明确的输赢结果,机器下一盘棋,总共有50到100次走棋,机器可以根据最终的输赢结果评定自己和对手的整套走棋方法的有效性,从而不断调整自己的走棋,提高下棋水平。
那么ASIC芯片布局这项任务能不能也由强化学习智能体来完成呢?

这个问题有三个难点。第一,芯片布局比围棋复杂得多,围棋有10^{360}种可能情况,芯片布局却有10^{9000}种。
第二,围棋只有“赢”这一个目标,但芯片布局有多个目标,需要权衡芯片面积、时序、拥塞、设计规则等问题,以找到最佳方案。
第三,使用真实奖励函数(true reward function)来评估效果的成本非常高。当智能体执行了某种芯片布局方案后,就需要判断这个方案好不好。如果使用EDA工具,每次迭代都要花上很多个小时,我们希望将每次迭代所需时间缩减为50微秒或50毫秒。
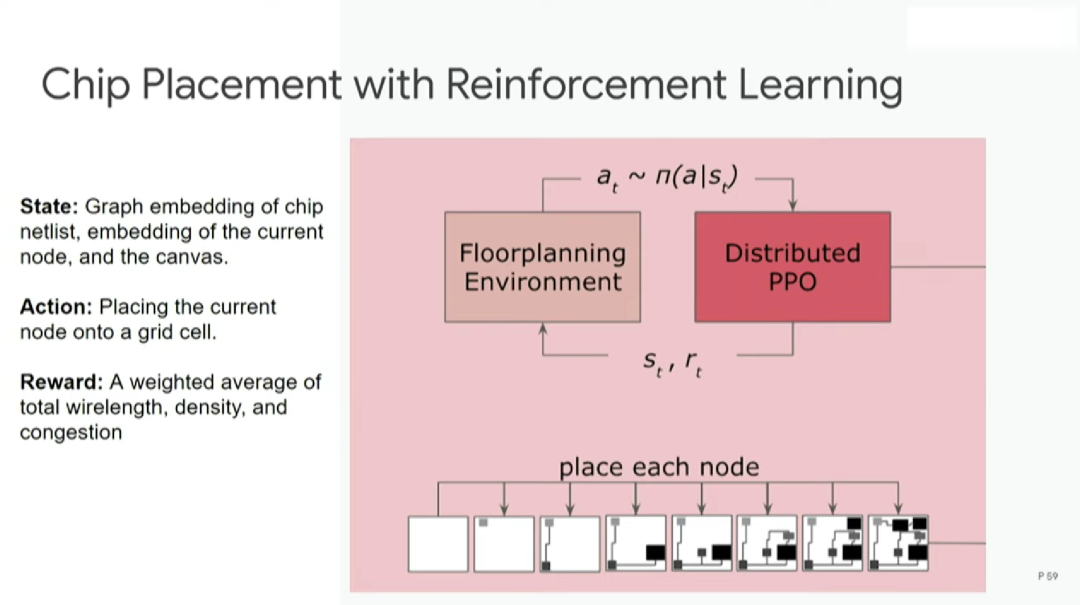
利用强化学习进行芯片布局的步骤如下:首先从空白底座开始,运用分布式PPO算法(强化学习的常用算法)进行设计,然后完成每个节点的布局放置,最后进行评估。
评估步骤使用的是代理奖励函数(proxy reward function),效果和真实奖励函数相近,但成本低得多。在一秒或半秒内就可以完成对本次布局方案的评估,然后指出可优化之处。

