

【试用报告】龙芯先锋板:CPU性能测试—CoreMark和计算质数
描述
一、CoreMark简介
什么是CoreMark?
来自CoreMark首页的解释是:
CoreMark is a simple, yet sophisticated benchmark that is designed specifically to test the functionality of a processor core. Running CoreMark produces a single-number score allowing users to make quick comparisons between processors.
翻译一下就是:
CoreMark是一个简单而又精密的基准测试程序,是专门为测试处理器核功能而设计的。运行CoreMark会产生一个“单个数字”的分数,(从而)允许用户在(不同)CPU之间进行快速比较。
简单来说,就是一个测试CPU性能的程序,类似PC上的Cinebench、CPU-Z之类的CPU性能测试工具。
了解了CoreMark是什么之后,接下来我们尝试在龙芯2K0500先锋板上跑一下CoreMark,看看分数是多少。
二、在龙芯2K0500上运行CoreMark
2.1 下载CoreMark源码
在Linux编译主机上,执行如下命令,将CoreMark源码下载到本地:
git clone https://github.com/eembc/coremark.git
(左右移动查看全部内容)
下载完成后,可以看到有这些文件和目录:

2.2 交叉编译CoreMark
接着编译CoreMark,这里假设你已经正确设置了龙芯交叉编译工具链,也就是可以直接运行loongarch64-linux-gnu-gcc命令。
在Linux编译主机上,执行如下命令:
cd coremark
make CC=loongarch64-linux-gnu-gcc link
(左右移动查看全部内容)
其中:
-
CC用于指定编译器,这里指定的是龙芯GNU交叉编译器(loongarch64-linux-gnu-gcc);
-
link是make命令的构建目标,具体定义在Makefile文件中,link是只链接不运行;
编译完成后,可以看到生成了coremark.exe:

2.3 运行CoreMark
通过FTP或U盘,将coremark.exe拷贝到龙芯2K0500先锋板上,使用如下命令运行coremark.exe:
# 添加可执行权限
chmod +x coremark.exe
# 运行
./coremark.exe
运行结束后,输出如下:
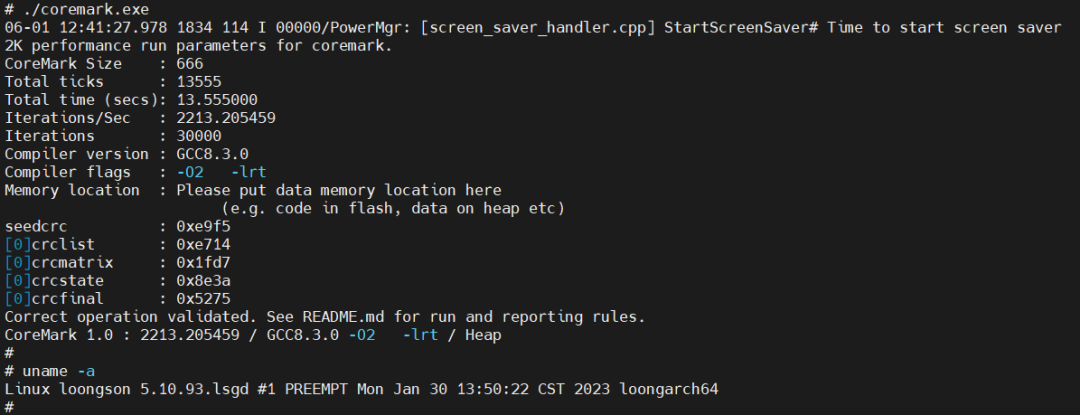
可以看到,龙芯2K0500上CoreMark跑分为2213.205459分。
三、和树莓派3B+上CoreMark结果对比
我这里测试使用的树莓派3B+开发板,系统版本信息是:
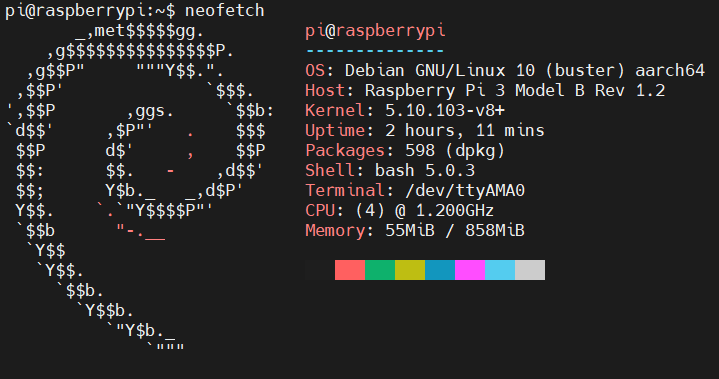
由于树莓派3B+上运行的是Debian系统,有完整的编译工具链。因此,在树莓派3B+上,我们可以直接在开发板上编译源码。
在树莓派3B+上运行CoreMark之前,也需要下载CoreMark源码,和前面类似:
git clone https://github.com/eembc/coremark.git
(左右移动查看全部内容)
不过这次我们直接将CoreMark源码下载到了树莓派上。
3.1 编译CoreMark
树莓派上编译CoreMark之前,需要先安装编译构建工具链,如果还没有的话,可以使用如下命令:
sudo apt install build-essential
(左右移动查看全部内容)
PS:如果已经有gcc、make命令,则可以跳过此步骤。
