

Apache Storm是什么
描述
一、概念
Apache Storm作为流数据的实时处理框架,官网给出了如下模型:
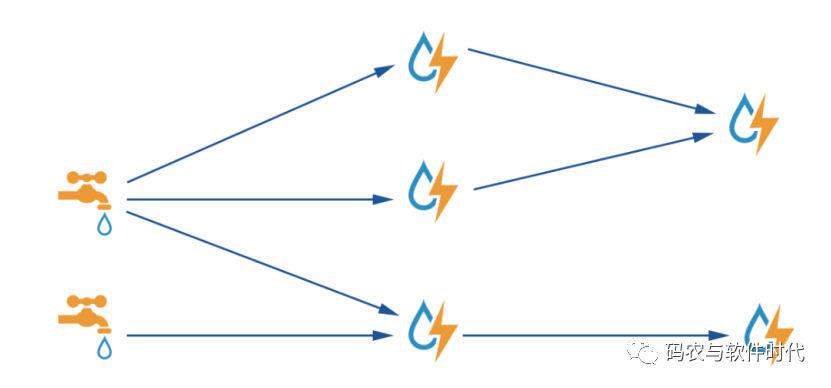
图中“水龙头”便是spout [spaʊt] 出水管,“闪电”便是bolt [bəʊlt],“箭头”表达的是数据的流转,“水龙头”、“闪电”和“箭头”组成的有向无环图称为Topology(拓扑)。
使用Storm框架进行流数据的实时处理,就需要编写“水龙头”和“闪电”的处理逻辑,并将它们通过Topology串接在一起,构建实时处理的业务逻辑。
具体的做法是:
(1)实时数据源,如kafka,接入到“水龙头”Spout中;
(2)Spout读取源数据并不断地发出数据到后续Bolt中,这些数据称为Tuple(元组);
(3)Bolt对发送过来的数据Tuple进行处理,完成数据流转换;
读到这里,可能还是很迷惑,我们以常见的示例统计词频(heart.txt)来进行说明:
Take me to your heart
Take me to your soul
Give me your hand and hold me
Show me what love is
Be my guiding star
It's easy take me to your heart
Standing on a mountain high
Looking at the moon through a clear blue sky
我们可以设计一个topology:
WordSourceSpout:读取heart.txt,并逐行发送数据流Stream,每行即为一个Tuple;
WordSplitBolt:拆分Tuple,并将单词Tuple发出到下个Bolt;
WordCountBolt:对单词的频率进行累加计算;
二、编程
1.Topology是如何构建的?
Topology是通过TopologyBuilder来构建的,提供setSpout和setBolt方法来配置Spout和Bolt,这两个方法都具有3个参数,比较类似,以setSpout为例,第1个参数表示Stream的名称,第2个参数表示stream的处理对象,第3个参数表示并发数,也就是同时运行多少个任务来处理Stream。先来看一段代码:
TopologyBuilder topologyBuilder = new TopologyBuilder();
WordSourceSpout spout = new WordSourceSpout();
WordSplitBolt splitBlot = new WordSplitBolt();
WordCountBolt countBlot = new WordCountBolt();
topologyBuilder.setSpout("sentences", spout, 2);
topologyBuilder.setBolt("split",splitBlot , 8).shuffleGrouping("sentences");
topologyBuilder.setBolt("count",countBlot , 8).fieldGrouping("split",new Fields(“word”));
上面定义了两个Bolt,它们之间数据流的关联关系:第1个Bolt声明其输出Stream的名称为split,而第2个Bolt订阅的Stream为split。countBlot 通过fieldGroupings()在word上具有相同字段的所有Tuple发送到同一个任务中进行统计。
2.Spout和Bolt是如何定义的?
编程模型中,Spout和Bolt都称为组件Component。
WordSourceSpout 需要继承BaseRichSpout,其类结构关系为:
BaseRichSpout--继承--BaseComponent--实现--IComponent
BaseRichSpout--实现--IRichSpout--实现--ISpout
ISpout接口的定义为:
public interface ISpout extends Serializable {
/**
* Called when a task for this component is initialized within a worker on the cluster. It provides the spout with the environment in
* which the spout executes.
