

一文读懂何为深度学习1
人工智能
描述
自然语言处理领域的殿堂标志 BERT 并非横空出世,背后有它的发展原理。今天,蚂蚁金服财富对话算法团队整理对比了深度学习模型在自然语言处理领域的发展历程。从简易的神经元到当前最复杂的BERT模型,深入浅出地介绍了深度学习在 NLP 领域进展,并结合工业界给出了未来的 NLP 的应用方向,相信读完这篇文章,你对深度学习的整体脉络会有更加深刻认识。
一个神经网络结构通常包含输入层、隐藏层、输出层。输入层是我们的 features (特征),输出层是我们的预测 (prediction)。神经网络的目的是拟合一个函数 f*:features -> prediction。在训练期间,通过减小 prediction 和实际 label 的差异的这种方式,来更改网络参数,使当前的网络能逼近于理想的函数 f*。
神经元(Neural Cell)
神经网络层的基本组成成员为神经元,神经元包含两部分,一部分是上一层网络输出和当前网络层参数的一个线性乘积,另外一部分是线性乘积的非线性转换。(如果缺少非线性转换,则多层线性乘积可以转化为一层的线性乘积)
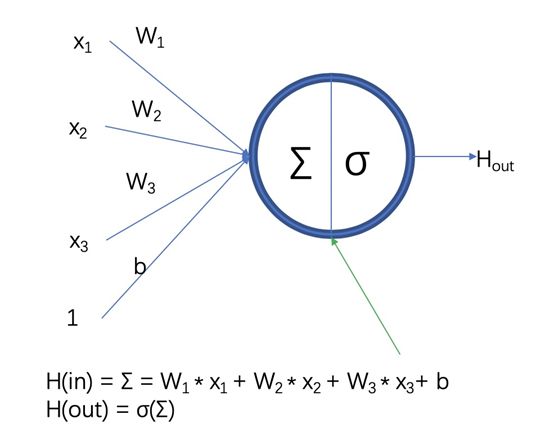
图一
浅层神经网络( Neural Network )
只有一层隐藏层的,我们称为浅层网络。

图二
深度学习网络(Multilayer Perceptron)
相对于浅层网络结构,有两层、三层及以上隐藏层的我们就可以称为深度网络。

图三
在通常的理解中,一个足够宽的网络,是能够拟合任何函数的。而一个深层网络,则能够用更少的参数来拟合该函数,因为深层的神经元可以获取比浅层神经元更复杂的特征表示。
在图二及三所示网络,我们称为全连接网络,也就是隐藏层的神经元会和上一层所有的神经元输出相关。和全连接网络相对应的,是只和上一层部分神经元输出连接的网络,如下文介绍的卷积网络。
卷积网络(CNN)
卷积网络神经元只和上一层的部分神经元输出是连接的。(在直觉上,是因为人的视觉神经元触突只对局部信息敏感,而不是全局所有信息都对同一个触突产生等价作用)

同一个卷积核从左到右,从上到下和输入做乘积,得到了不同强度的输出。从直觉上来理解,卷积核对原始数据的不同数据分布的敏感度是不一样的。如果把卷积核理解为是某种 pattern,那么符合这种 pattern 的数据分布会得到比较强的输出,而不符合这种 pattern 的输出则得到弱的,甚至是不输出。

一个卷积核是一个 pattern 提取器, 多个卷积核就是多个 pattern 提取器。通过多个特征提取器对原始数据做特征提取转换,就构成了一层卷积。

Alex Net, 因为 GPU 内存的原因,Alex 使用了两块 GPU 对模型做了切割,本质上的卷积层是用于特征提取, 最大池化层用于提取强特征及减少参数,全连接层则是所有高级特征参与到最后分类决策中去。
循环神经网络(RNN)
CNN是对空间上特征的提取, RNN则是对时序上特征的提取。

在RNN中,x1 , x2, x3, xt 是在时序上不一样的输入,而 V, U, W 三个矩阵则是共享。同时 RNN 网络中保存了自己的状态 S。 S 随着输入而改变,不同的输入/不同时刻的输入或多或少影响 RNN 网络的状态 S。而 RNN 网络的状态 S 则决定最后的输出。
在直觉上,我们理解 RNN 网络是一个可模拟任何函数的一个神经网络( action ),加上同时有一份自己的历史存储( memory ),action+memory 两者让 RNN 成为了一个图灵机器。
长短期记忆网络( LSTM )
RNN 的问题是非线性操作 σ 的存在且每一步间通过连乘操作传递,会导致长序列历史信息不能很好的传递到最后,而有了 LSTM 网络。

在 lstmcell 中, 包含了通常意义上的遗忘门(点乘,决定什么要从状态中去除),输入更新门(按位相加,决定什么要添加到状态中去),输出门(点乘,决定状态的输出是什么?)虽然看起来很复杂,本质上是矩阵的运算。
为了简化运算,后面有 lstm 的变种 GRU, 如下图:

文本卷积网络 (TextCNN)
CNN 在计算机识别领域中应用广泛,其捕捉局部特征的能力非常强,为分析和利用图像数据的研究者提供了极大的帮助。TextCNN 是2014年 Kim 在 EMNLP 上提出将 CNN 应用于 NLP 的文本分类任务中。
从直观上理解,TextCNN 通过一维卷积来获取句子中 n-gram 的特征表示。TextCNN 对文本浅层特征的抽取能力很强,在短文本领域如搜索、对话领域专注于意图分类时效果很好,应用广泛,且速度快,一般是首选;对长文本领域,TextCNN 主要靠 filter 窗口抽取特征,在长距离建模方面能力受限,且对语序不敏感。

卷积核( filter )→ n-gram 特征
文本卷积与图像卷积的不同之处在于只在文本序列的一个方向做卷积。对句子单词每个可能的窗口做卷积操作得到特征图( feature map )。

其中, 。对 feature map 做最大池化( max-pooling )操作,取中最大值max{c} 作为 filter 提取出的 feature。通过选择每个 feature map 的最大值,可捕获其最重要的特征。
。对 feature map 做最大池化( max-pooling )操作,取中最大值max{c} 作为 filter 提取出的 feature。通过选择每个 feature map 的最大值,可捕获其最重要的特征。
每个 filter 卷积核产生一个 feature ,一个 TextCNN 网络包括很多不同窗口大小的卷积核,如常用的 filter size ∈{3,4,5} 每个 filter 的 featuremaps=100。
增强序列推理模型(ESIM)
ESIM (Enhanced Sequential Inference Model) 为短文本匹配任务中常用且有力的模型。它对于 LSTM 的加强主要在于:将输入的两个 LSTM 层( Encoding Layer) 通过序列推理交互模型输出成新的表征。

图片来源:paper《Enhanced LSTM for Natural LanguageInference》
如图所示,ESIM 为图的左边部分。整体网络结构其实比较明确,整条通路大致包括三个步骤。
步骤一:编码层。 该步骤每个 token 将预训练的编码通过 Bi-LSTM 层,从而获取了“新的编码”,其目的是通过 LSTM 学习每个 token 的上下文信息。
步骤二:局部推理层。 步骤二本质是一个句间注意力( intra-sentence attention )的计算过程。通过将两句在步骤一中获取的结果做 intra-sentence attention 操作,我们在这里可以获取到一个新的向量表征。接下来对向量的前后变化进行了计算,该做法的目的是进一步抽取局部推理信息在 attention 操作的前后变化,并捕捉其中的一些推理关系,如前后关系等。
步骤三:组合推理&预测层。 再次将抽取后的结果通过 Bi-LSTM,并使用Avarage&Maxpooling 进行池化(其具体操作就是分别进行 average 和 max pooling 并进行 concat),最后加上全连接层进行 Softmax 预测其概率。
ELMo
直观上来讲,ELMo(Embedding from Language Model) 解决了一词多义的问题, 例如询问“苹果”的词向量是什么,ELMo 会考虑是什么语境下的“苹果”,我们应该去询问“苹果股价”里的“苹果”词向量是什么。ELMo 通过提供词级别、携带上下文信息的动态表示,能有效的捕捉语境信息。ELMo 的提出对后面的的 GPT 和 BRET有一个很好的引导和启发的作用。一个好的词向量,应满足两个特点:
- 能够反映出语义和语法的复杂特征。
- 能够准确对不同上下文产生合适语义。
传统的 word2vec 对每个 word 只有一个固定的 embedding 表达,不能产生携带上下文信息的 embedding,对多义词无法结合语境判断。ELMo 中的每个单词都要先结合语境通过多层 LSTM 网络才得到最后的表达,LSTM 是为捕获上下文信息而生,因而 ELMo 能结合更多的上下文语境,在一词多意上的效果比 word2vec 要好。
ELMo 预训练时的网络结构图与传统语言模型有点类似,直观理解为将中间的非线性层换成了 LSTM,利用 LSTM 网络更好的提取每个单词在当前语境中的上下文信息,同时增加了前向和后向上下文信息。.
-
一文读懂单灯控制器工作原理2024-11-11 3096
-
一文读懂MSA(测量系统分析)2024-11-01 2708
-
一文读懂车规级AEC-Q认证2023-12-04 2501
-
一文读懂微力扭转试验机的优势2023-11-30 1624
-
一文读懂,什么是BLE?2023-11-27 5201
-
一文读懂何为深度学习22023-02-22 888
-
读懂深度学习,走进“深度学习+”阶段2023-01-14 2060
-
一文读懂中断方式和轮询操作有什么区别吗2021-12-10 2809
-
一文读懂MCU的特点、功能及如何编写2021-12-05 1446
-
一文读懂什么是NEC协议2021-10-15 2743
-
一文读懂如何去优化AC耦合电容?2021-06-08 3765
-
一文读懂接口模块的组合应用有哪些?2021-05-17 2516
-
一文读懂NB-IoT 的现状、挑战和前景2020-02-28 8025
-
一文读懂深度学习与机器学习的差异2017-11-16 3655
全部0条评论

快来发表一下你的评论吧 !
