

NLP入门之Bert的前世今生
人工智能
描述
引言
之前的文章和大家详细的介绍了静态的词向量表示word2vec理论加实战,但是word2vec存在一个很大的问题,由于是静态词向量所以无法表示一词多义,对于每个词只能有一个固定的向量表示,今天我们来介绍一个给NLP领域带来革新的预训练语言大模型Bert,对比word2vec和Glove词向量模型,Bert是一个动态的词向量语言模型,接下来将带领大家一起来聊聊Bert的前世今生,感受一下Bert在自然语言处理领域的魅力吧。
1 预训练的演化史
NLP里面的Word Embedding预训练技术的演化史,从最初的静态词向量word2vec,到动态预训练词向量ELMO和GPT,再到今天的主角Bert预训练模型,这个演变过程也是整个NLP技术的发展历程,Bert的横空问世直接刷新了NLP领域11项基本任务的最佳成绩,成为最受NLP算法工程师青睐的算法模型。

文章参考论文地址:https://arxiv.org/pdf/1810.04805.pdf
1.1 onehot编码
one-hot编码顾名思义,又称为独热编码表示,之前的文章中有对onehot词向量做详细的介绍:
【NLP修炼系列之词向量(一)】详解one-hot编码&实战
1.2 word2vec词向量
word2vec是一种静态的词向量表示,word2vec存在最大的问题就是由于它是静态词向量表示导致不能表示一词多义的情况,之前的文章有对word2vec原理和实战做详解,想了解的小伙伴可以回顾一下:
1.3 ELMO预训练模型
对比word2vec静态词向量的缺点,为了解决这种静态词向量一词多义问题,2018年NAACL上发表了paper《Deep contextualized word representations》提出了ELMO预训练语言模型。
ELMO模型结构:
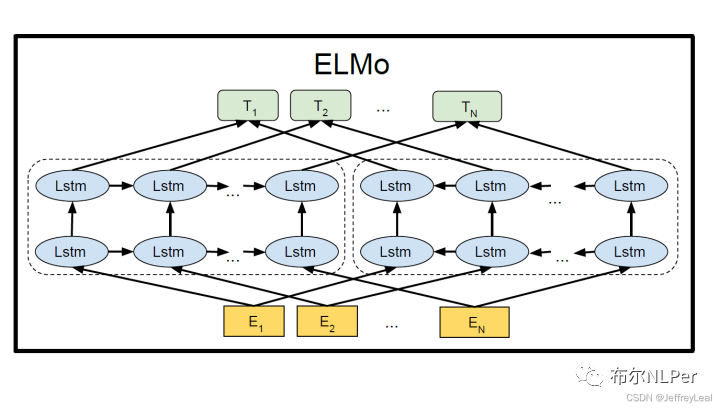
ELMO的核心思想:使用两层BiLSTM模型来学习文本深度学习层次表示,最后针对每个单词输出三个向量,针对于下游任务可以使用加权的方式来表征文本,一定程度上解决了一词多义的问题。
1.4 GPT预训练模型
GPT的全称是"Generative Pre-Traingng Transformer"的简称,是一个生成式预训练模型,由论文《Deep contextualized word representations》提出。
参考论文地址:https://arxiv.org/pdf/1802.05365.pdf
GPT模型结构图:
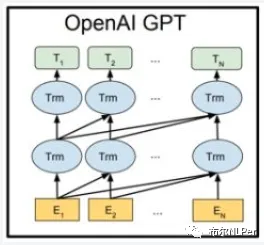
GPT的核心思想:通过二段式的训练,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。
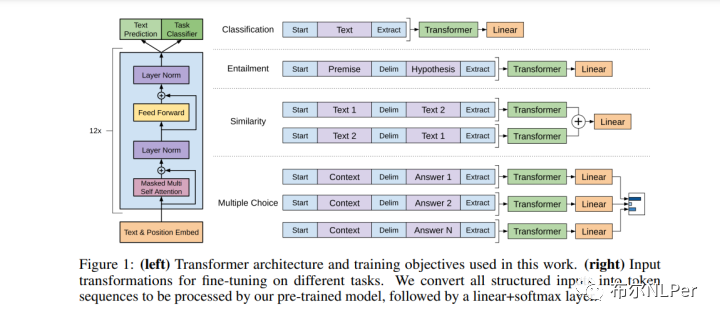
图(左)文章中使用的 Transformer 架构和训练目标。 (右)用于微调不同任务的输入转换,将所有结构化输入转换为令牌序列,由预训练模型处理,然后是线性+softmax 层。
