

ChatGPT大型语言模型搜索架构和成本
人工智能
描述
ChatGPT火热的背后。
ChatGPT目前每天花费约 700,000 美元来运行硬件推理成本。如果ChatGPT的当前实施和运营被投入到每一个谷歌搜索中,这将意味着成本结构的巨大增加,达到360亿美元。谷歌服务业务部门的年净收入将从 2022 年的 555 亿美元下降至 195 亿美元。
当然,这永远不会发生,但是如果我们假设没有进行任何软件或硬件改进,那就是有趣的思想实验。
第一轮优化很简单。Bing GPT 的 84 个不同真实示例的令牌输出计数明显较低,约为 350,而 ChatGPT 则为 2,000。在大多数情况下,人们希望在与搜索交互时避免阅读大量信息。此估算考虑了未向用户显示的令牌。后续的优化是前2000个关键词占搜索量的12.2%,更多的也是纯导航搜索。假设 20% 的搜索不需要 LLM。最后,与使用基于英伟达的 HGX A100 的 Microsoft/OpenAI 相比,谷歌使用内部 TPUv4 pod 具有显著的基础设施优势。
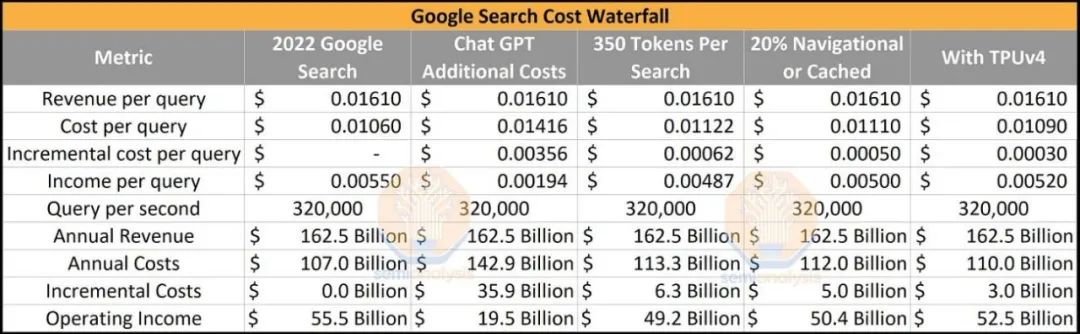
这些简单的优化使 Google 在搜索中实施 LLM 的额外成本仅为 30 亿美元。如果一切从一开始就完美设置,Google 仅在硬件上的资本支出成本就约为200亿美元,包括数据中心基础设施。这是在Nvidia H100 和 Google 的 TPUv5 等新硬件或MoE、稀疏性、修剪、模型蒸馏、kv 缓存和提前退出等各种技术提高成本之前。
人们不会接受连接到互联网的 ChatGPT 的接口,速度太慢,容易编造信息,无法有效变现。上面的分析仍然过于简单,仅在搜索堆栈的一部分(实时查询处理)中说明了LLM 。
今天,我们将深入探讨 LLM 在整个搜索堆栈中的未来实现。由于用户体验的变化,单位收入经济和成本结构将完全重新设计,这将在未来 2 到 3 年内迅速改变。
要从收入和成本的角度更深入地了解变化,我们首先必须解释当前的搜索架构,因为它为未来的变化提供了背景。从较高的层面来看,搜索的目标是尽快提供相关信息。输入关键字时,你希望将最佳信息提升到顶部。搜索管道有四个主要进程:爬虫、索引、查询处理器和广告引擎。机器学习模型已经在这四个领域得到广泛应用。
履带式
爬虫自动定位互联网上的新内容,包括网页、图像和视频,并将其添加到搜索引擎的数据库(索引)中。通过利用机器学习,爬虫确定要索引的页面的价值并识别重复内容。它还分析页面之间的链接,评估哪些页面可能相关且重要。此信息用于优化抓取过程,确定抓取哪些页面、频率和程度。
爬虫在内容提取中也起着重要作用。目标是全面文本化网页包含的内容,同时最小化该数据的总大小以支持快速准确的搜索。延迟就是搜索的重中之重的问题,即使是几百毫秒也会显著影响用户的搜索量。
谷歌和必应利用图像和小型语言模型来生成页面/图像/视频本身不存在的元数据。大型语言和多模式模型的明显插入点是大规模扩展这些功能。在任何简单的搜索成本模型中都没有考虑到这一点。
索引
索引是一个数据库,用于存储爬虫发现的信息。在索引层中进行了大量预处理,以最大限度地减少必须搜索的数据量。这最大限度地减少了延迟并最大限度地提高了搜索相关性。