使用如下命令,编译CoreMark源码:
cd coremark
make link
3.2 运行CoreMark
使用如下命令运行coremark.exe:
./coremark.exe
(左右移动查看全部内容)
PS:这里由于我们是直接在树莓派3B+开发板上编译的CoreMark,所以直接运行即可。
运行结束后,输出如下:
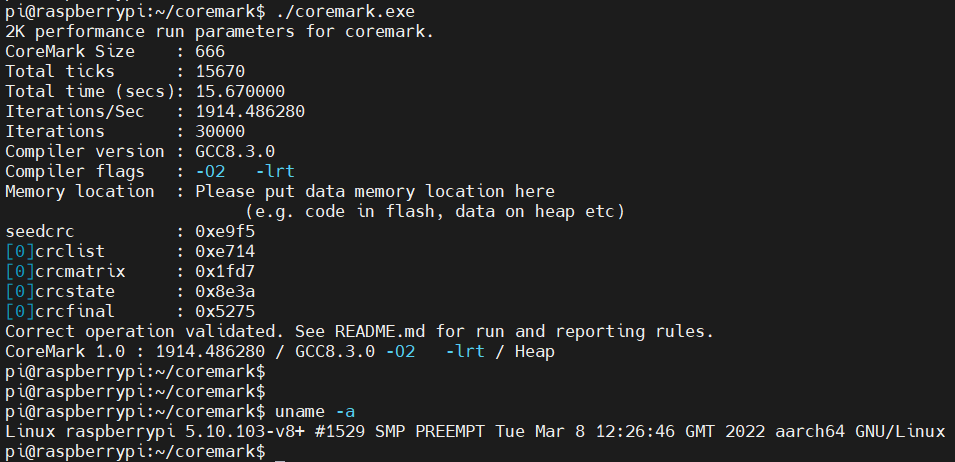
可以看到,树莓派3B+上CoreMark跑分为1914.486280。
龙芯2K0500和树莓派3B+的CoreMark跑分对比:
| 龙芯2K0500 | 树莓派3B+ | |
|---|---|---|
| 跑分 | 2213.205459 | 1914.486280 |
可以看到,龙芯2K0500上的CoreMark跑分高于树莓派3B+。
3.3 其他编译选项跑分对比
查看CoreMark的Makefile和相关源码,我们可以知道,通过编译时添加XCFLAGS参数,可以指定CoreMark的编译参数。
下面是几组不同XCFLAGS参数下,龙芯2K0500和树莓派3B+的CoreMark跑分:
| XCFLAGS | 龙芯2K0500 | 树莓派3B+ |
|---|---|---|
| 2213.205459 | 1914.486280 | |
| "-DPERFORMANCE_RUN=1" | 2213.532059 | 1916.198263 |
| "-DPERFORMANCE_RUN=1 MEM_METHOD=MEM_STACK" | 2218.278616 | 1915.219612 |
| "-DPERFORMANCE_RUN=1 MEM_METHOD=MEM_STATIC" | 2216.475803 | 1916.687963 |
可以看到,几种不同XCFLAGS参数条件下,龙芯2K0500上的CoreMark跑分都要高于树莓派3B+。
添加XFLAGS参数后,树莓派上的编译命令为(以表格最后一行参数为例):
make XCFLAGS="-DPERFORMANCE_RUN=1 -DMEM_METHOD=MEM_STATIC" link
(左右移动查看全部内容)
响应的,Linux编译服务器上,交叉编译命令为:
make CC=loongarch64-linux-gnu-gcc XCFLAGS="-DPERFORMANCE_RUN=1 -DMEM_METHOD=MEM_STATIC" link
(左右移动查看全部内容)
3.4 CoreMark的主要算法
CoreMark项目README的Key Algorithms描述了CoreMark主要用到了那些算法:
-
链表(主要是指针操作)
-
矩阵乘法(主要是乘法和加法运算)
-
状态机(主要是switch-case操作)
说明在这几种计算场景下,龙芯2K0500的速度都是比树莓派3B+要快的。
四、额外的CPU测试
接下来我们看看另外一种场景下的测试结果。
我们知道,生成一个较大的大质数,或者判断一个大整数是否为质数是比较复杂的。
所以,这里我们准备用生成质数在两个开发板上再次进行测试。
4.1 第n个质数
我们使用如下C程序代码,计算第n个质数:
// 判断n是否为质数
bool isprime(uint64_t n)
{
assert(n > 0);
if (n == 2) return true;
if ((n % 2) == 0) return false;
for (uint64_t i = 3, up = n / 2; i < up; i += 2) {
if (n % i == 0) {
return false;
}
}
return true;
}
// 计算第n个质数,例如:1 => 2, 2 => 3, 3 => 5