GPT和ELMO模型一样都是两阶段的预训练模型,但是不同的是,GPT特征抽取器不是用的RNN,而是用的transformer,它的特征抽取能力要强于RNN,其次GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是自回归模型,单向的transformer结构,只会根据上文信息来表示Word Embedding,是一个生成式模型。
1.4 Bert预训练模型
BERT和ELMO、GPT有密切关系,三者直接有着共同点和不同点,先给出模型结构,后面我们详细的介绍一下今天的主角Bert预训练语言模型。
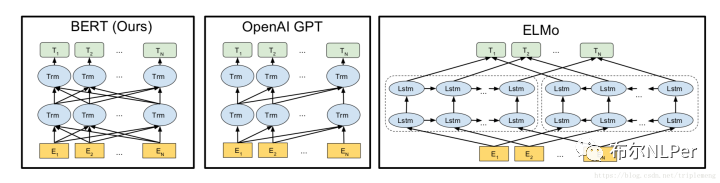
总结一下预训练的几个演变模型的关系:
one-hot编码是离散的向量表示,离散编码存在诸多的问题,例如无法衡量相似数据之间的相似关系等。
word2vec是静态的的词向量表示,静态词向量之前也说明了存在着很多的问题,其中最大的缺点就是不能解决一词多义的问题。
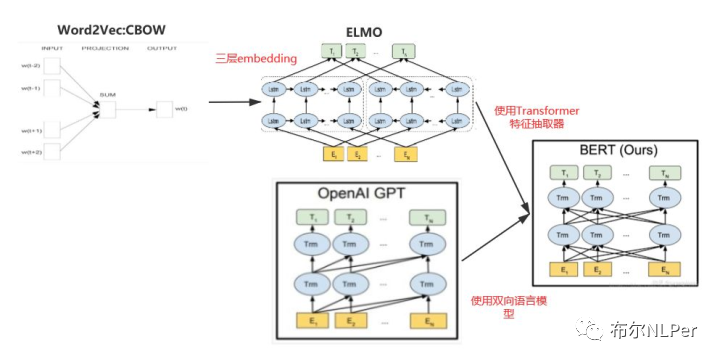
相比较word2vec而言ELMO,Bert,GPT都是动态的词向量表示,其中ELMO不仅使用了词向量表示词,还加入了句法特征向量和语义特征向量三层embedding组合来表示词,ELMO主要特点是使用了LSTM的特征提取器,自左到右和自右到左双向的使用上下文来语义表示,如果ELMO将LSTM改成Transformer特征提取器就变成了Bert结构了。
GPT使用的特征提取器是Transformer,但是是自左到右单向仅仅使用上文语义的自回归生成模型,如果GPT也是使用自左到右和自右到左的双向提取上下文语义就变成了Bert结构了。
那么这么看来Bert的结构就比较清晰了,Bert综合了以上左右模型的“优点”吧,动态的词向量语义表示,使用了强大的Transformer特征提取器,同时是自左到右和自右到左双向的使用上下文来语义表示,可以说Bert是集大成者。
2 Bert概述
Bert全称是“Bidirectional Encoder Representations from Transformers”,Bert是一种预训练语言模型(pre-trained language model, PLM)。Google团队在2018年发表文章《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》提出了Bert预训练语言模型,可以说Bert的出现轰动了整个NLP领域,自然语言处理领域开始进入一个新的阶段。
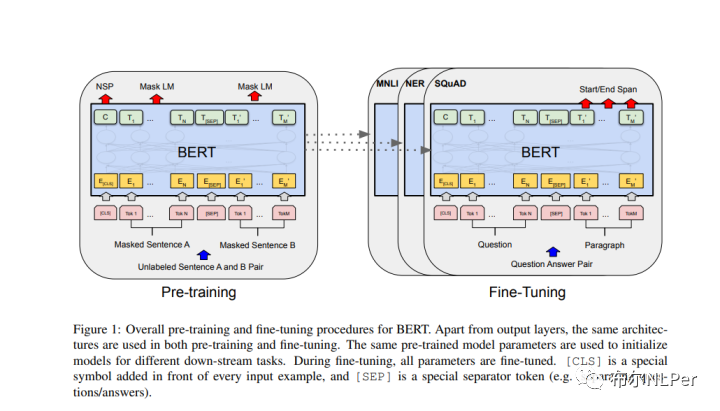
Bert和ELMO,GPT都一样是两阶段的任务(预训练+微调):
预训练阶段(pre-training):模型将使用大量的无标签数据训练。
微调阶段(fine-tuning):BERT模型将用预训练模型初始化所有参数,这些参数将针对于下游任务,比如文本分类,序列标注任务等,微调阶段需要使用有标签的数据进行模型训练,不同的下游任务可以训练出不同的模型,但是每次都会使用同一个预训练模型进行初始化。
2.1 BERT的结构
Bert是基于Transformer实现的,主要是Transformer的Encoder部分,完整架构如下:
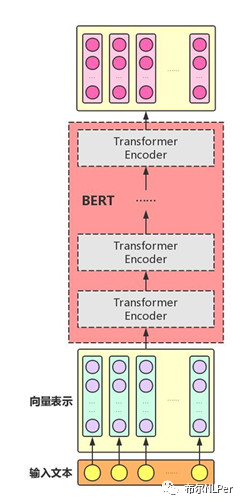
论文中提到的Bert主要有两种大小,bert-base和bert-large两个size,base版一共有110M参数,large版有340M的参数,总之Bert有上亿的参数量。
BERT_BASE: L = 12, H = 768, A = 12, Total Parameters = 110M.
BERT_LARGE: L = 24, H = 1024, A = 16, Total Parameters = 340M.
其中 L:Transformer blocks 层数;H:hidden size;A:the number of self-attention heads
2.2 Bert的输入输出形式
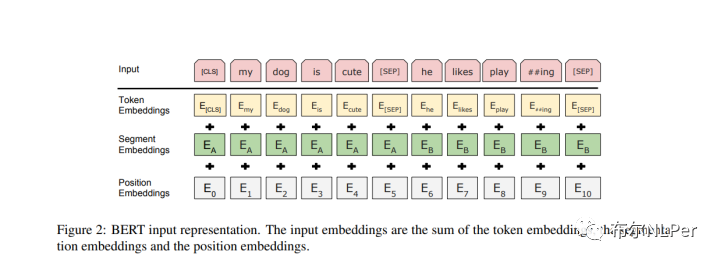
Bert的Embedding层由3个子层求和得到,分别是词向量层Token Embedings,句子层Segment Embeddings以及位置编码层Position Embeddings。
Embedding的组成:
Token Embeddings字向量: 用来表征不同的词,以及特殊的tokens,第一个单词是CLS标志,主要用于之后的分类任务。
Segment Embeddings文本向量: 用来区别两个句子,来表征这个词是属于哪一个句子,作用于两个句子为输入的分类任务。
Position Embeddings位置向量: 由于出现在文本不同位置的字/词所携带的语义信息存在差异,对不同位置的字/词分别附加一个不同的向量以作区分,是随机初始化训练出来的结果。
Bert输出:
主要输出各字对应的融合全文语义信息后的向量表示。
3 Bert的预训练方式
预训练:预训练是通过大量无标注的语言文本进行语言模型的训练,得到一套模型参数,利用这套参数对模型进行初始化,再根据具体任务在现有语言模型的基础上进行精调。
预训练主要分为两大分支,一支是自编码语言模型(Autoencoder Language Model),自回归语言模型(Autoregressive Language Model)。
自回归语言模型: 是根据上文内容预测下一个可能的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词。GPT 就是典型的自回归语言模型。
自编码语言模型: 是对输入的句子随机Mask其中的单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,那些被Mask掉的单词就是在输入侧加入的噪音。BERT就是典型的自编码类语言模型。
3.1 MLM掩码语言模型(Mask Language Model)
因为Bert就是采用自编码的预训练模型,MLM就是我们理解的完形填空的问题,随机掩盖掉每一个句子中15%的词,用其上下文来去预测掩盖的词,但是在下游任务做微调的过程中不会出现mask情况,为了解决这一问题论文中提到了一些替换策略:
80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的时间保持不变,my dog is hairy -> my dog is hairy