相关性排名:模型可用于根据相关性对索引中的页面进行排名,以便首先返回最相关的页面以响应用户的搜索查询。
聚类:模型可用于将索引中相似的页面分组为聚类,使用户更容易找到相关信息。
异常检测:模型可以检测并从索引中删除异常或垃圾页面,从而提高搜索结果的质量。
文本分类:模型可用于根据内容和上下文对索引中的页面进行分类。
主题建模:模型可以识别索引页面涵盖的主题,并将每一页映射到一个或多个主题。
虽然目前这是通过较小的模型和 DLRM 完成的,但如果插入 LLM,效率将显著提高。在任何简单的搜索成本模型中都没有考虑到这一点。我们将在本报告稍后部分讨论用例并估算成本。
查询处理器
这是搜索堆栈中最受关注的层。它接收用户的查询并生成最相关的结果。它通过解析用户的查询,将其分解为关键字和短语,从索引中获取最相关的项目,然后针对该用户的特定查询重新排序和过滤来实现这一点。查询处理器还负责将这些结果呈现给用户。
目前有多种模型部署在这个管道中,从简单的拼写检查到查询扩展,自动将相关术语添加到用户的查询中以提高搜索结果的准确性。基于用户的搜索历史、位置、设备、偏好和兴趣的相关性排名和个性化结果。这目前需要在多个小模型上运行推理。
当用户实时提交查询时,必须快速有效地执行查询处理。相比之下,抓取和索引是持续发生的过程,不与用户交互。
顺便说一句,谷歌和必应在这里使用非常不同的硬件来实现他们的经典方法。谷歌使用了大量标准 CPU 和内部 TPU。另一方面,必应目前使用许多标准 CPU 和FPGA 。
广告引擎
虽然搜索堆栈的最后三个部分对于满足和留住用户至关重要,但许多人认为广告引擎最重要,因为所有盈利都源于其质量。查询处理器与广告引擎实时交互。广告引擎必须对用户查询、用户配置文件、位置和广告效果之间的关系进行建模,以便为每个用户生成个性化推荐,从而最大限度地提高点击率和收入。
广告市场是一个实时竞价的比赛,广告商通常为关键字、词组或某些用户类型付费。广告模型松散地使用这些作为指导,因为支付的金额不是服务的唯一指标。该模型需要优化转换以赚取收入并提高利率,因此相关性是超优化参数。
平均而言,在过去四年中,80% 的 Google 搜索都没有在搜索结果顶部显示任何广告。此外,目前只有一小部分搜索(不到 5%)有四个最热门的文字广告。
使用 LLM,消费者阅读的部分不是广告可以转化为广告商销售的前几个结果。相反,它是 LLM 的输出。因此,这是随着对话式 LLM 的出现而发生最大变化的搜索堆栈的一部分。我们将在本报告后面部分讨论货币化的方式和情况,因为这是广告服务运作方式的根本转变。
激进的转变
搜索中的LLM不仅仅是加入搜索引擎界面的一个大模型。相反,它是许多模型交织在一起的。每个模型的工作是为链中的下一个模型提供最密集和最相关的信息。这些模型必须不断地在活跃用户身上重新训练、调整和测试。谷歌历来率先在搜索堆栈的所有四个层中使用人工智能,但现在,搜索正在用户体验、使用模型和货币化结构方面发生根本性转变,这可能会使软件堆栈的许多现有部分失效。
最大的问题是谷歌是否准备好完成这项任务。他们能否调整整个搜索堆栈?