uint64_t prime(int n)
{
assert(n > 0);
if (n == 1) return 2;
int count = 1;
for (uint64_t i = 3; i < UINT64_MAX; i += 2) {
if (isprime(i)) {
if (++count == n) {
return i;
}
}
}
return 0;
}
int main(int argc, char* argv[])
{
int n = argc > 1 ? atoi(argv[1]) : 10;
clock_t start = clock();
uint64_t prim = prime(n);
clock_t end = clock();
float costs = (end - start) / (float) CLOCKS_PER_SEC;
printf("%10d %.6f %" PRIu64 "
", n, costs, prim);
return 0;
}
(左右移动查看全部内容)
这里为了忽略两块开发板内存差异的影响,我们不保存前面得到的质数(虽然保存前面得到的质数,可以加速后续的isprime判断)。
这里假设保存的文件名为p1.c,树莓派3B+上使用如下命令编译:
gcc -O2 -o p1 p1.c
Linux编译主机上,使用如下命令交叉编译:
loongarch64-linux-gnu-gcc -O2 -o p1 p1.c
(左右移动查看全部内容)
接下来,分别在龙芯2K0500和树莓派3B+上运行,得到如下耗时数据(编译选项:-O2):
| n | 龙芯2K0500耗时 | 树莓派3B+耗时 |
|---|---|---|
| 1000 | 0.018571 | 0.014308 |
| 2000 | 0.080962 | 0.061902 |
| 3000 | 0.191983 | 0.146851 |
| 4000 | 0.353578 | 0.271425 |
| 5000 | 0.567774 | 0.435833 |
| 6000 | 0.831575 | 0.640650 |
| 7000 | 1.153037 | 0.890962 |
| 8000 | 1.533347 | 1.172405 |
| 9000 | 1.965950 | 1.517557 |
这里得到的结论是——树莓派3B+计算质数更快。此前的TFLM测试结果和这里比较类似,同样显示,龙芯2K0500成绩要稍差一些。
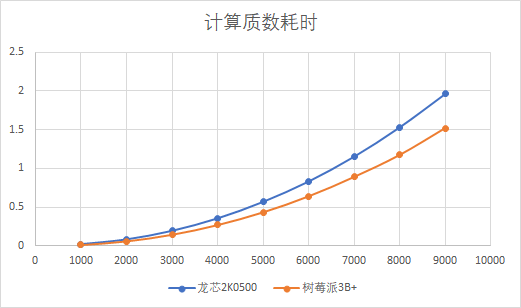
这里龙芯2K500比树莓派3B+慢的主要原因,很可能是因为求质数算法过程中包含了大量除法运算,而龙芯2K0500的除法运算速度要比树莓派3B+慢。
4.2 isprime修改
验证方法也很简单,我们可以直接修改前面的isprime函数:
// 判断n是否为质数
bool isprime(uint64_t n)
{
assert(n > 0);
if (n == 2) return true;
if ((n & 1) == 0) return false; // n % 2 => n & 0x1
for (uint64_t i = 3, up = (n >> 1); i < up; i += 2) { // n / 2 => n >> 1
for (uint64_t j = 3; j < up; j += 2) { // 暴力枚举另外一个因数,不用除法
if (i * j == n) {
return false;
}
}
}
return true;
}
(左右移动查看全部内容)
这里假设保存的文件名为p2.c,树莓派3B+上使用如下命令编译:
gcc -O2 -o p2 p2.c
Linux编译主机上,使用如下命令交叉编译:
loongarch64-linux-gnu-gcc -O2 -o p1 p1.c
(左右移动查看全部内容)
接下来,分别在龙芯2K0500和树莓派3B+上运行,得到如下耗时数据(编译选项:-O2):
| n | 龙芯2K0500耗时 | 树莓派3B+耗时 |
|---|---|---|
| 400 | 0.293424 | 0.302985 |
| 500 | 0.616077 | 0.634836 |
| 600 | 1.123482 | 1.162557 |
这里可以看到,龙芯2K500比树莓派3B+计算要快。
所以,这里验证了前面的猜想——龙芯2K500比树莓派3B+的整数除法要慢。
五、参考链接
-
CoreMark项目:https://github.com/eembc/coremark
-
龙芯GNU编译工具链下载页面:http://www.loongnix.cn/zh/toolchain/GNU/
-
加入龙芯小组:https://bbs.elecfans.com/group_1650
本文由电子发烧友社区发布,转载请注明以上来源。如需社区合作及入群交流,请添加微信EEFans0806,或者发邮箱liuyong@huaqiu.com。

热门推荐干货好文
1、社区精选!PCB多层板设计挑战赛作品集合
2、超强性能AI芯片,OpenHarmony多系统支持,可定制高性能AP(附10+开发Demo)
3、从零入门物联网OH开源平台,从简单到高阶项目,创客、电子爱好者都爱用!
4、低成本ESP32方案,支持OpenHarmony系统开发(附10+项目样例Demo)
5、从0到1玩转瑞萨RA4系列开发板,教你变着花样玩板子
6、四核64位,超强CPU ,看RK3568“竞”开发板DEMO!
7、人工智能也能这么玩, 简单快速入手,还能自定义AI运算
8、全部开源 | 基于全志V85X的运动相机,工业网关,可穿戴式摄像头
9、高性能双核RISC-V,满足大多数开发,这款国产MCU工程师都
原文标题:【试用报告】龙芯先锋板:CPU性能测试—CoreMark和计算质数
文章出处:【微信公众号:电子发烧友论坛】欢迎添加关注!文章转载请注明出处。
-
【上海晶珩睿莓1开发板试用体验】4、Coremark性能测试2025-08-18 543
-
【作品合集】龙芯2K0300蜂鸟开发板试用精选2024-09-10 129478
-
龙芯2K0300蜂鸟板试用报告2024-09-03 1207
-
【龙芯2K0300蜂鸟板试用】+5.CoreMark跑分2024-08-18 1451
-
【龙芯2K0300蜂鸟板试用】龙芯2K0300蜂鸟板试用报告2024-08-09 1961
-
智能嵌入式系统设计大赛--龙芯2K500先锋板2024-05-14 953
-
RISC-V公测平台发布· CoreMark测试报告2023-08-18 4064
-
基于Cortex-M的CoreMark性能测试2023-05-01 10682
-
广东龙芯LS2K500先锋板使用介绍2023-04-22 1252
-
【广东龙芯2K500先锋板试用体验】CPU性能基准测试——CoreMark和计算质数2023-02-03 49789
-
【广东龙芯2K500先锋板试用体验】试用2-处理器性能测试2023-01-06 2246
-
【精品聚合】RA-Eco-RA4M2-100PIN开发板试用报告作品汇总2022-12-02 23307
-
触觉智能Purple Pi开发板试用报告作品汇总2022-10-31 15295
-
试用视频丨国产开发板各项性能测试--米尔MYD-YT507H开发板2022-09-02 1998
全部0条评论

快来发表一下你的评论吧 !