3.2 NSP预训练任务 (Next Sentence Prediction)
NSP任务主要是判断两个句子的关系,判断两个句子是否是前后句关系,然后用一些特殊的tokens做区分(在句子开头加一个 [CLS],在两句话之间和句末加 [SEP])。输入形式是,开头是一个特殊符号[CLS],然后两个句子之间用[SEP]隔断。
正样例:50%的句子B是真是的A后面的句子。
负样例:50%的句子B是从语料中随机选取的句子。
4 Bert的微调
Bert的4个经典任务:句子(文本)对匹配、句子(文本)分类、问答系统、序列标注。
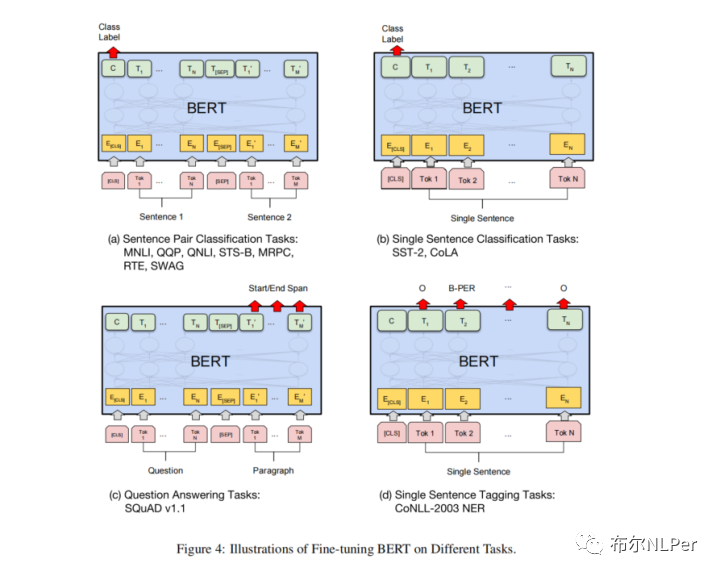
(1)句对分类(Sentence Pair Classification tasks)
预测下一句、语义相似度等任务,输入是两个句子A和B,中间用[SEP]分隔,最终得到的class label就表示是否下一句或者是否是语义相似的。
(2)单句分类(Single Sentence Classification tasks)
文本分类、情感分析等。输入就是一个单独的句子,最终的class label就是表示句子属于哪一类。
(3)文本问答(Question Answering tasks)
问答任务,输入是一个问题和问题对应的段落,用[SEP]分隔,这里输出的结果就不是某个class label而是答案在给定段落的开始和终止位置,主要用于阅读理解任务。
(4)序列标注任务(Single Sentence Tagging Tasks)
常见的命名实体识别任务,输入就是一个单独的句子,输出是句子中每个token对应的类别标注。
5 总结
Bert模型取得这么惊人的效果的前提是用到了强大的Transformer特征提取器,其次是用到了双向的上下文语义表示,BERT之后衍生了各类改进版BERT,其中改善训练方式、优化模型结构、模型小型化等方法去优化Bert,比较典型的有Roberta,AlBert,distilBert等更好,更快,更小的模型。
-
蓝牙技术的前世今生2023-05-09 4367
-
芯片开源架构RISC-V的前世今生2020-05-21 3667
-
芯片春秋——ARM前世今生2020-05-25 2330
-
嵌入式ARM开发的前世今生,看完你就懂了2021-04-20 1849
-
关于汽车操作系统的前世今生看完你就懂了2021-09-26 2037
-
汽车总线前世今生2017-01-24 1055
-
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍2018-06-10 79071
-
六张图看懂人工智能的前世今生2018-08-25 5074
-
初探工业互联网的前世今生2018-12-13 3981
-
MiniLED背光的前世今生2019-07-08 10372
-
人工智能的前世今生2020-12-10 4706
-
高压电源创新:前世今生2022-11-03 821
-
电池管理技术的前世今生2022-11-04 756
-
带你探索吹风筒的前世今生【其利天下高速风筒方案开发】2023-11-02 5819
-
二极管的前世今生2023-12-14 2750
全部0条评论

快来发表一下你的评论吧 !