在弄清楚使用模型之前,谷歌是否有要求来超级优化其搜索堆栈?假设谷歌将太多资源投入到以最低成本运营并达到搜索相关性的局部最大值。在那种情况下,谷歌可能会限制其本应致力于扩展和测试新使用模型的模型开发和创新。如果是微软和 OpenAI 团队的话,更有可能将谨慎抛在一边,并对搜索堆栈的所有四个元素进行彻底重组。
我们最初将与 LaMDA 的轻量级模型版本一起发布。这个小得多的模型需要更少的计算能力,使我们能够扩展到更多的用户,从而获得更多的反馈。
他们正在削减一个模型,其架构最初是在 2021 年初开发的。当然,此后它有所改进,但 OpenAI 和微软正在使用一个更大的模型和更新的架构,这些模型是在 2022 年底和 2023 年初开发的,并得到了 ChatGPT 的持续反馈。这是有正当理由的,但也正是这个原因可能会让谷歌在用户体验和迭代速度方面受到重创。
更令人担忧的是,在过去的几个月里,一些有远见的人才最近开始涌向初创公司,包括但不限于 OpenAI。这包括 BERT 的教父、PaLM 推理的首席工程师和 Jax 的首席工程师。这可能是文化弱化的迹象。
想象一下,如果这场搜索竞争导致谷歌的股票继续下跌,而 RSU 的价值远低于预期。这对员工的士气和保留有什么影响?
或者,由于必应争夺市场份额并竞标 Google 目前拥有的 Apple 独家交易,搜索不再是无穷无尽的摇钱树怎么样?谷歌是否必须对亏损的业务(包括谷歌云)勒紧裤腰带?
延迟
Google 的 Bard 是一个较小的模型,具有较低的延迟响应时间。谷歌内部有一个非常优越的 PaLM 模型,但无力部署它。
即使延迟为 2,000 毫秒,是常规搜索的 4 倍,PaLM 也只能采用 60 个输入令牌(约 240 个字符)并输出 20 个令牌(80 个字符),这就是在 64 个 TPUv4 上并行时,始终只能实现大约35% 的利用率。
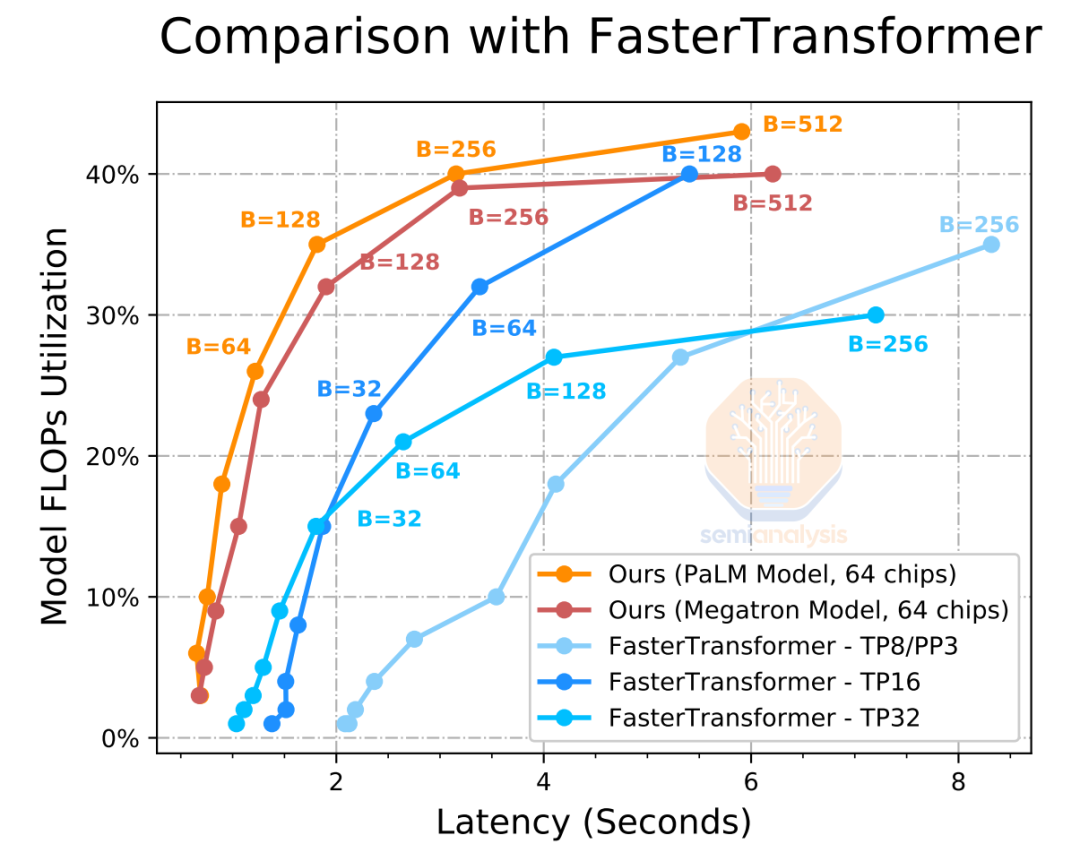
重要的是,大型 LLM 需要在搜索堆栈的非时间敏感部分使用。此外,更大的批量大小可以在堆栈的这些部分实现更高的利用率,尽管延迟更高。
语境为王
面向用户的模型和未来 AI 芯片的关键是增加它们的上下文窗口,以便可以通过层向前馈送更多先前的模型或源材料。就推理成本而言,缩放序列长度的成本也非常高,这将使你的成本结构膨胀。
因此,在实时方面将围绕此进行许多优化。在爬行和索引阶段,你可以最大化上下文窗口,以尽可能多地将源材料密集化到尽可能高的质量标准。
