

一文读懂何为深度学习2
人工智能
描述
预训练
给定包含 N 个词的序列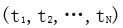 ,前向语言模型通过前 k-1个词预测第 k 个词
,前向语言模型通过前 k-1个词预测第 k 个词 。在第 k 个位置,每个 LSTM 层输出上下文依赖的向量表达
。在第 k 个位置,每个 LSTM 层输出上下文依赖的向量表达  , j=1,2,…,L。顶层 LSTM 层的输出 利用交叉熵损失预测下一个位置
, j=1,2,…,L。顶层 LSTM 层的输出 利用交叉熵损失预测下一个位置 。
。

后向语言模型对序列做反序,利用下文的信息去预测上文的词。与前向类似,给定 经过 L 层的后向深层 LSTM 网络预测得到第 j 层的隐层输出
经过 L 层的后向深层 LSTM 网络预测得到第 j 层的隐层输出 。
。

双向语言模型拼接前向语言模型和后向语言模型,构建前向和后向联合最大对数似然。

其中, 为序列词向量层参数,
为序列词向量层参数, 为交叉熵层参数,在训练过程中这两部分参数共享。
为交叉熵层参数,在训练过程中这两部分参数共享。
嵌入式语言模型组合利用多层 LSTM 层的内部信息,对中心词,一个 L 层的双向语言模型计算得到 2L+1 个表达集合。

Fine-tune
在下游任务中,ELMo 将多层的输出整合成一个向量,将所有 LSTM 层的输出加上normalized 的 softmax 学习到的权重 s=Softmax(w),使用方法如下所示:

直观上来讲,biLMs 的较高层次的 LSTM 向量抓住的是词汇的语义信息, biLMs 的较低层次的 LSTM 向量抓住的是词汇的语法信息。这种深度模型所带来的分层效果使得将一套词向量应用于不同任务有了可能性,因为每个任务所需要的信息量是不同的。另外 LSTM 的层数不宜过多,多层 LSTM 网络不是很容易 train 好,存在过拟合问题。如下图是一个多层 LSTM 用在文本分类问题的实验结果,随着 LSTM 层数增多,模型效果先增加后下降。

Transformer
曾经有人说,想要提升 LSTM 效果只要加一个 attention 就可以。但是现在attention is all you need。Transformer 解决了 NLP 领域深层网络的训练问题。
Attention 此前就被用于众多 NLP 的任务,用于定位关键 token 或者特征,比如在文本分类的最后加一层 Attention 来提高性能。Transformer 起源自注意力机制(Attention),完全抛弃了传统的 RNN,整个网络结构完全是由 Attention 机制组成。Transformer 可以通过堆叠 Transformer Layer 进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的 Encoder-Decoder,并在机器翻译中取得了 BLEU 值的新高。
整个流程的可视化如图:以N=2示例,实际Transformer的N=6。
Encoder 阶段: 输入“Thinking Machines”,对应词向量,叠加位置向量 Positional Encoding,对每个位置做 Self-Attention 得到;Add&Norm 分两步,residual connection即,layer Normalization 得到新的,对每个位置分别做 feed forward 全连接和 Add&Norm,得到一个 Encoder Layer 的输出,重复堆叠2次,最后将 Encoder Layer 输出到 Decoder 的 Encoder-Decoder Layer 层。

Decoder 阶段:先是对 Decoder 的输入做 Masked Self-Attention Layer,然后将Encoder 阶段的输出与 Decoder 第一级的输出做 Encoder-Decoder Attention,最后接 FFN 全连接,堆叠2个 Decoder,最后接全连接+Softmax 输出当前位置概率最大的的词。

Transformer 的结构上比较好理解,主要是里边的细节比较多,如 Mult-HeadAttention, Feed Forward, Layer Norm, Positional Encoding等。
Transformer的优点:
- 并行计算,提高训练速度。 这是相比 LSTM 很大的突破,LSTM 在训练的时候 ,当前步的计算要依赖于上一步的隐状态,这是一个连续过程,每次计算都需要等之前的计算完成才能展开,限制模型并行能力。而 Transformer 不用LSTM结构,Attention 机制的每一步计算只是依赖上一层的输出,并不依赖上一词的信息,因而词与词之间是可以并行的,从而训练时可以并行计算, 提高训练速度。
- 一步到位的全局联系捕捉。 顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM 依旧无能为力。Transformer 使用了 Attention 机制,从而将序列中的任意两个位置之间的距离是缩小为1,这对解决 NLP 中棘手的长期依赖问题是非常有效的。
总结对比CNN、RNN和Self-Attention:
CNN: 只能看到局部领域,适合图像,因为在图像上抽象更高层信息仅仅需要下一层特征的局部区域,文本的话强在抽取局部特征,因而更适合短文本。
RNN: 理论上能看到所有历史,适合文本,但是存在梯度消失问题。
Self-Attention: 相比 RNN 不存在梯度消失问题。对比 CNN 更加适合长文本,因为能够看到更远距离的信息,CNN 叠高多层之后可以看到很远的地方,但是 CNN本来需要很多层才能完成的抽象,Self-Attention 在很底层就可以做到,这无疑是非常巨大的优势。
BERT
BERT (Bidirectional Encoder Representations from Transformers) 本质来讲是NLP 领域最底层的语言模型,通过海量语料预训练,得到序列当前最全面的局部和全局特征表示。
BERT 网络结构如下所示,BERT 与 Transformer 的 Encoder 网络结构完全相同。假设 Embedding 向量的维度是,输入序列包含 n 个token,则 BERT 模型一个layer 的输入是一个的矩阵,而它的输出也同样是一个的矩阵,所以这样 N 层 BERT layer 就可以很方便的首尾串联起来。BERT 的 large model 使用了 N=24 层这样的Transformer block。

-
一文读懂单灯控制器工作原理2024-11-11 2941
-
一文读懂MSA(测量系统分析)2024-11-01 2577
-
一文读懂车规级AEC-Q认证2023-12-04 2355
-
一文读懂微力扭转试验机的优势2023-11-30 1538
-
一文读懂,什么是BLE?2023-11-27 5038
-
一文读懂何为深度学习12023-02-22 1007
-
读懂深度学习,走进“深度学习+”阶段2023-01-14 1957
-
一文读懂中断方式和轮询操作有什么区别吗2021-12-10 2791
-
一文读懂MCU的特点、功能及如何编写2021-12-05 1411
-
一文读懂什么是NEC协议2021-10-15 2720
-
一文读懂如何去优化AC耦合电容?2021-06-08 3731
-
一文读懂接口模块的组合应用有哪些?2021-05-17 2484
-
一文读懂NB-IoT 的现状、挑战和前景2020-02-28 7853
-
一文读懂深度学习与机器学习的差异2017-11-16 3588
全部0条评论

快来发表一下你的评论吧 !