*
* This includes the:
*
* @param conf The Storm configuration for this spout. This is the configuration provided to the topology merged in with cluster
* configuration on this machine.
* @param context This object can be used to get information about this task's place within the topology, including the task id and
* component id of this task, input and output information, etc.
* @param collector The collector is used to emit tuples from this spout. Tuples can be emitted at any time, including the open and
* close methods. The collector is thread-safe and should be saved as an instance variable of this spout object.
*/
void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector);
/**
* Called when an ISpout is going to be shutdown. There is no guarentee that close will be called, because the supervisor kill -9's
* worker processes on the cluster.
*
* The one context where close is guaranteed to be called is a topology is killed when running Storm in local mode.
*/
void close();
/**
* Called when a spout has been activated out of a deactivated mode. nextTuple will be called on this spout soon. A spout can become
* activated after having been deactivated when the topology is manipulated using the `storm` client.
*/
void activate();
/**
* Called when a spout has been deactivated. nextTuple will not be called while a spout is deactivated. The spout may or may not be
* reactivated in the future.
*/
void deactivate();
/**
* When this method is called, Storm is requesting that the Spout emit tuples to the output collector. This method should be
* non-blocking, so if the Spout has no tuples to emit, this method should return. nextTuple, ack, and fail are all called in a tight
* loop in a single thread in the spout task. When there are no tuples to emit, it is courteous to have nextTuple sleep for a short
* amount of time (like a single millisecond) so as not to waste too much CPU.
*/
void nextTuple();
/**
* Storm has determined that the tuple emitted by this spout with the msgId identifier has been fully processed. Typically, an
* implementation of this method will take that message off the queue and prevent it from being replayed.
*/
void ack(Object msgId);
/**
* The tuple emitted by this spout with the msgId identifier has failed to be fully processed. Typically, an implementation of this
* method will put that message back on the queue to be replayed at a later time.
*/
void fail(Object msgId);
}
WordCountBolt需要继承BaseBasicBolt,其类结构关系为:
BaseBasicBolt--继承--BaseComponent--实现--IBasicBolt--IComponent
IBasicBolt接口的定义为:
public interface IBasicBolt extends IComponent {
void prepare(Map topoConf, TopologyContext context) ;
/**
* Process the input tuple and optionally emit new tuples based on the input tuple.
*
* All acking is managed for you. Throw a FailedException if you want to fail the tuple.
*/
void execute(Tuple input, BasicOutputCollector collector);
void cleanup();
}
IComponent接口的定义:
/**
* Common methods for all possible components in a topology. This interface is used when defining topologies using the Java API.
*/
public interface IComponent extends Serializable {
/**
* Declare the output schema for all the streams of this topology.
*
* @param declarer this is used to declare output stream ids, output fields, and whether or not each output stream is a direct stream
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* Declare configuration specific to this component. Only a subset of the "topology.*" configs can be overridden. The component
* configuration can be further overridden when constructing the topology using {@link TopologyBuilder}
*/
Map<String, Object> getComponentConfiguration();
}
Storm框架基本逻辑为:
Spout组件通过Open方法进行SpoutOutputCollector(Spout输出收集器)的初始化,Storm调用Spout组件的nextTuple方法请求tuple时,便通过SpoutOutputCollector的emit方法发送一个tuple。Bolt组件通过execute方法接收到tuple,并对tuple进行数据处理。
-
什么是Apache日志?Apache日志分析工具介绍2024-01-04 2010
-
Apache Storm的安装部署2023-02-20 2081
-
Apache Doris正式成为 Apache 顶级项目2022-06-17 2218
-
Storm-Engine基于C++的开源游戏引擎2022-06-16 1223
-
Apache与Weblogic的整合2021-08-31 899
-
一种基于Apache Storm的增量式FFT方法2021-04-28 973
-
探讨Apache kafka在部署可伸缩物联网解决方案中所扮演的角色2020-07-21 957
-
Storm高阶之Trident的全面介绍2019-07-29 2299
-
Storm使用场景2019-06-11 915
-
如何利用Storm完成实时分析处理数据2018-04-26 8747
-
Storm环境下基于权重的任务调度算法2018-04-17 1144
-
怎样在Docker Swarm上部署Apache Storm2017-10-10 793
全部0条评论

快来发表一下你的评论吧 !