这样就可以在堆栈的实时查询部分启用更小的模型,以最大限度地减少搜索和上下文窗口的数量,从而减少延迟并缩短响应时间。
整个搜索堆栈中的 LLM 实现
看看微软如何以相同的方式应用这些技术作为某些高级企业搜索和对话式 AI 助手的一部分,扫描过去 30 年中的每个文档、电子邮件、Excel 工作表、PDF 和即时消息,这也将很有趣。当然,谷歌仍然拥有其 Android、YouTube、地图、购物、航班和照片等模块,在这些领域微软几乎无法与之竞争,因此无论发生什么情况,这些模块都可以让谷歌在搜索领域保持领先地位。
现在,我们将描述我们如何在运营和基础设施层面设想新的搜索堆栈。我们将通过堆栈逐个类别地描述五种不同类型的 LLM 的用途及其跨搜索堆栈、爬虫、索引、查询处理器和广告引擎的四个不同层的推理成本结构。这些成本结构将仿照 OpenAI 和微软将使用的 Nvidia HGX A100 / H100,以及谷歌内部的 TPUv4 / TPUv5。从使用模型的角度来看,广告引擎的变化可能是最有意义的。
编辑:黄飞
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
看海泰方圆类ChatGPT技术模型!2023-02-10 1507
-
ChatGPT使用初探2023-02-13 2217
-
大型语言模型有哪些用途?2023-02-23 6359
-
ChatGPT/GPT的原理 ChatGPT的技术架构2023-02-24 2623
-
大型语言模型有哪些用途?大型语言模型如何运作呢?2023-03-08 9706
-
ChatGPT引发搜索行业变革?从MWC 2023看华为在搜索能力的创新之道2023-03-06 1666
-
浅析AI大型语言模型研究的发展历程2023-06-09 6598
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2756
-
大型语言模型的应用2023-07-05 3088
-
chatgpt是什么意思 chatgpt有什么用2023-07-19 1445
-
ChatGPT等大型语言模型的出现会带来哪些风险2023-08-04 839
-
ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介2023-12-06 2592
-
llm模型和chatGPT的区别2024-07-09 2855
-
如何利用大型语言模型驱动的搜索为公司创造价值2024-10-13 809
全部0条评论

快来发表一下你的评论吧 !