构建奖励函数需要结合多个不同的目标函数,例如线长、拥塞和密度,并分别为这些目标函数设定权重。
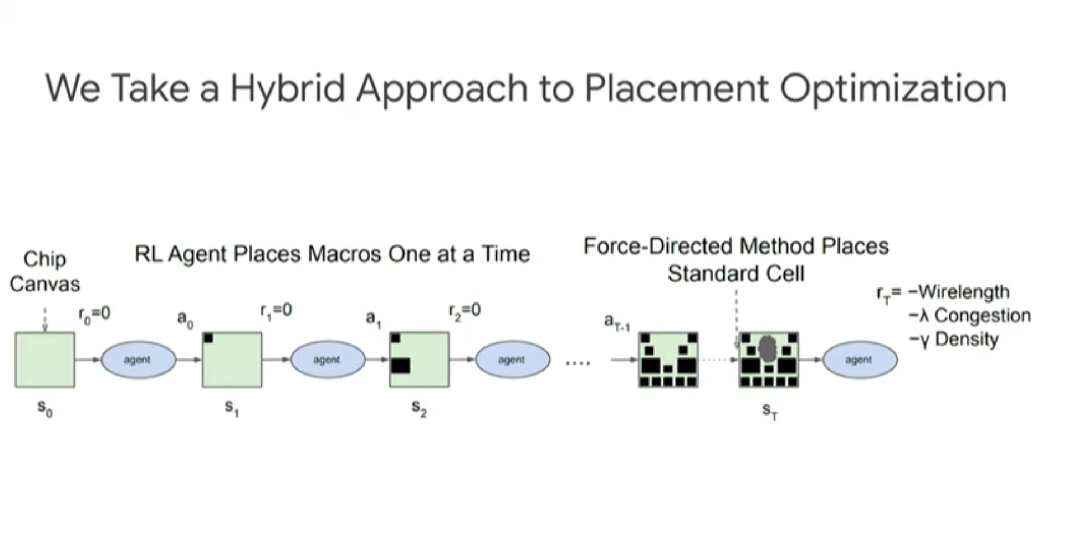
如上图所示,布局优化采取的是混合方式。强化学习智能体每次放置宏(macro),然后通过力导向方法(force-directed method)放置标准单元。
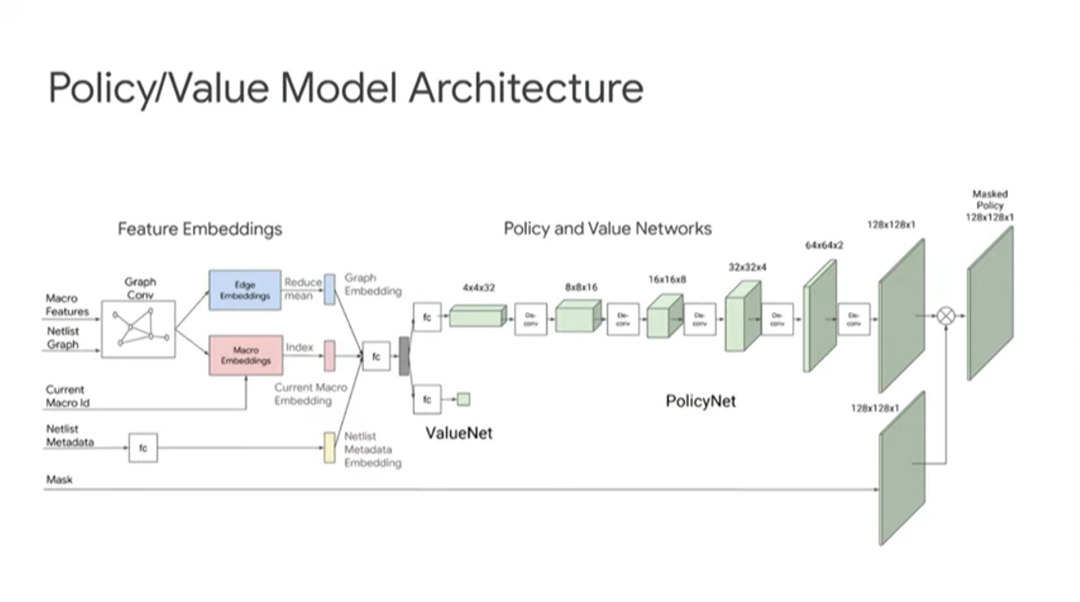
上图来自前面提到的Nature论文,展示了更多芯片架构的细节。

上图展示了一个TPU设计块的布局与布线结果。白色区域是宏,绿色区域是标准单元群(standard cell clusters)。
图中左边是人类专家完成的设计,从中可以看出一些规律。人类专家倾向于把宏沿边缘放置,把标准单元放在中间。一名人类专家需要6~8周完成这个布局,线长为57.07米。图中右边是由智能体(ML placer)完成的布局,耗时24小时,线长55.42米,违反设计规则的地方比人类专家略多,但几乎可以忽略。
-
计算机硬件的基本组成2021-12-23 2201
-
计算机硬件维护的方法2021-09-17 1321
-
计算机硬件,第2篇 计算机硬件系统.pdf 精选资料分享2021-09-13 1467
-
计算机硬件各种故障及诊断方法2021-09-08 1374
-
用简单的语言描述计算机硬件系统构成 精选资料分享2021-07-29 1319
-
什么是计算机系统、计算机硬件和计算机软件?2021-07-22 2464
-
计算机硬件的重要部件2018-11-24 19345
-
咦!?怎么没有专门的计算机硬件设计的板块和cpu设计的板块?2018-02-21 3627
-
计算机硬件接口大全图解2010-03-26 2248
-
计算机硬件知识试题2009-07-01 1262
-
计算机硬件知识大全2009-05-15 1390
-
微型计算机硬件组成2006-03-25 1049
全部0条评论

快来发表一下你的评论吧 !
